Seata事务隔离
本文目标:帮助用户明白使用Seata AT模式时,该如何正确实现事务隔离,防止脏读脏写。
希望读者在阅读本文前,已阅读过seata官网中对AT模式的介绍,并且对数据库本地锁有所了解
(例如,两个事务同时在对同一条记录做update时,只有拿到record lock的事务才能更新成功,另一个事务在record lock未释放前只能等待,直到事务超时)
首先请看这样的一段代码,尽管看着“初级”,但持久层框架实际上帮我们做的主要事情也就这样。
@Service
public class StorageService {
@Autowired
private DataSource dataSource;
@GlobalTransactional
public void batchUpdate() throws SQLException {
Connection connection = null;
PreparedStatement preparedStatement = null;
try {
connection = dataSource.getConnection();
connection.setAutoCommit(false);
String sql = "update storage_tbl set count = ?" +
" where id = ? and commodity_code = ?";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 100);
preparedStatement.setLong(2, 1);
preparedStatement.setString(3, "2001");
preparedStatement.executeUpdate();
connection.commit();
} catch (Exception e) {
throw e;
} finally {
IOutils.close(preparedStatement);
IOutils.close(connection);
}
}
}
从代理数据源说起
使用AT模式,最重要的事情便是代理数据源,那么用DataSourceProxy代理数据源有什么作用呢?
DataSourceProxy能帮助我们获得几个重要的代理对象
-
通过
DataSourceProxy.getConnection()获得ConnectionProxy -
通过
ConnectionProxy.prepareStatement(...)获得StatementProxy
Seata的如何实现事务隔离,就藏在这2个Proxy中,我先概述下实现逻辑。
StatementProxy.executeXXX()的处理逻辑
-
当调用
io.seata.rm.datasource.StatementProxy.executeXXX()会将sql交给io.seata.rm.datasource.exec.ExecuteTemplate.execute(...)处理。ExecuteTemplate.execute(...)方法中,Seata根据不同dbType和sql语句类型使用不同的Executer,调用io.seata.rm.datasource.exec.Executer类的execute(Object... args)。- 如果选了DML类型Executer,主要做了以下事情:
- 查询前镜像(select for update,因此此时获得本地锁)
- 执行业务sql
- 查询后镜像
- 准备undoLog
- 如果你的sql是select for update则会使用
SelectForUpdateExecutor(Seata代理了select for update),代理后处理的逻辑�是这样的:- 先执行 select for update(获取数据库本地锁)
- 如果处于
@GlobalTransactionalor@GlobalLock,检查是否有全局锁 - 如果有全局锁,则未开启本地事务下会rollback本地事务,再重新争抢本地锁和全局锁,以此类推,除非拿到全局锁
ConnectionProxy.commit()的处理逻辑
- 处于全局事务中(即,数据持久化方法带有
@GlobalTransactional)- 注册分支事务,获取全局锁
- undoLog数据入库
- 让数据库commit本次事务
- 处于
@GlobalLock中(即,数据持久化方法带有@GlobalLock)- 向tc查询是否有全局锁存在,如存在,则抛出异常
- 让数据库commit本次事务
- 除了以上情况(
else分支)- 让数据库commit本次事务
@GlobalTransactional的作用
标识一个全局事务
@GlobalLock + select for update的作用
如果像updateA()方法带有@GlobalLock + select for update,Seata在处理时,会先获取数据库本地锁,然后查询该记录是否有全局锁存在,若有,则抛出LockConflictException。
先举一个脏写的例子,再来看Seata如何防止脏写
假设你的业务代码是这样的:
updateAll()用来同时更新A和B表记录,updateA()updateB()则分别更新A、B表记录updateAll()已经加上了@GlobalTransactional
class YourBussinessService {
DbServiceA serviceA;
DbServiceB serviceB;
@GlobalTransactional
public boolean updateAll(DTO dto) {
serviceA.update(dto.getA());
serviceB.update(dto.getB());
}
public boolean updateA(DTO dto) {
serviceA.update(dto.getA());
}
}
class DbServiceA {
@Transactional
public boolean update(A a) {
}
}
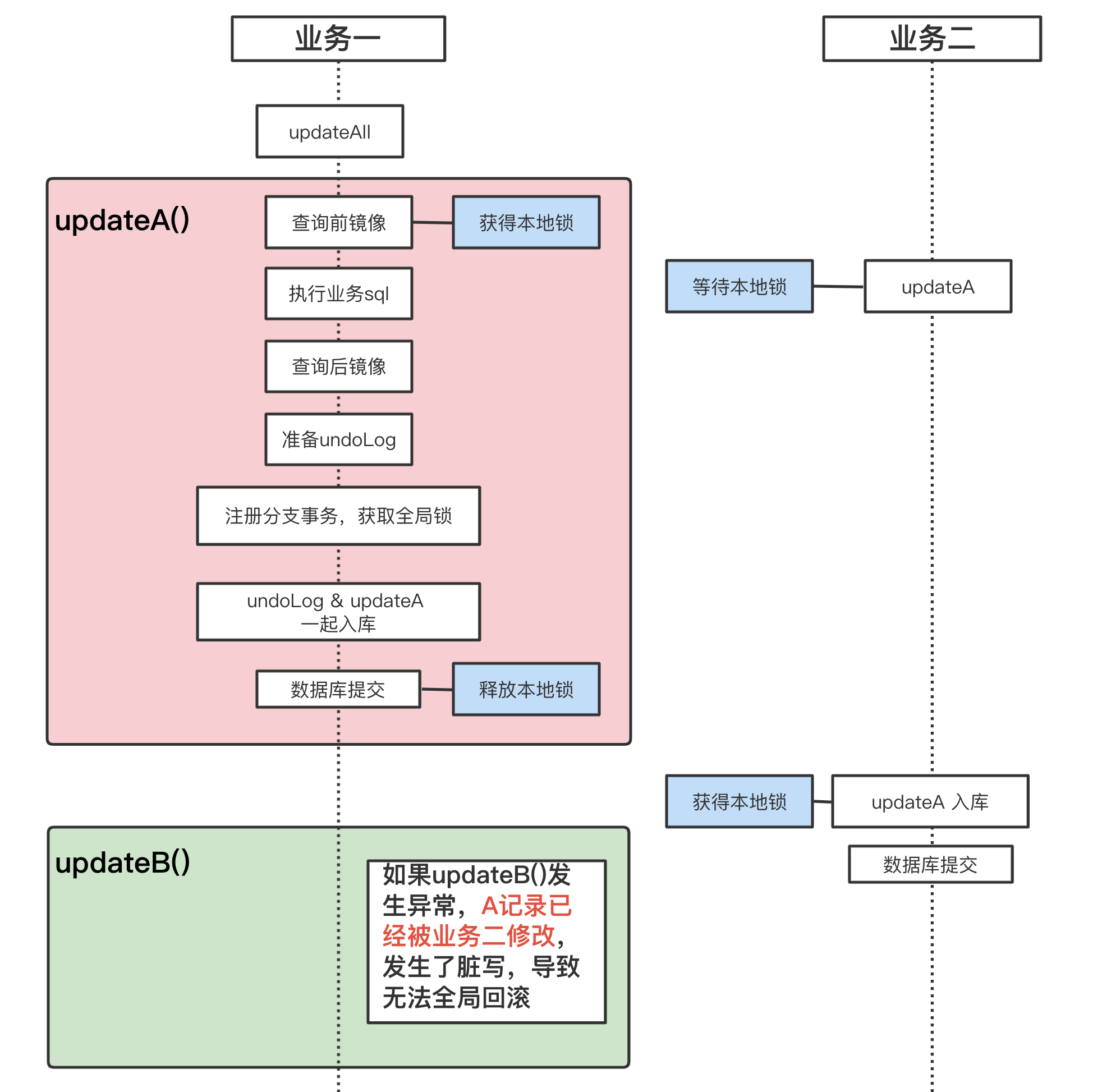 |
|
怎么用Seata防止脏写?
办法一:updateA()也加上@GlobalTransactional,此时Seata会如何保证事务隔离?
class DbServiceA {
@GlobalTransactional
@Transactional
public boolean updateA(DTO dto) {
serviceA.update(dto.getA());
}
}
updateAll()先被调用(未完成),updateA()后被调用
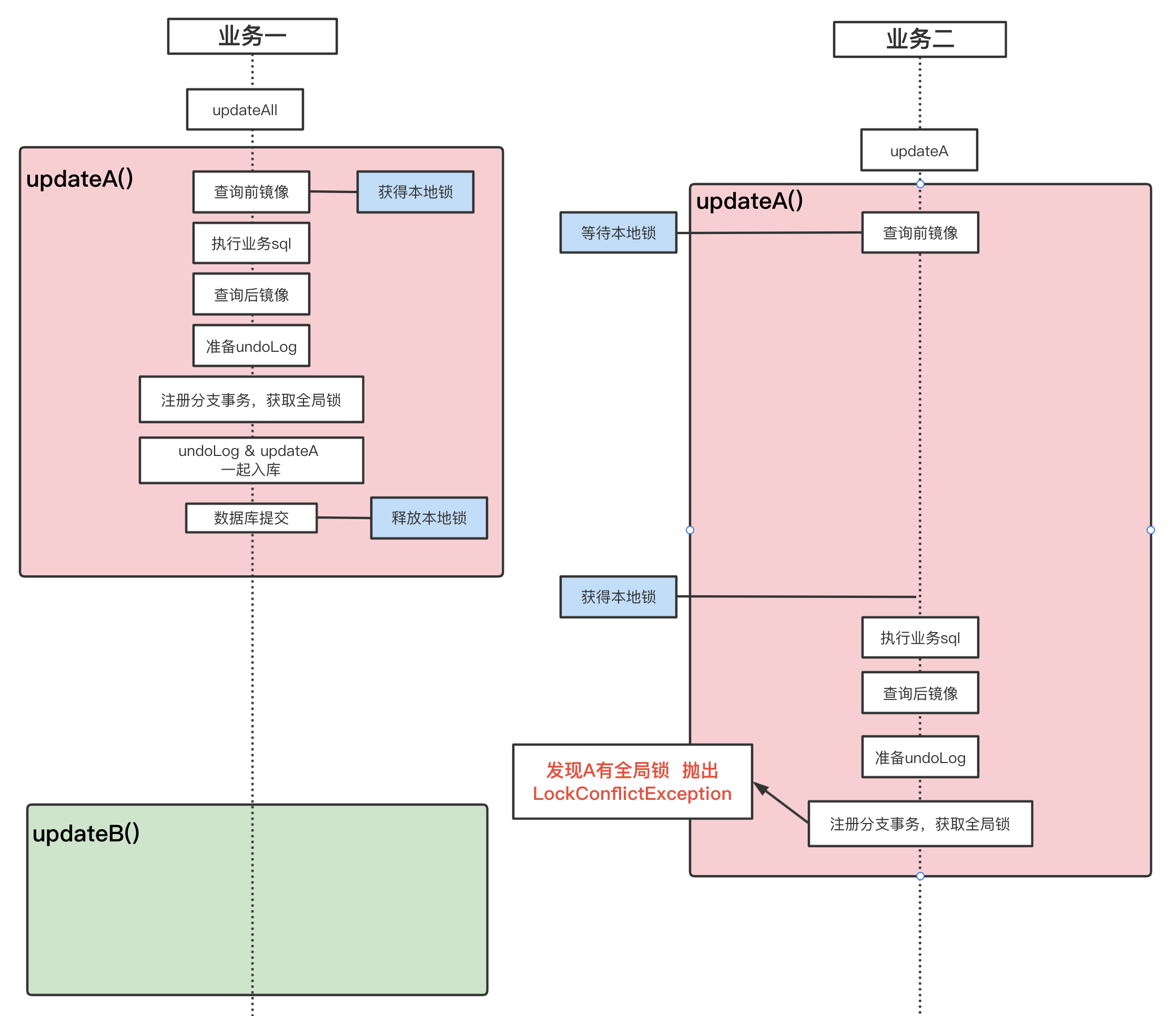
办法二: @GlobalLock + select for update
class DbServiceA {
@GlobalLock
@Transactional
public boolean updateA(DTO dto) {
serviceA.selectForUpdate(dto.getA());
serviceA.update(dto.getA());
}
}
-
updateAll()先被调用(未完成),updateA()后被调用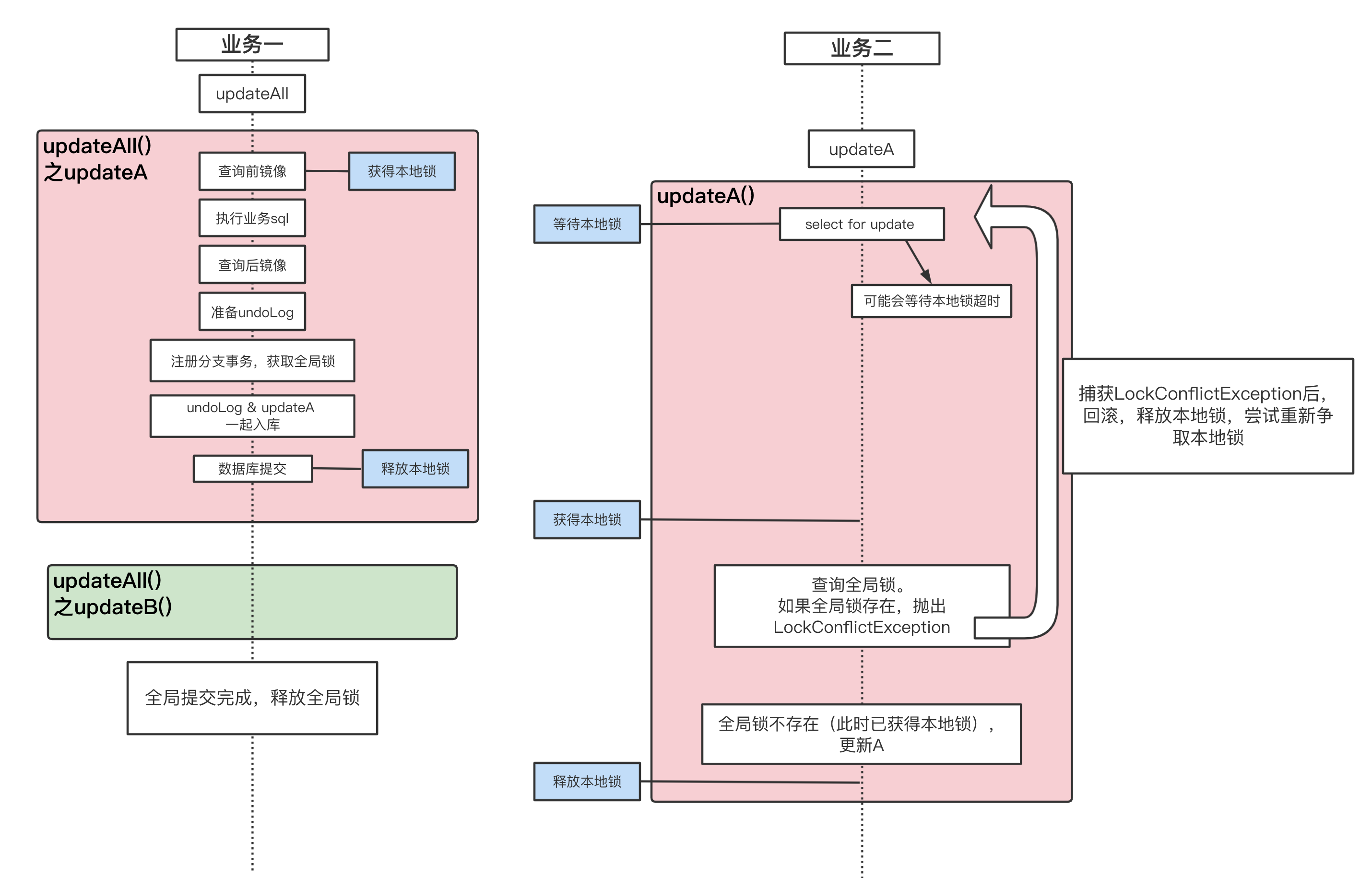
-
那如果是
updateA()先被调用(未完成),updateAll()后被调用呢?
由于2个业务都是要先获得本地锁,因此同样不会发生脏写 -
一定有人会问,“这里为什么要加上select for update? 只用@GlobalLock能不能防止脏写?” 能。但请再回看下上面的图,select for update能带来这么几个好处:
- 锁冲突更“温柔”些。如果只有@GlobalLock,检查到全局锁,则立刻抛出异常,也许再“坚持”那么一下,全局锁就释放了,抛出异常岂不可惜了。
- 在
updateA()中可以通过select for update获得最新的A,接着再做更新。
如何防止脏读?
场景: 某业务先调用updateAll(),updateAll()未执行完成,另一业务后调用queryA()
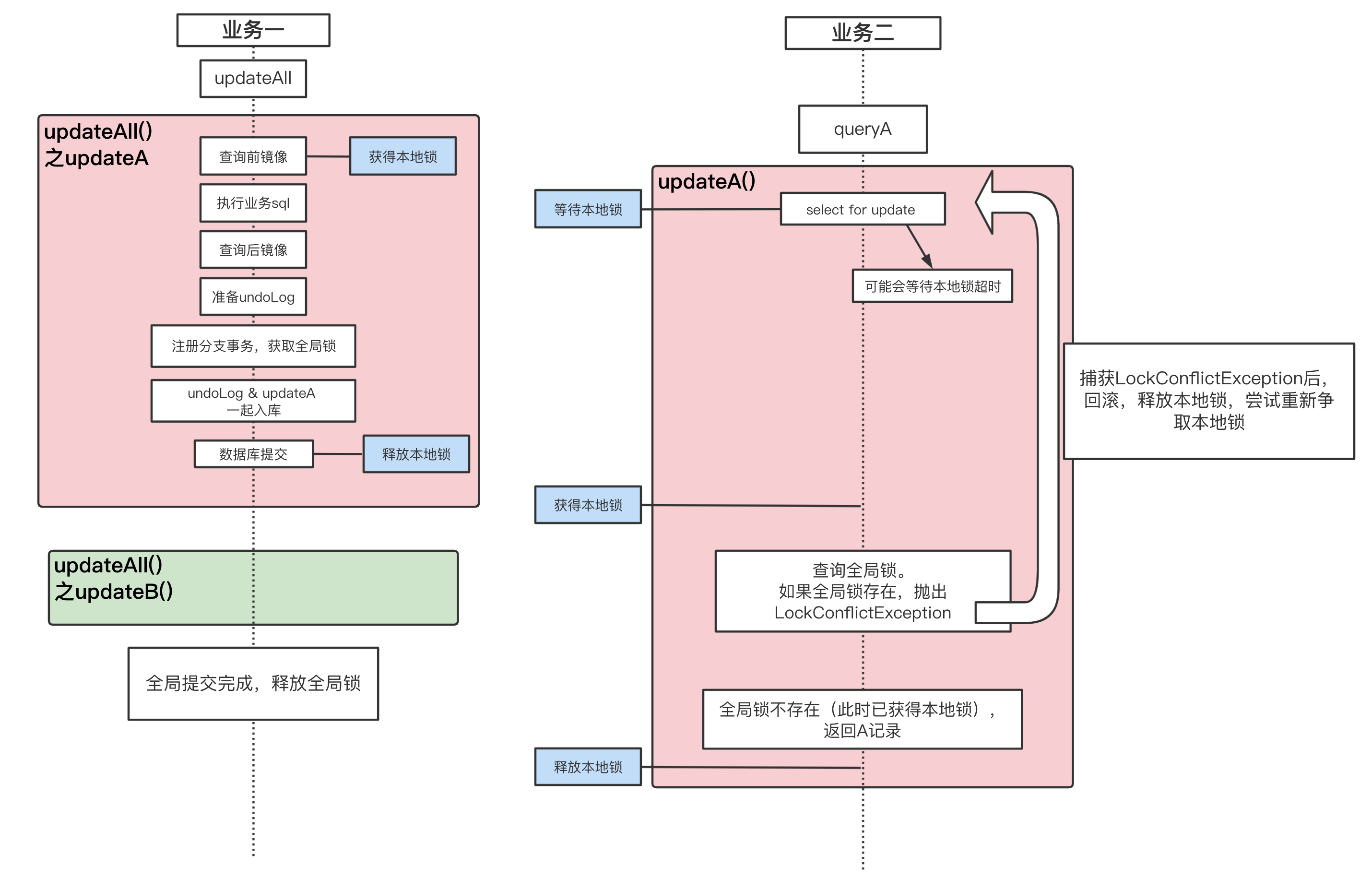
源码展示
@Service
public class StorageService {
@Autowired
private DataSource dataSource;
@GlobalTransactional
public void update() throws SQLException {
Connection connection = null;
PreparedStatement preparedStatement = null;
try {
connection = dataSource.getConnection();
connection.setAutoCommit(false);
String sql = "update storage_tbl set count = ?" +
" where id = ? and commodity_code = ?";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 100);
preparedStatement.setLong(2, 1);
preparedStatement.setString(3, "2001");
preparedStatement.execute();
connection.commit();
} catch (Exception e) {
throw e;
} finally {
IOutils.close(preparedStatement);
IOutils.close(connection);
}
}
}
这段代码虽然看着很初级,没有使用持久层框架,但如果将框架帮我们做的事情抽象出来,其实也就是上面这段代码。
简单说明接下来源码介绍的脉络(主要关注和事务隔离有关的源码)
- 代理数据源的用途
DataSourceProxy的作用(返回ConnectionProxy)- 介绍
ConnectionProxy的一个小功能(存放undolog)
- 介绍
ConnectionProxy的作用(返回StatementProxy)StatementProxy.execute()的处理逻辑io.seata.rm.datasource.exec.UpdateExecutor的执行逻辑(查前镜像、执行sql、查后镜像、准备undoLog)SelectForUpdateExecutor的执行逻辑(争本地锁,查全局锁。有全局锁,回滚,再争...)
ConnectionProxy.commit()的处理逻辑(注册分支事务(争全局锁),写入undoLog,数据库提交)
- 介绍RootContext
GlobalTransactionalInterceptor的不同代理逻辑- 带有
@GlobalTransactional如何处理 - 带有
@GlobalLock如何处理
- 带有
DataSourceProxy的作用
DataSourceProxy帮助我们获得几个重要的代理对象
- 通过
DataSourceProxy.getConnection()获得ConnectionProxypackage io.seata.rm.datasource;
import java.sql.Connection;
public class DataSourceProxy extends AbstractDataSourceProxy implements Resource {
@Override
public ConnectionProxy getConnection() throws SQLException {
Connection targetConnection = targetDataSource.getConnection();
return new ConnectionProxy(this, targetConnection);
}
}- 现在先介绍下
ConnectionProxy中的ConnectionContext,它的有一个功能是存放undoLog。package io.seata.rm.datasource;
import io.seata.rm.datasource.undo.SQLUndoLog;
public class ConnectionProxy extends AbstractConnectionProxy {
private ConnectionContext context = new ConnectionContext();
public void appendUndoLog(SQLUndoLog sqlUndoLog) {
context.appendUndoItem(sqlUndoLog);
}
}package io.seata.rm.datasource;
public class ConnectionContext {
private static final Savepoint DEFAULT_SAVEPOINT = new Savepoint() {
@Override
public int getSavepointId() throws SQLException {
return 0;
}
@Override
public String getSavepointName() throws SQLException {
return "DEFAULT_SEATA_SAVEPOINT";
}
};
private final Map<Savepoint, List<SQLUndoLog>> sqlUndoItemsBuffer = new LinkedHashMap<>();
private Savepoint currentSavepoint = DEFAULT_SAVEPOINT;
void appendUndoItem(SQLUndoLog sqlUndoLog) {
sqlUndoItemsBuffer.computeIfAbsent(currentSavepoint, k -> new ArrayList<>()).add(sqlUndoLog);
}
}
- 现在先介绍下
通过ConnectionProxy.prepareStatement(...)获得StatementProxy
package io.seata.rm.datasource;
public class ConnectionProxy extends AbstractConnectionProxy {
public ConnectionProxy(DataSourceProxy dataSourceProxy, Connection targetConnection) {
super(dataSourceProxy, targetConnection);
}
}
package io.seata.rm.datasource;
import java.sql.Connection;
public abstract class AbstractConnectionProxy implements Connection {
protected Connection targetConnection;
public AbstractConnectionProxy(DataSourceProxy dataSourceProxy, Connection targetConnection) {
this.dataSourceProxy = dataSourceProxy;
this.targetConnection = targetConnection;
}
@Override
public PreparedStatement prepareStatement(String sql) throws SQLException {
String dbType = getDbType();
// support oracle 10.2+
PreparedStatement targetPreparedStatement = null;
if (BranchType.AT == RootContext.getBranchType()) { //为什么这里会返回AT?
List<SQLRecognizer> sqlRecognizers = SQLVisitorFactory.get(sql, dbType);
if (sqlRecognizers != null && sqlRecognizers.size() == 1) {
SQLRecognizer sqlRecognizer = sqlRecognizers.get(0);
if (sqlRecognizer != null && sqlRecognizer.getSQLType() == SQLType.INSERT) {
TableMeta tableMeta = TableMetaCacheFactory.getTableMetaCache(dbType).getTableMeta(getTargetConnection(),
sqlRecognizer.getTableName(), getDataSourceProxy().getResourceId());
String[] pkNameArray = new String[tableMeta.getPrimaryKeyOnlyName().size()];
tableMeta.getPrimaryKeyOnlyName().toArray(pkNameArray);
// 如果是insert语句,这里创建的PreparedStatement需要可以返回自动生成的主键,因此使用这个prepareStatement()
targetPreparedStatement = getTargetConnection().prepareStatement(sql,pkNameArray);
}
}
}
if (targetPreparedStatement == null) {
targetPreparedStatement = getTargetConnection().prepareStatement(sql);
}
return new PreparedStatementProxy(this, targetPreparedStatement, sql);
}
public Connection getTargetConnection() {
return targetConnection;
}
}
先在这打下个疑问,后边解释。
RootContext.getBranchType()的返回值怎么会是AT?
StatementProxy.execute()的处理逻辑
-
当调用
io.seata.rm.datasource.StatementProxy.execute()会将sql交给io.seata.rm.datasource.exec.ExecuteTemplate.execute(...)处理。package io.seata.rm.datasource;
public class PreparedStatementProxy extends AbstractPreparedStatementProxy
implements PreparedStatement, ParametersHolder {
@Override
public boolean execute() throws SQLException {
return ExecuteTemplate.execute(this, (statement, args) -> statement.execute());
}
}-
ExecuteTemplate.execute(...)方法中,Seata根据不同dbType和sql语句类型使用不同的Executer,调用io.seata.rm.datasource.exec.Executer类的execute(Object... args)。package io.seata.rm.datasource.exec;
public class ExecuteTemplate {
public static <T, S extends Statement> T execute(StatementProxy<S> statementProxy,
StatementCallback<T, S> statementCallback,
Object... args) throws SQLException {
return execute(null, statementProxy, statementCallback, args);
}
public static <T, S extends Statement> T execute(List<SQLRecognizer> sqlRecognizers,
StatementProxy<S> statementProxy,
StatementCallback<T, S> statementCallback,
Object... args) throws SQLException {
if (!RootContext.requireGlobalLock() && BranchType.AT != RootContext.getBranchType()) {
// Just work as original statement
return statementCallback.execute(statementProxy.getTargetStatement(), args);
}
String dbType = statementProxy.getConnectionProxy().getDbType();
if (CollectionUtils.isEmpty(sqlRecognizers)) {
sqlRecognizers = SQLVisitorFactory.get(
statementProxy.getTargetSQL(),
dbType);
}
Executor<T> executor;
if (CollectionUtils.isEmpty(sqlRecognizers)) {
executor = new PlainExecutor<>(statementProxy, statementCallback);
} else {
if (sqlRecognizers.size() == 1) {
SQLRecognizer sqlRecognizer = sqlRecognizers.get(0);
switch (sqlRecognizer.getSQLType()) {
case INSERT:
executor = EnhancedServiceLoader.load(InsertExecutor.class, dbType,
new Class[]{StatementProxy.class, StatementCallback.class, SQLRecognizer.class},
new Object[]{statementProxy, statementCallback, sqlRecognizer});
break;
case UPDATE:
executor = new UpdateExecutor<>(statementProxy, statementCallback, sqlRecognizer);
break;
case DELETE:
executor = new DeleteExecutor<>(statementProxy, statementCallback, sqlRecognizer);
break;
case SELECT_FOR_UPDATE:
executor = new SelectForUpdateExecutor<>(statementProxy, statementCallback, sqlRecognizer);
break;
default:
executor = new PlainExecutor<>(statementProxy, statementCallback);
break;
}
} else {
executor = new MultiExecutor<>(statementProxy, statementCallback, sqlRecognizers);
}
}
T rs;
try {
rs = executor.execute(args);
} catch (Throwable ex) {
if (!(ex instanceof SQLException)) {
// Turn other exception into SQLException
ex = new SQLException(ex);
}
throw (SQLException) ex;
}
return rs;
}
}也在这打下个疑问,后边解释。
RootContext.requireGlobalLock()怎么判断当前是否需要全局锁?先以
io.seata.rm.datasource.exec.UpdateExecutor举例,UpdateExecutorextendsAbstractDMLBaseExecutorextendsBaseTransactionalExecutor。 观察execute()方法的做了什么package io.seata.rm.datasource.exec;
public abstract class BaseTransactionalExecutor<T, S extends Statement> implements Executor<T> {
protected StatementProxy<S> statementProxy;
protected StatementCallback<T, S> statementCallback;
protected SQLRecognizer sqlRecognizer;
public BaseTransactionalExecutor(StatementProxy<S> statementProxy, StatementCallback<T, S> statementCallback,
SQLRecognizer sqlRecognizer) {
this.statementProxy = statementProxy;
this.statementCallback = statementCallback;
this.sqlRecognizer = sqlRecognizer;
}
@Override
public T execute(Object... args) throws Throwable {
String xid = RootContext.getXID();
if (xid != null) {
statementProxy.getConnectionProxy().bind(xid);
}
statementProxy.getConnectionProxy().setGlobalLockRequire(RootContext.requireGlobalLock());
return doExecute(args);
}
}public abstract class AbstractDMLBaseExecutor<T, S extends Statement> extends BaseTransactionalExecutor<T, S> {
public AbstractDMLBaseExecutor(StatementProxy<S> statementProxy, StatementCallback<T, S> statementCallback,
SQLRecognizer sqlRecognizer) {
super(statementProxy, statementCallback, sqlRecognizer);
}
@Override
public T doExecute(Object... args) throws Throwable {
AbstractConnectionProxy connectionProxy = statementProxy.getConnectionProxy();
if (connectionProxy.getAutoCommit()) {
return executeAutoCommitTrue(args);
} else {
return executeAutoCommitFalse(args);
}
}
protected T executeAutoCommitTrue(Object[] args) throws Throwable {
ConnectionProxy connectionProxy = statementProxy.getConnectionProxy();
try {
connectionProxy.changeAutoCommit(); // 注意,你如果没开启事务,seata帮你开启
return new LockRetryPolicy(connectionProxy).execute(() -> {
T result = executeAutoCommitFalse(args);
connectionProxy.commit(); // 帮你开启事务后,通过connectionProxy来提交
return result;
});
} catch (Exception e) {
// when exception occur in finally,this exception will lost, so just print it here
LOGGER.error("execute executeAutoCommitTrue error:{}", e.getMessage(), e);
if (!LockRetryPolicy.isLockRetryPolicyBranchRollbackOnConflict()) {
connectionProxy.getTargetConnection().rollback();
}
throw e;
} finally {
connectionProxy.getContext().reset();
connectionProxy.setAutoCommit(true);
}
}
protected T executeAutoCommitFalse(Object[] args) throws Exception {
if (!JdbcConstants.MYSQL.equalsIgnoreCase(getDbType()) && isMultiPk()) {
throw new NotSupportYetException("multi pk only support mysql!");
}
TableRecords beforeImage = beforeImage();
T result = statementCallback.execute(statementProxy.getTargetStatement(), args);
TableRecords afterImage = afterImage(beforeImage);
prepareUndoLog(beforeImage, afterImage);
return result;
}
}package io.seata.rm.datasource.exec;
public class UpdateExecutor<T, S extends Statement> extends AbstractDMLBaseExecutor<T, S> {
public UpdateExecutor(StatementProxy<S> statementProxy, StatementCallback<T, S> statementCallback,
SQLRecognizer sqlRecognizer) {
super(statementProxy, statementCallback, sqlRecognizer);
}
} -
如果选了DML类型Executer,可以在上面的executeAutoCommitFalse()中看到,主要做了以下事情:
-
查询前镜像(select for update,因此此时获得本地锁)
package io.seata.rm.datasource.exec;
public class UpdateExecutor<T, S extends Statement> extends AbstractDMLBaseExecutor<T, S> {
private static final boolean ONLY_CARE_UPDATE_COLUMNS = CONFIG.getBoolean(
ConfigurationKeys.TRANSACTION_UNDO_ONLY_CARE_UPDATE_COLUMNS, DefaultValues.DEFAULT_ONLY_CARE_UPDATE_COLUMNS); // 默认为true
@Override
protected TableRecords beforeImage() throws SQLException {
ArrayList<List<Object>> paramAppenderList = new ArrayList<>();
TableMeta tmeta = getTableMeta();
String selectSQL = buildBeforeImageSQL(tmeta, paramAppenderList);
// SELECT id, count FROM storage_tbl WHERE id = ? FOR UPDATE
return buildTableRecords(tmeta, selectSQL, paramAppenderList);
}
private String buildBeforeImageSQL(TableMeta tableMeta, ArrayList<List<Object>> paramAppenderList) {
SQLUpdateRecognizer recognizer = (SQLUpdateRecognizer) sqlRecognizer;
List<String> updateColumns = recognizer.getUpdateColumns();
StringBuilder prefix = new StringBuilder("SELECT ");
StringBuilder suffix = new StringBuilder(" FROM ").append(getFromTableInSQL());
String whereCondition = buildWhereCondition(recognizer, paramAppenderList);
if (StringUtils.isNotBlank(whereCondition)) {
suffix.append(WHERE).append(whereCondition);
}
String orderBy = recognizer.getOrderBy();
if (StringUtils.isNotBlank(orderBy)) {
suffix.append(orderBy);
}
ParametersHolder parametersHolder = statementProxy instanceof ParametersHolder ? (ParametersHolder)statementProxy : null;
String limit = recognizer.getLimit(parametersHolder, paramAppenderList);
if (StringUtils.isNotBlank(limit)) {
suffix.append(limit);
}
suffix.append(" FOR UPDATE");
StringJoiner selectSQLJoin = new StringJoiner(", ", prefix.toString(), suffix.toString());
if (ONLY_CARE_UPDATE_COLUMNS) {
if (!containsPK(updateColumns)) {// 如果本次更新的行不包含主键,那select for update的时候加上主键
selectSQLJoin.add(getColumnNamesInSQL(tableMeta.getEscapePkNameList(getDbType())));
}
for (String columnName : updateColumns) {
selectSQLJoin.add(columnName);
}
} else {
for (String columnName : tableMeta.getAllColumns().keySet()) {
selectSQLJoin.add(ColumnUtils.addEscape(columnName, getDbType()));
}
}
return selectSQLJoin.toString();
}
protected TableRecords buildTableRecords(TableMeta tableMeta, String selectSQL, ArrayList<List<Object>> paramAppenderList) throws SQLException {
ResultSet rs = null;
try (PreparedStatement ps = statementProxy.getConnection().prepareStatement(selectSQL)) { // 执行select for update,然后就拿到了本地锁
if (CollectionUtils.isNotEmpty(paramAppenderList)) {
for (int i = 0, ts = paramAppenderList.size(); i < ts; i++) {
List<Object> paramAppender = paramAppenderList.get(i);
for (int j = 0, ds = paramAppender.size(); j < ds; j++) {
ps.setObject(i * ds + j + 1, paramAppender.get(j));
}
}
}
rs = ps.executeQuery();
return TableRecords.buildRecords(tableMeta, rs);
} finally {
IOUtil.close(rs);
}
}
} -
执行业务sql
-
查询后镜像
package io.seata.rm.datasource.exec;
public class UpdateExecutor<T, S extends Statement> extends AbstractDMLBaseExecutor<T, S> {
@Override
protected TableRecords afterImage(TableRecords beforeImage) throws SQLException {
TableMeta tmeta = getTableMeta();
if (beforeImage == null || beforeImage.size() == 0) {
return TableRecords.empty(getTableMeta());
}
String selectSQL = buildAfterImageSQL(tmeta, beforeImage);
//SELECT id, count FROM storage_tbl WHERE (id) in ( (?) )
ResultSet rs = null;
try (PreparedStatement pst = statementProxy.getConnection().prepareStatement(selectSQL)) {
SqlGenerateUtils.setParamForPk(beforeImage.pkRows(), getTableMeta().getPrimaryKeyOnlyName(), pst);
rs = pst.executeQuery();
return TableRecords.buildRecords(tmeta, rs);
} finally {
IOUtil.close(rs);
}
}
} -
准备undoLog
public abstract class BaseTransactionalExecutor<T, S extends Statement> implements Executor<T> {
protected void prepareUndoLog(TableRecords beforeImage, TableRecords afterImage) throws SQLException {
if (beforeImage.getRows().isEmpty() && afterImage.getRows().isEmpty()) {
return;
}
if (SQLType.UPDATE == sqlRecognizer.getSQLType()) {
if (beforeImage.getRows().size() != afterImage.getRows().size()) {
throw new ShouldNeverHappenException("Before image size is not equaled to after image size, probably because you updated the primary keys.");
}
}
ConnectionProxy connectionProxy = statementProxy.getConnectionProxy();
TableRecords lockKeyRecords = sqlRecognizer.getSQLType() == SQLType.DELETE ? beforeImage : afterImage;
String lockKeys = buildLockKey(lockKeyRecords);
if (null != lockKeys) {
connectionProxy.appendLockKey(lockKeys);
SQLUndoLog sqlUndoLog = buildUndoItem(beforeImage, afterImage);
connectionProxy.appendUndoLog(sqlUndoLog); // 把undoLog存到connectionProxy中,具体怎么回事上面有提过
}
}
}
-
-
如果你的sql是select for update则会使用
SelectForUpdateExecutor(Seata代理了select for update),代理后处理的逻辑是这样的:- 先执行 select for update(获取数据库本地锁)
- 如果处于
@GlobalTransactionalor@GlobalLock,检查是否有全局锁 - 如果有全局锁,则未开启本地事务下会rollback本地事务,再重新争抢本地锁和查询全局锁,直到全局锁释放
package io.seata.rm.datasource.exec;
public class SelectForUpdateExecutor<T, S extends Statement> extends BaseTransactionalExecutor<T, S> {
@Override
public T doExecute(Object... args) throws Throwable {
Connection conn = statementProxy.getConnection();
DatabaseMetaData dbmd = conn.getMetaData();
T rs;
Savepoint sp = null;
boolean originalAutoCommit = conn.getAutoCommit();
try {
if (originalAutoCommit) {
/*
* In order to hold the local db lock during global lock checking
* set auto commit value to false first if original auto commit was true
*/
conn.setAutoCommit(false);
} else if (dbmd.supportsSavepoints()) {
/*
* In order to release the local db lock when global lock conflict
* create a save point if original auto commit was false, then use the save point here to release db
* lock during global lock checking if necessary
*/
sp = conn.setSavepoint();
} else {
throw new SQLException("not support savepoint. please check your db version");
}
LockRetryController lockRetryController = new LockRetryController();
ArrayList<List<Object>> paramAppenderList = new ArrayList<>();
String selectPKSQL = buildSelectSQL(paramAppenderList);
while (true) {
try {
// #870
// execute return Boolean
// executeQuery return ResultSet
rs = statementCallback.execute(statementProxy.getTargetStatement(), args); //执行 select for update(获取数据库本地锁)
// Try to get global lock of those rows selected
TableRecords selectPKRows = buildTableRecords(getTableMeta(), selectPKSQL, paramAppenderList);
String lockKeys = buildLockKey(selectPKRows);
if (StringUtils.isNullOrEmpty(lockKeys)) {
break;
}
if (RootContext.inGlobalTransaction() || RootContext.requireGlobalLock()) {
// Do the same thing under either @GlobalTransactional or @GlobalLock,
// that only check the global lock here.
statementProxy.getConnectionProxy().checkLock(lockKeys);
} else {
throw new RuntimeException("Unknown situation!");
}
break;
} catch (LockConflictException lce) {
if (sp != null) {
conn.rollback(sp);
} else {
conn.rollback();// 回滚,释放本地锁
}
// trigger retry
lockRetryController.sleep(lce);
}
}
} finally {
if (sp != null) {
try {
if (!JdbcConstants.ORACLE.equalsIgnoreCase(getDbType())) {
conn.releaseSavepoint(sp);
}
} catch (SQLException e) {
LOGGER.error("{} release save point error.", getDbType(), e);
}
}
if (originalAutoCommit) {
conn.setAutoCommit(true);
}
}
return rs;
}
}
-
ConnectionProxy.commit()的处理逻辑
public class ConnectionProxy extends AbstractConnectionProxy {
private final static LockRetryPolicy LOCK_RETRY_POLICY = new LockRetryPolicy();
private ConnectionContext context = new ConnectionContext();
@Override
public void commit() throws SQLException {
try {
LOCK_RETRY_POLICY.execute(() -> {
doCommit();
return null;
});
} catch (SQLException e) {
if (targetConnection != null && !getAutoCommit() && !getContext().isAutoCommitChanged()) {
rollback();
}
throw e;
} catch (Exception e) {
throw new SQLException(e);
}
}
private void doCommit() throws SQLException {
if (context.inGlobalTransaction()) {
processGlobalTransactionCommit();
} else if (context.isGlobalLockRequire()) {
processLocalCommitWithGlobalLocks();
} else {
targetConnection.commit();
}
}
}
也在这打下个疑问,后边解释。
ConnectionProxy里的ConnectionContext是如何判断inGlobalTransaction()orisGlobalLockRequire()的呢?
-
处于全局事务中(即,数据持久化方法带有
@GlobalTransactional)- 注册分支事务,获取全局锁
- undoLog数据入库
- 让数据库commit本次事务
public class ConnectionProxy extends AbstractConnectionProxy {
private final static LockRetryPolicy LOCK_RETRY_POLICY = new LockRetryPolicy();
private ConnectionContext context = new ConnectionContext();
private void processGlobalTransactionCommit() throws SQLException {
try {
register(); // 注册分支,争全局锁
} catch (TransactionException e) {
recognizeLockKeyConflictException(e, context.buildLockKeys());
}
try {
UndoLogManagerFactory.getUndoLogManager(this.getDbType()).flushUndoLogs(this); // undolog入库
targetConnection.commit(); // 分支事务提交
} catch (Throwable ex) {
LOGGER.error("process connectionProxy commit error: {}", ex.getMessage(), ex);
report(false);
throw new SQLException(ex);
}
if (IS_REPORT_SUCCESS_ENABLE) {
report(true);
}
context.reset();
}
private void register() throws TransactionException {
if (!context.hasUndoLog() || !context.hasLockKey()) {
return;
}
Long branchId = DefaultResourceManager.get().branchRegister(BranchType.AT, getDataSourceProxy().getResourceId(),
null, context.getXid(), null, context.buildLockKeys());
context.setBranchId(branchId);
}
} -
处于
@GlobalLock中(即,数据持久化方法带有@GlobalLock)- 向tc查询是否有全局锁存在
- 让数据库commit本次事务
public class ConnectionProxy extends AbstractConnectionProxy {
private final static LockRetryPolicy LOCK_RETRY_POLICY = new LockRetryPolicy();
private ConnectionContext context = new ConnectionContext();
private void processLocalCommitWithGlobalLocks() throws SQLException {
checkLock(context.buildLockKeys());
try {
targetConnection.commit();
} catch (Throwable ex) {
throw new SQLException(ex);
}
context.reset();
}
public void checkLock(String lockKeys) throws SQLException {
if (StringUtils.isBlank(lockKeys)) {
return;
}
// Just check lock without requiring lock by now.
try {
boolean lockable = DefaultResourceManager.get().lockQuery(BranchType.AT,
getDataSourceProxy().getResourceId(), context.getXid(), lockKeys);
if (!lockable) {
throw new LockConflictException();
}
} catch (TransactionException e) {
recognizeLockKeyConflictException(e, lockKeys);
}
}
} -
除了以上情况(
else分支)- 让数据库commit本次事务
介绍RootContext
我们在上面留下了3个“扣儿”,现在到了结合RootContext源码来解答的时候。
-
RootContext.getBranchType()的返回值怎么会是AT?
该方法的判断逻辑是:只要判断出当前处于全局事务中(即,只要有地方调用过RootContext.bind(xid)), 就会返回默认BranchType.ATpublic class RootContext {
public static final String KEY_XID = "TX_XID";
private static ContextCore CONTEXT_HOLDER = ContextCoreLoader.load();
private static BranchType DEFAULT_BRANCH_TYPE;
@Nullable
public static BranchType getBranchType() {
if (inGlobalTransaction()) {
BranchType branchType = (BranchType) CONTEXT_HOLDER.get(KEY_BRANCH_TYPE);
if (branchType != null) {
return branchType;
}
//Returns the default branch type.
return DEFAULT_BRANCH_TYPE != null ? DEFAULT_BRANCH_TYPE : BranchType.AT;
}
return null;
}
public static boolean inGlobalTransaction() {
return CONTEXT_HOLDER.get(KEY_XID) != null;
}
public static void bind(@Nonnull String xid) {
if (StringUtils.isBlank(xid)) {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("xid is blank, switch to unbind operation!");
}
unbind();
} else {
MDC.put(MDC_KEY_XID, xid);
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("bind {}", xid);
}
CONTEXT_HOLDER.put(KEY_XID, xid);
}
}
} -
RootContext.requireGlobalLock()怎么判断当前是否需要全局锁?
需要有地方调用RootContext.bindGlobalLockFlag()public class RootContext {
public static final String KEY_GLOBAL_LOCK_FLAG = "TX_LOCK";
public static final Boolean VALUE_GLOBAL_LOCK_FLAG = true;
private static ContextCore CONTEXT_HOLDER = ContextCoreLoader.load();
public static boolean requireGlobalLock() {
return CONTEXT_HOLDER.get(KEY_GLOBAL_LOCK_FLAG) != null;
}
public static void bindGlobalLockFlag() {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("Local Transaction Global Lock support enabled");
}
//just put something not null
CONTEXT_HOLDER.put(KEY_GLOBAL_LOCK_FLAG, VALUE_GLOBAL_LOCK_FLAG);
}
} -
ConnectionProxy.commit()会根据context的不同状态区分处理,那ConnectionContext是如何判断inGlobalTransaction()orisGlobalLockRequire()的呢?public class ConnectionProxy extends AbstractConnectionProxy {
private ConnectionContext context = new ConnectionContext();
private void doCommit() throws SQLException {
if (context.inGlobalTransaction()) {
processGlobalTransactionCommit();
} else if (context.isGlobalLockRequire()) {
processLocalCommitWithGlobalLocks();
} else {
targetConnection.commit();
}
}
}- 如何判断
inGlobalTransaction()?(注意下,这里和上面提到的RootContext不是一个东西)哪里调用的public class ConnectionContext {
private String xid;
void setXid(String xid) {
this.xid = xid;
}
public boolean inGlobalTransaction() {
return xid != null;
}
void bind(String xid) {
if (xid == null) {
throw new IllegalArgumentException("xid should not be null");
}
if (!inGlobalTransaction()) {
setXid(xid);
} else {
if (!this.xid.equals(xid)) {
throw new ShouldNeverHappenException();
}
}
}
}ConnectionContext.bind(xid)?package io.seata.rm.datasource.exec;
public abstract class BaseTransactionalExecutor<T, S extends Statement> implements Executor<T> {
@Override
public T execute(Object... args) throws Throwable {
// 那么,这里的XID哪来的呢?往后看就知道,是来自开启全局事务的时候获得的,和@GlobalTransactional有关
String xid = RootContext.getXID();
if (xid != null) {
statementProxy.getConnectionProxy().bind(xid);
}
// 这里就是设置 isGlobalLockRequire的位置,和 @GlobalLock有关
statementProxy.getConnectionProxy().setGlobalLockRequire(RootContext.requireGlobalLock());
return doExecute(args);
}
}public class ConnectionProxy extends AbstractConnectionProxy {
private ConnectionContext context = new ConnectionContext();
public void bind(String xid) {
context.bind(xid);
}
public void setGlobalLockRequire(boolean isLock) {
context.setGlobalLockRequire(isLock);
}
} - 如何判断
isGlobalLockRequire()?public class ConnectionContext {
private boolean isGlobalLockRequire;
boolean isGlobalLockRequire() {
return isGlobalLockRequire;
}
void setGlobalLockRequire(boolean isGlobalLockRequire) {
this.isGlobalLockRequire = isGlobalLockRequire;
}
}
在看过代码后,我们知道,只要有地方在
RootContext中设置了xid,或bindGlobalLockFlag(),就会识别成不同的状态。 那么哪儿调用的呢?答案就在下方的GlobalTransactionalInterceptor中。 - 如何判断
GlobalTransactionalInterceptor处理带有@GlobalTransactional或@GlobalLock的方法
带有@GlobalTransactional和@GlobalLock的方法会被代理,交给GlobalTransactionalInterceptor处理
public class GlobalTransactionalInterceptor implements ConfigurationChangeListener, MethodInterceptor {
@Override
public Object invoke(final MethodInvocation methodInvocation) throws Throwable {
Class<?> targetClass =
methodInvocation.getThis() != null ? AopUtils.getTargetClass(methodInvocation.getThis()) : null;
Method specificMethod = ClassUtils.getMostSpecificMethod(methodInvocation.getMethod(), targetClass);
if (specificMethod != null && !specificMethod.getDeclaringClass().equals(Object.class)) {
final Method method = BridgeMethodResolver.findBridgedMethod(specificMethod);
final GlobalTransactional globalTransactionalAnnotation =
getAnnotation(method, targetClass, GlobalTransactional.class);
final GlobalLock globalLockAnnotation = getAnnotation(method, targetClass, GlobalLock.class);
boolean localDisable = disable || (degradeCheck && degradeNum >= degradeCheckAllowTimes);
if (!localDisable) {
if (globalTransactionalAnnotation != null) {
return handleGlobalTransaction(methodInvocation, globalTransactionalAnnotation);// 处理 @GlobalTransactional
} else if (globalLockAnnotation != null) {
return handleGlobalLock(methodInvocation, globalLockAnnotation); // 处理 @GlobalLock
}
}
}
return methodInvocation.proceed();
}
}
先看处理@GlobalTransactional
public class GlobalTransactionalInterceptor implements ConfigurationChangeListener, MethodInterceptor {
private final TransactionalTemplate transactionalTemplate = new TransactionalTemplate();
Object handleGlobalTransaction(final MethodInvocation methodInvocation,
final GlobalTransactional globalTrxAnno) throws Throwable {
//...
try {
return transactionalTemplate.execute(...);
} catch (TransactionalExecutor.ExecutionException e) {
// ...
} finally {
//...
}
}
}
来到了经典的seata事务模板方法,我们要关注开启事务的部分
public class TransactionalTemplate {
public Object execute(TransactionalExecutor business) throws Throwable {
// 1. Get transactionInfo
//...
// 1.1 Get current transaction, if not null, the tx role is 'GlobalTransactionRole.Participant'.
GlobalTransaction tx = GlobalTransactionContext.getCurrent();
// 1.2 Handle the transaction propagation.
// ...
// 1.3 If null, create new transaction with role 'GlobalTransactionRole.Launcher'.
if (tx == null) {
tx = GlobalTransactionContext.createNew();
}
//...
try {
// 2. If the tx role is 'GlobalTransactionRole.Launcher', send the request of beginTransaction to TC,
// else do nothing. Of course, the hooks will still be triggered.
beginTransaction(txInfo, tx);
Object rs;
try {
// Do Your Business
rs = business.execute();
} catch (Throwable ex) {
// 3. The needed business exception to rollback.
completeTransactionAfterThrowing(txInfo, tx, ex);
throw ex;
}
// 4. everything is fine, commit.
commitTransaction(tx);
return rs;
} finally {
//5. clear
//...
}
} finally {
// If the transaction is suspended, resume it.
// ...
}
}
private void beginTransaction(TransactionInfo txInfo, GlobalTransaction tx) throws TransactionalExecutor.ExecutionException {
try {
triggerBeforeBegin();
tx.begin(txInfo.getTimeOut(), txInfo.getName());
triggerAfterBegin();
} catch (TransactionException txe) {
throw new TransactionalExecutor.ExecutionException(tx, txe,
TransactionalExecutor.Code.BeginFailure);
}
}
}
public class DefaultGlobalTransaction implements GlobalTransaction {
@Override
public void begin(int timeout, String name) throws TransactionException {
if (role != GlobalTransactionRole.Launcher) {
assertXIDNotNull();
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("Ignore Begin(): just involved in global transaction [{}]", xid);
}
return;
}
assertXIDNull();
String currentXid = RootContext.getXID();
if (currentXid != null) {
throw new IllegalStateException("Global transaction already exists," +
" can't begin a new global transaction, currentXid = " + currentXid);
}
xid = transactionManager.begin(null, null, name, timeout);
status = GlobalStatus.Begin;
RootContext.bind(xid); // 绑定xid
if (LOGGER.isInfoEnabled()) {
LOGGER.info("Begin new global transaction [{}]", xid);
}
}
}
看到了吗?RootContext.bind(xid);
接着看处理@GlobalLock
public class GlobalTransactionalInterceptor implements ConfigurationChangeListener, MethodInterceptor {
private final GlobalLockTemplate globalLockTemplate = new GlobalLockTemplate();
Object handleGlobalLock(final MethodInvocation methodInvocation,
final GlobalLock globalLockAnno) throws Throwable {
return globalLockTemplate.execute(new GlobalLockExecutor() {...});
}
}
也使用了模板方法来处理GlobalLock
public class GlobalLockTemplate {
public Object execute(GlobalLockExecutor executor) throws Throwable {
boolean alreadyInGlobalLock = RootContext.requireGlobalLock();
if (!alreadyInGlobalLock) {
RootContext.bindGlobalLockFlag();
}
// set my config to config holder so that it can be access in further execution
// for example, LockRetryController can access it with config holder
GlobalLockConfig myConfig = executor.getGlobalLockConfig();
GlobalLockConfig previousConfig = GlobalLockConfigHolder.setAndReturnPrevious(myConfig);
try {
return executor.execute();
} finally {
// only unbind when this is the root caller.
// otherwise, the outer caller would lose global lock flag
if (!alreadyInGlobalLock) {
RootContext.unbindGlobalLockFlag();
}
// if previous config is not null, we need to set it back
// so that the outer logic can still use their config
if (previousConfig != null) {
GlobalLockConfigHolder.setAndReturnPrevious(previousConfig);
} else {
GlobalLockConfigHolder.remove();
}
}
}
}
看到吗,一进模板方法就RootContext.bindGlobalLockFlag();