Transaction Grouping and High Availability
Best Practice 1: TC's Cross-Data Center Disaster Recovery
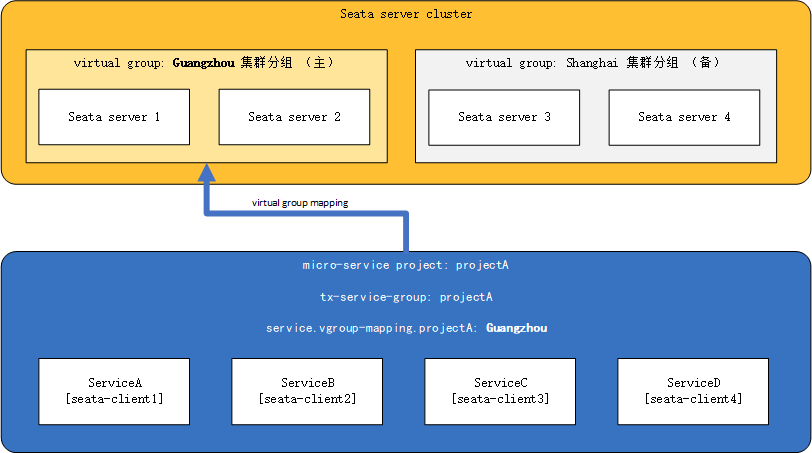
- Assume that the TC cluster is deployed in two data centers: guangzhou (primary) and shanghai (backup), each with two instances.
- A complete microservices architecture project: projectA.
- projectA contains microservices: serviceA, serviceB, serviceC, and serviceD.
Among them, the transaction grouping tx-service-group of all microservices in projectA is set to: projectA. Under normal circumstances, projectA uses the TC cluster in guangzhou (primary).
So under normal circumstances, the client-side configuration is as follows:
seata.tx-service-group=projectA
seata.service.vgroup-mapping.projectA=Guangzhou
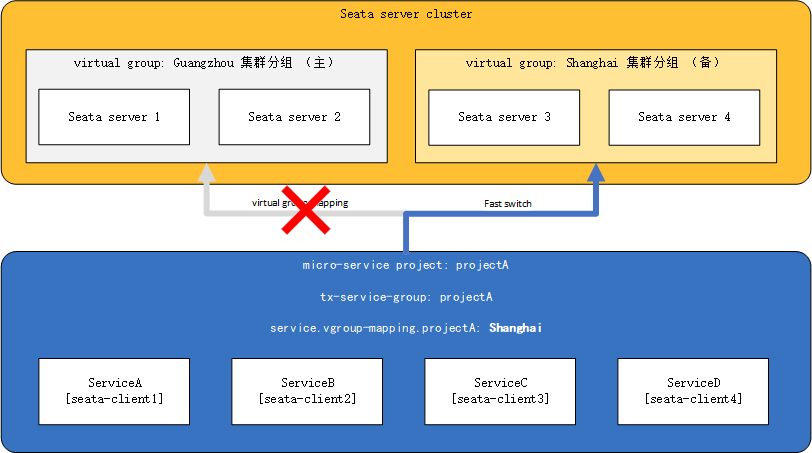
If at this time the guangzhou cluster group is completely down or projectA is temporarily unable to communicate with the Guangzhou data center due to network issues, then we can change the Guangzhou cluster group in the configuration center to Shanghai, as follows:
seata.service.vgroup-mapping.projectA=Shanghai
And push it to each microservice, completing the dynamic switch of the TC cluster for the entire projectA.
Best Practice 2: Multiple Applications Access in a Single Environment
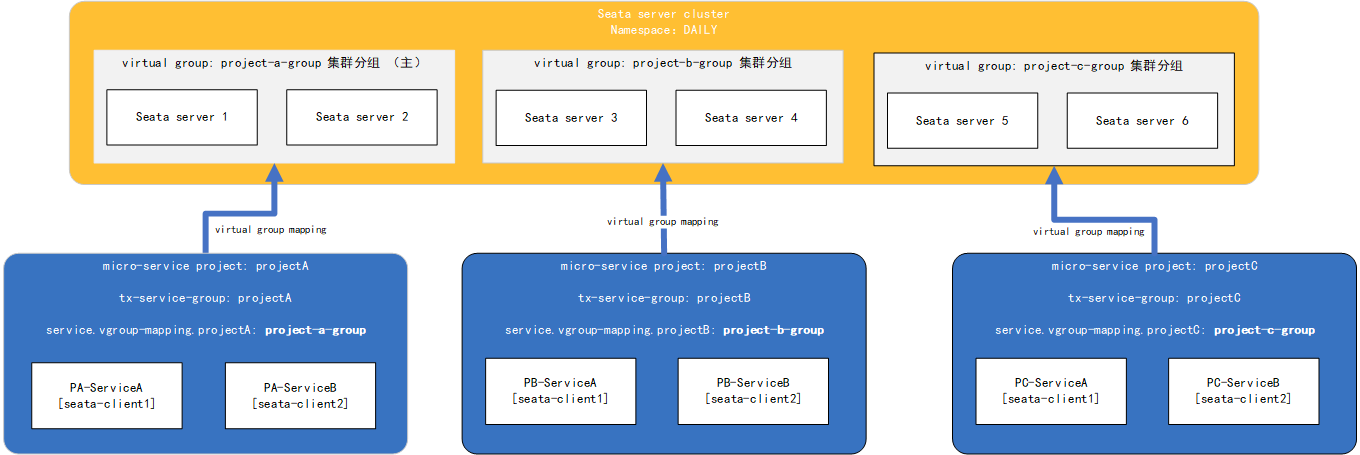
- Assume that there is a complete seata cluster in the development environment (or staging/production).
- The seata cluster serves different microservices architecture projects: projectA, projectB, projectC.
- projectA, projectB, and projectC are relatively independent of each other.
We group the six instances in the seata cluster in pairs to serve projectA, projectB, and projectC respectively. At this time, the configuration of the seata-server side is as follows (taking nacos registry as an example):
registry {
type = "nacos"
loadBalance = "RandomLoadBalance"
loadBalanceVirtualNodes = 10
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = "8f11aeb1-5042-461b-b88b-d47a7f7e01c0"
# Similarly, configure seata-server instances in other groups: project-b-group / project-c-group
cluster = "project-a-group"
username = "username"
password = "password"
}
}
The client-side configuration is as follows:
seata.tx-service-group=projectA
# Similarly, configure projectB and projectC: project-b-group / project-c-group
seata.service.vgroup-mapping.projectA=project-a-group
After completing the configuration and starting, the TC dedicated to the corresponding transaction group serves its application. The overall deployment diagram is as follows:
Best Practice 3: Fine-grained Control of the Client
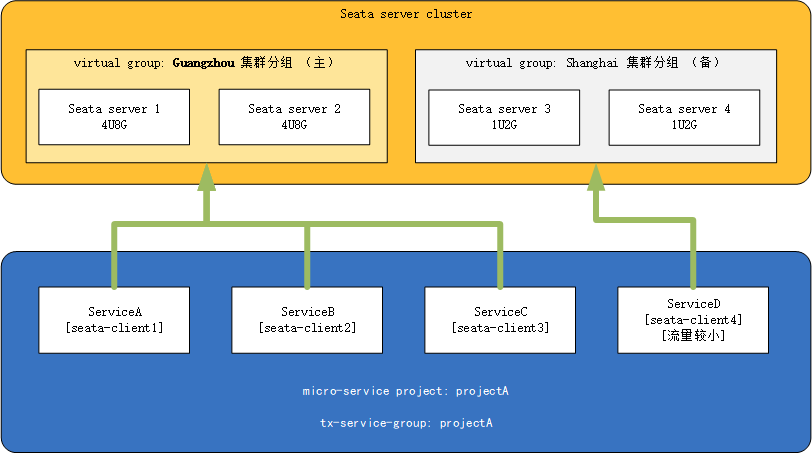
- Assume that there is a seata cluster, with the Guangzhou data center instances running on high-performance machines and the Shanghai cluster running on lower-performance machines.
- There is an existing microservices architecture project projectA, which includes microservices ServiceA, ServiceB, ServiceC, and ServiceD.
- ServiceD has lower traffic, while the other microservices have higher traffic.
So at this point, we can divert the ServiceD microservice to the Shanghai cluster and allocate high-performance servers to other microservices with higher traffic (conversely, if there is a microservice with particularly high traffic, we can also allocate a higher-performance cluster specifically for this microservice and direct the client's virtual group to that cluster, with the ultimate goal of ensuring availability during peak traffic).
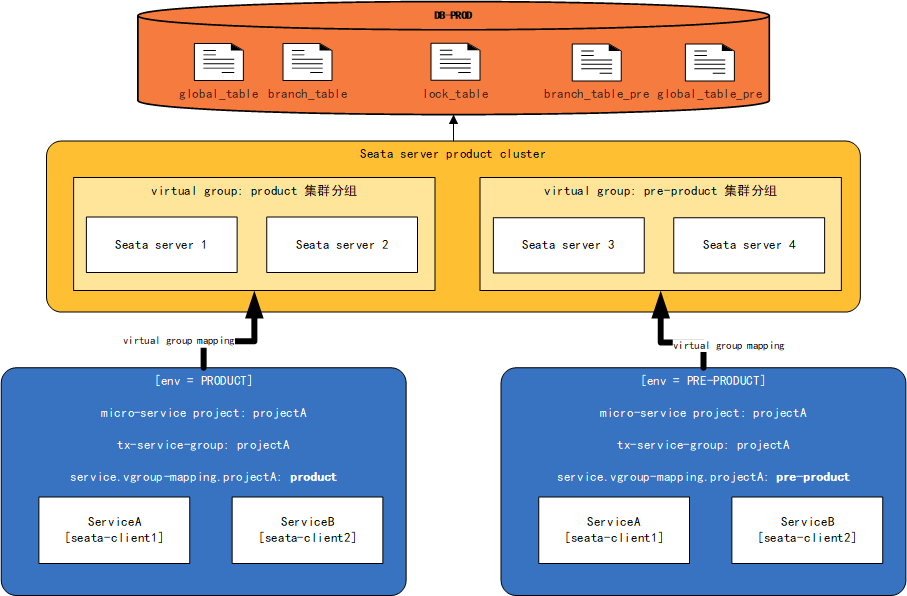
Best Practice 4: Seata's Pre-production and Production Isolation
- In most cases, the pre-production environment and the production environment will use the same set of databases. Based on this condition, the pre-production TC cluster and the production TC cluster must use the same database to ensure the effectiveness of global transactions (i.e., the production TC cluster and the pre-production TC cluster use the same lock table, but have different branch_table and global_table)
- We will refer to the branch table and global table used in production as: global_table and branch_table; and in pre-production as: global_table_pre and branch_table_pre
- The lock_table is shared between pre-production and production
At this point, the file.conf configuration of the seata-server is as follows:
store {
mode = "db"
db {
datasource = "druid"
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "username"
password = "password"
minConn = 5
maxConn = 100
globalTable = "global_table" ----> pre-production is "global_table_pre"
branchTable = "branch_table" ----> pre-production is "branch_table_pre"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
}
The registry.conf configuration of the seata-server is as follows (using nacos as an example):
registry {
type = "nacos"
loadBalance = "RandomLoadBalance"
loadBalanceVirtualNodes = 10
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = "8f11aeb1-5042-461b-b88b-d47a7f7e01c0"
cluster = "pre-product" --> similarly, production is "product"
username = "username"
password = "password"
}
}
The deployment diagram is as follows:
Furthermore, you can combine and use the above four best practices according to your actual production situation.