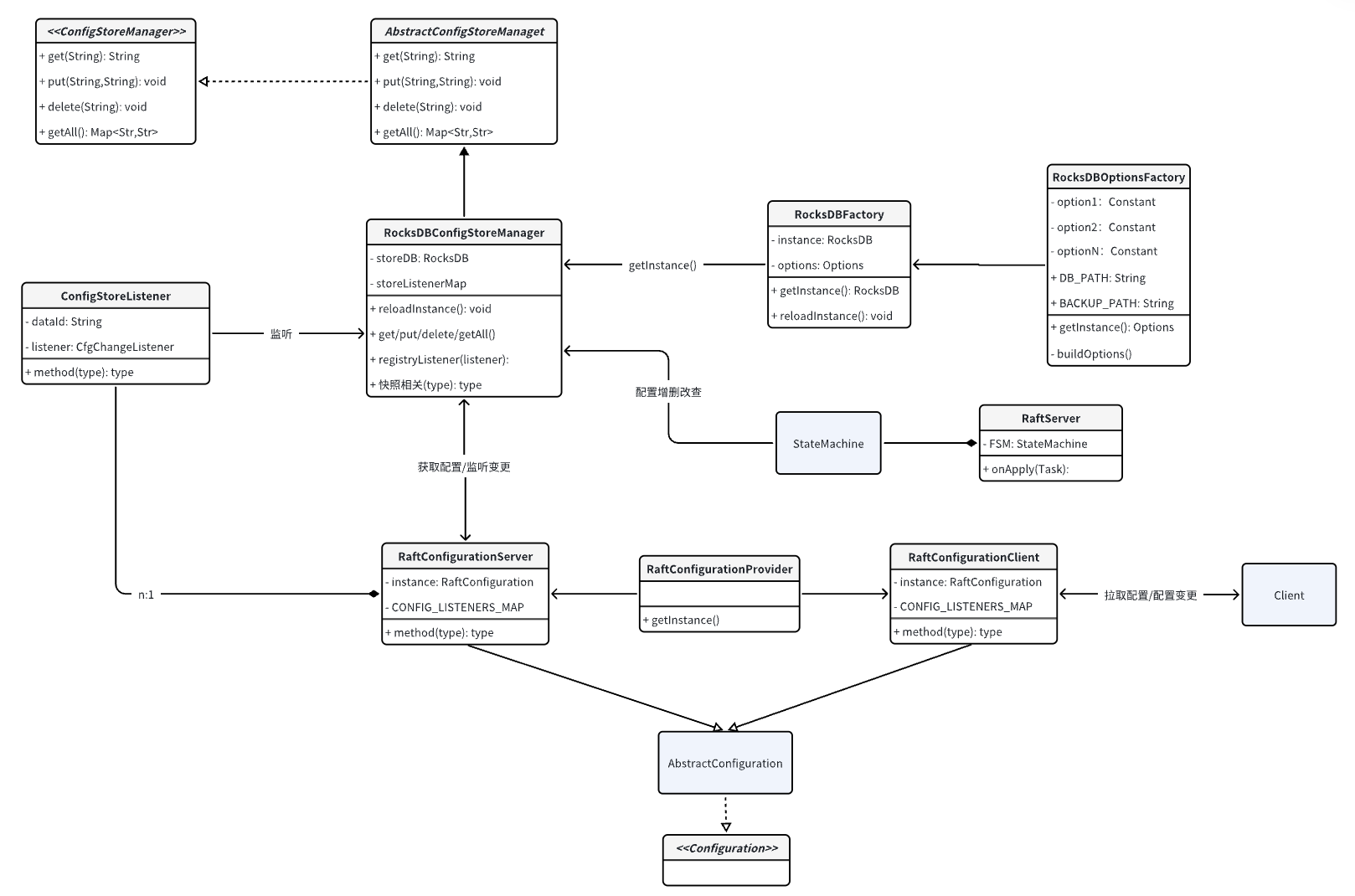
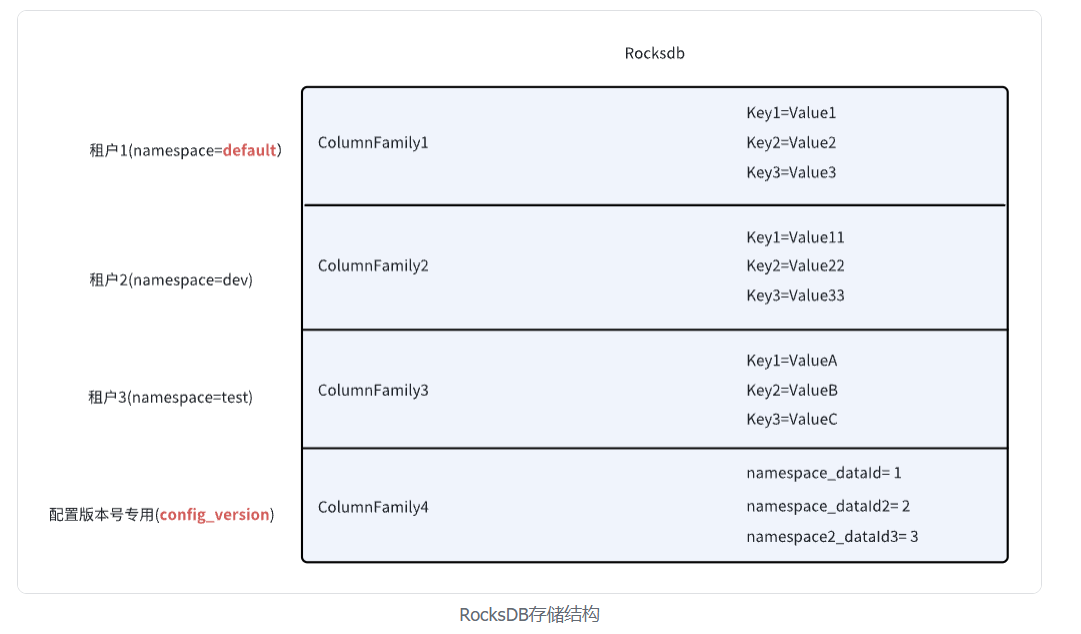
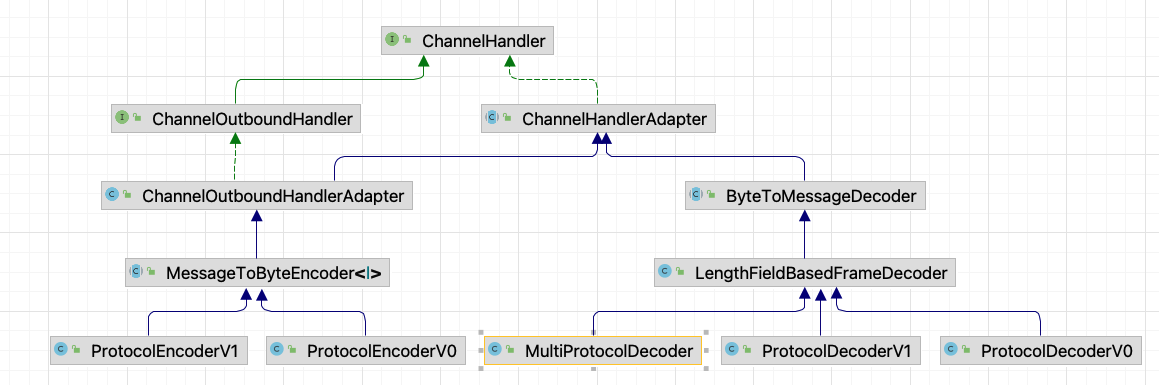
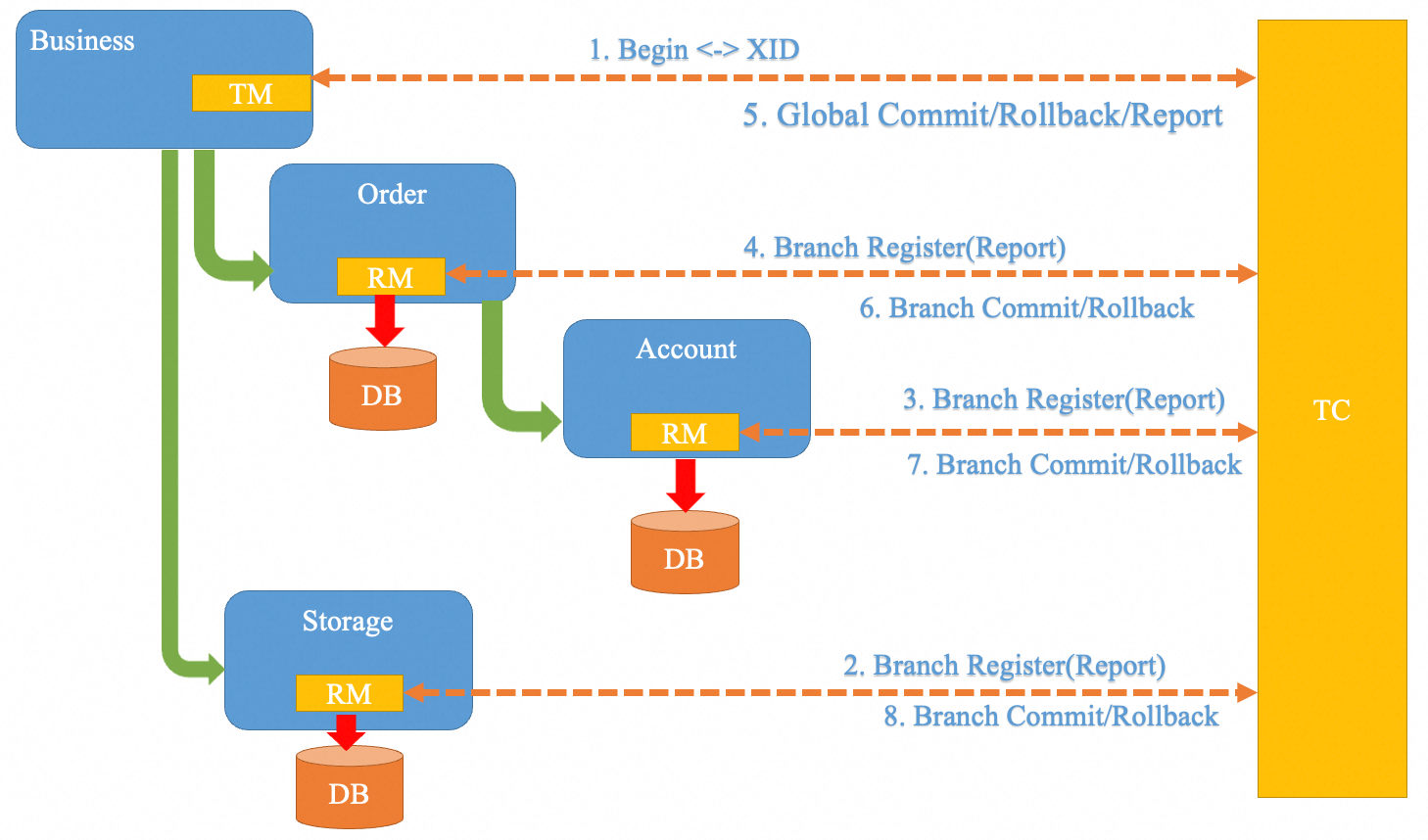
In the previous articles, we have thoroughly discussed Seata's XA, AT, and TCC modes, all of which are different transaction models defined within the global framework of Seata.
We know that in Seata, there are three types of roles: TC (Transaction Coordinator), RM (Resource Manager), and TM (Transaction Manager). The Seata Server acts as a TC to coordinate the commit and rollback of branch transactions, while various resources act as RMs and TMs. So, how do these three communicate with each other?
Therefore, this article will explore how Seata performs network communication at the underlying level.
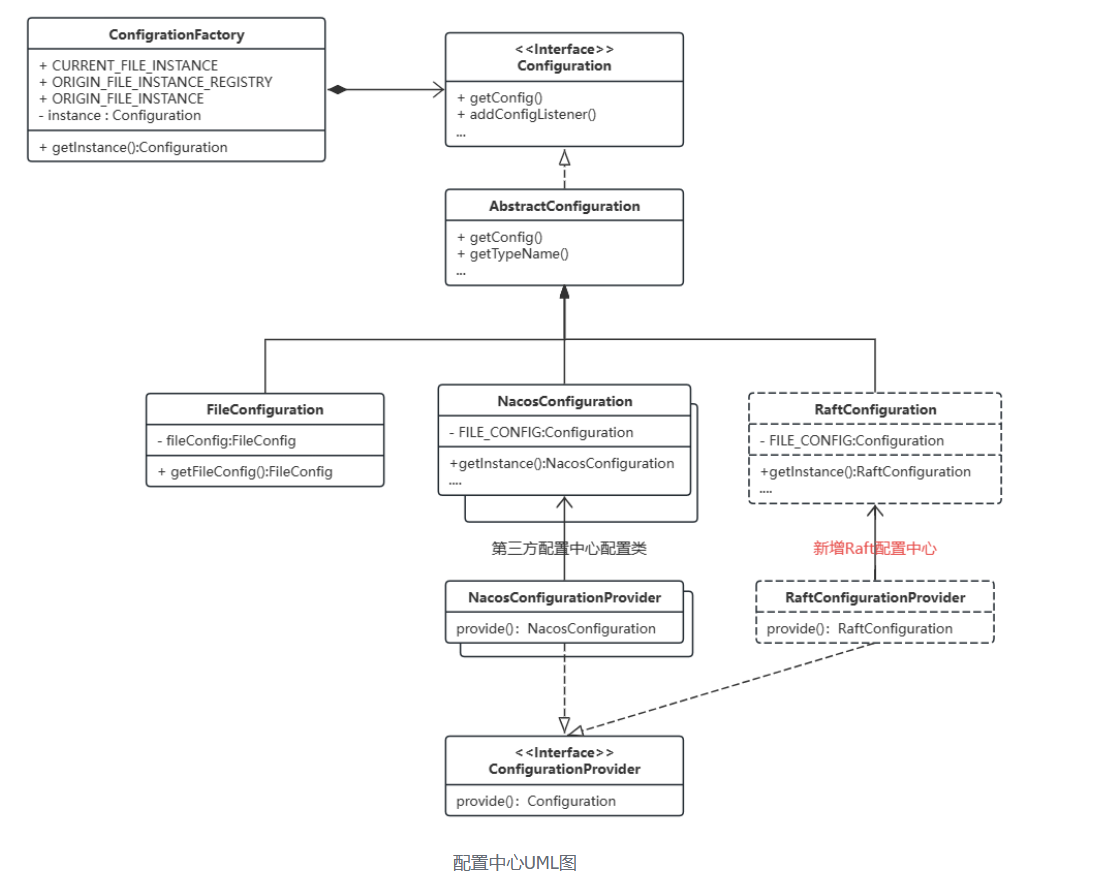
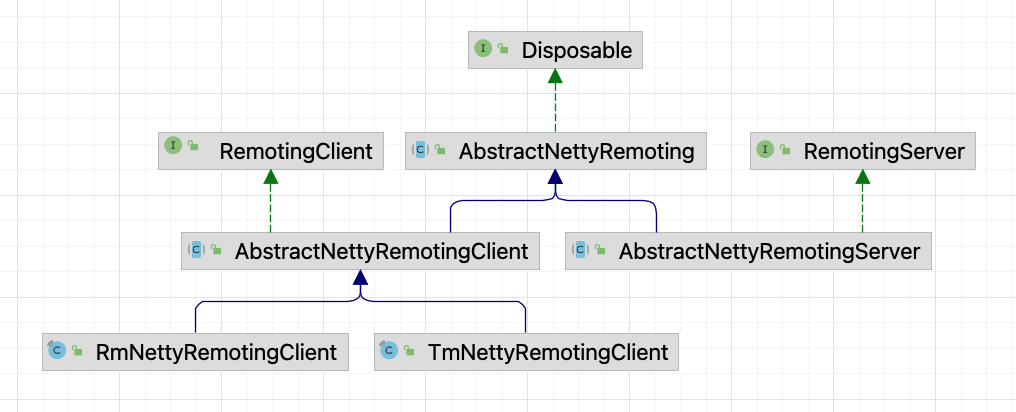
Overall Class Hierarchy Structure
Let's start by looking at the big picture, examining the overall RPC class hierarchy structure of Seata.
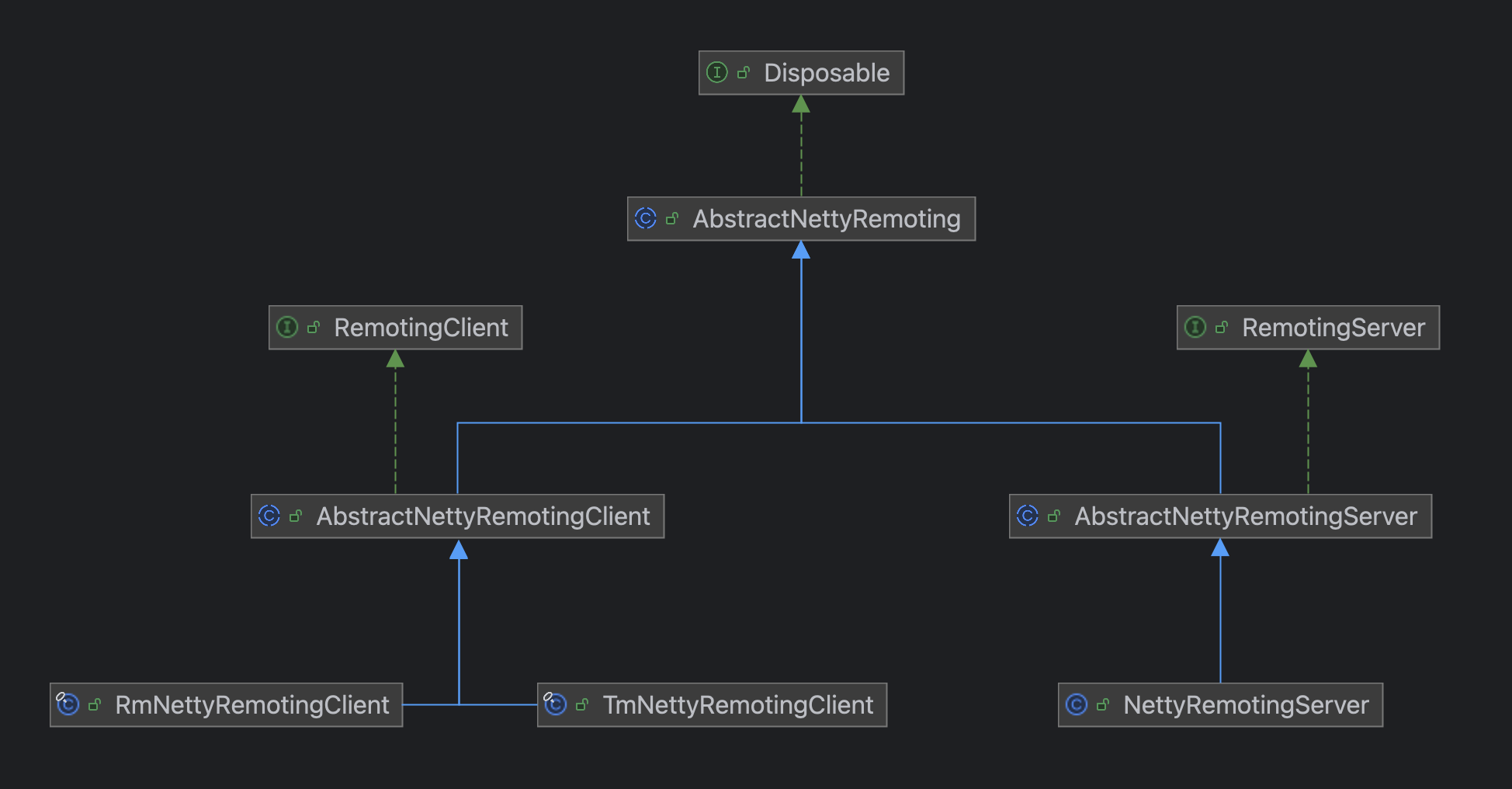
From the class hierarchy structure, it can be seen that AbstractNettyRemoting is the top-level abstract class for the entire Seata network communication.
In this class, some basic common methods of RPC are mainly implemented, such as synchronous call sendSync, asynchronous call sendAsync, etc.
Indeed, when it comes to network calls, they essentially boil down to synchronous calls and asynchronous calls; other aspects like requests and responses are just distinctions in message content.
So, in Seata, I personally think there should also be a top-level interface Remoting, similar to the following:
import io.netty.channel.Channel;
import java.util.concurrent.TimeoutException;
public interface Remoting<Req, Resp> {
Resp sendSync(Channel channel, Req request, long timeout) throws TimeoutException;
void sendAsync(Channel channel, Req request);
}
While AbstractNettyRemoting implements general network calling methods, there are still some differences among different roles. For example, for the server, its request call needs to know which client to send to, whereas for the TM and RM, they can simply send requests without specifying a particular TC service. They only need to find an appropriate server node via a load balancing algorithm in the implementation class.
Thus, RemotingServer and RemotingClient are differentiated, but they still rely on AbstractNettyRemoting for network calls at the bottom layer, so each has subclasses that implement AbstractNettyRemoting.
One might say that this design in Seata is quite commendable, serving as a general solution pattern for remote communications in this kind of Client-Server architecture.
How to Start the Server and Client
After discussing the underlying class hierarchy of Seata, let's look from the perspectives of the Server and Client on how they start up and what needs to be done during startup.
How the Server Starts
As an independent Spring Boot project, how does the Seata Server automatically perform certain tasks when Spring Boot starts?
Seata achieves this by implementing the CommandLineRunner interface. The principle behind this is not within the scope of this article.
We mainly focus on its run method:
public void run(String... args) {
try {
long start = System.currentTimeMillis();
seataServer.start(args);
started = true;
long cost = System.currentTimeMillis() - start;
LOGGER.info("\r\n you can visit seata console UI on http://127.0.0.1:{}. \r\n log path: {}.", this.port, this.logPath);
LOGGER.info("seata server started in {} millSeconds", cost);
} catch (Throwable e) {
started = Boolean.FALSE;
LOGGER.error("seata server start error: {} ", e.getMessage(), e);
System.exit(-1);
}
}
The core logic lies within the seataServer.start() method:
public void start(String[] args) {
ParameterParser parameterParser = new ParameterParser(args);
MetricsManager.get().init();
ThreadPoolExecutor workingThreads = new ThreadPoolExecutor(
NettyServerConfig.getMinServerPoolSize(),
NettyServerConfig.getMaxServerPoolSize(),
NettyServerConfig.getKeepAliveTime(), TimeUnit.SECONDS,
new LinkedBlockingQueue<>(NettyServerConfig.getMaxTaskQueueSize()),
new NamedThreadFactory("ServerHandlerThread", NettyServerConfig.getMaxServerPoolSize()),
new ThreadPoolExecutor.CallerRunsPolicy());
if (NetUtil.isValidIp(parameterParser.getHost(), false)) {
XID.setIpAddress(parameterParser.getHost());
} else {
String preferredNetworks = ConfigurationFactory.getInstance().getConfig(REGISTRY_PREFERED_NETWORKS);
if (StringUtils.isNotBlank(preferredNetworks)) {
XID.setIpAddress(NetUtil.getLocalIp(preferredNetworks.split(REGEX_SPLIT_CHAR)));
} else {
XID.setIpAddress(NetUtil.getLocalIp());
}
}
NettyRemotingServer nettyRemotingServer = new NettyRemotingServer(workingThreads);
XID.setPort(nettyRemotingServer.getListenPort());
UUIDGenerator.init(parameterParser.getServerNode());
ConfigurableListableBeanFactory beanFactory = ((GenericWebApplicationContext) ObjectHolder.INSTANCE.getObject(OBJECT_KEY_SPRING_APPLICATION_CONTEXT)).getBeanFactory();
DefaultCoordinator coordinator = DefaultCoordinator.getInstance(nettyRemotingServer);
if (coordinator instanceof ApplicationListener) {
beanFactory.registerSingleton(NettyRemotingServer.class.getName(), nettyRemotingServer);
beanFactory.registerSingleton(DefaultCoordinator.class.getName(), coordinator);
((GenericWebApplicationContext) ObjectHolder.INSTANCE.getObject(OBJECT_KEY_SPRING_APPLICATION_CONTEXT)).addApplicationListener((ApplicationListener<?>) coordinator);
}
SessionHolder.init();
LockerManagerFactory.init();
coordinator.init();
nettyRemotingServer.setHandler(coordinator);
serverInstance.serverInstanceInit();
ServerRunner.addDisposable(coordinator);
nettyRemotingServer.init();
}
The final nettyRemotingServer.init() is crucial for starting the entire Seata Server, primarily performing the following tasks:
- Register a series of handlers
- Initialize a scheduled thread pool for cleaning up expired MessageFuture objects
- Start the ServerBootstrap and register the TC service with the registry center, such as Nacos
Registering Processors
Within Seata, a Pair object is used to associate a processor with an executor (thread pool), as shown below:
package org.apache.seata.core.rpc.processor;
public final class Pair<T1, T2> {
private final T1 first;
private final T2 second;
public Pair(T1 first, T2 second) {
this.first = first;
this.second = second;
}
public T1 getFirst() {
return first;
}
public T2 getSecond() {
return second;
}
}
Registering processors essentially involves associating message types, the processors that handle those messages, and the specific thread pools for execution, all stored in a hash table.
protected final Map<Integer, Pair<RemotingProcessor, ExecutorService>> processorTable = new HashMap<>(32);
private void registerProcessor() {
ServerOnRequestProcessor onRequestProcessor = new ServerOnRequestProcessor(this, getHandler());
ShutdownHook.getInstance().addDisposable(onRequestProcessor);
super.registerProcessor(MessageType.TYPE_BRANCH_REGISTER, onRequestProcessor, messageExecutor);
super.registerProcessor(MessageType.TYPE_BRANCH_STATUS_REPORT, onRequestProcessor, messageExecutor);
super.registerProcessor(MessageType.TYPE_GLOBAL_BEGIN, onRequestProcessor, messageExecutor);
super.registerProcessor(MessageType.TYPE_GLOBAL_COMMIT, onRequestProcessor, messageExecutor);
super.registerProcessor(MessageType.TYPE_GLOBAL_LOCK_QUERY, onRequestProcessor, messageExecutor);
super.registerProcessor(MessageType.TYPE_GLOBAL_REPORT, onRequestProcessor, messageExecutor);
super.registerProcessor(MessageType.TYPE_GLOBAL_ROLLBACK, onRequestProcessor, messageExecutor);
super.registerProcessor(MessageType.TYPE_GLOBAL_STATUS, onRequestProcessor, messageExecutor);
super.registerProcessor(MessageType.TYPE_SEATA_MERGE, onRequestProcessor, messageExecutor);
ServerOnResponseProcessor onResponseProcessor = new ServerOnResponseProcessor(getHandler(), getFutures());
super.registerProcessor(MessageType.TYPE_BRANCH_COMMIT_RESULT, onResponseProcessor, branchResultMessageExecutor);
super.registerProcessor(MessageType.TYPE_BRANCH_ROLLBACK_RESULT, onResponseProcessor, branchResultMessageExecutor);
RegRmProcessor regRmProcessor = new RegRmProcessor(this);
super.registerProcessor(MessageType.TYPE_REG_RM, regRmProcessor, messageExecutor);
RegTmProcessor regTmProcessor = new RegTmProcessor(this);
super.registerProcessor(MessageType.TYPE_REG_CLT, regTmProcessor, null);
ServerHeartbeatProcessor heartbeatMessageProcessor = new ServerHeartbeatProcessor(this);
super.registerProcessor(MessageType.TYPE_HEARTBEAT_MSG, heartbeatMessageProcessor, null);
}
public void registerProcessor(int messageType, RemotingProcessor processor, ExecutorService executor) {
Pair<RemotingProcessor, ExecutorService> pair = new Pair<>(processor, executor);
this.processorTable.put(messageType, pair);
}
You might notice that during the registration of some processors, the passed-in thread pool is null. In such cases, which thread will execute the corresponding message?
We will discuss this in a later section.
Initializing the Scheduled Thread Pool
public void init() {
timerExecutor.scheduleAtFixedRate(() -> {
for (Map.Entry<Integer, MessageFuture> entry : futures.entrySet()) {
MessageFuture future = entry.getValue();
if (future.isTimeout()) {
futures.remove(entry.getKey());
RpcMessage rpcMessage = future.getRequestMessage();
future.setResultMessage(new TimeoutException(String.format("msgId: %s, msgType: %s, msg: %s, request timeout",
rpcMessage.getId(), String.valueOf(rpcMessage.getMessageType()), rpcMessage.getBody().toString())));
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("timeout clear future: {}", entry.getValue().getRequestMessage().getBody());
}
}
}
nowMills = System.currentTimeMillis();
}, TIMEOUT_CHECK_INTERVAL, TIMEOUT_CHECK_INTERVAL, TimeUnit.MILLISECONDS);
}
There's not much to explain here—it initializes a scheduled thread pool that periodically cleans up timed-out MessageFuture objects. The MessageFuture is key to Seata converting asynchronous calls into synchronous ones, which we will discuss in detail later.
Starting the ServerBootstrap
Finally, starting the ServerBootstrap is mostly related to Netty.
public void start() {
int port = getListenPort();
this.serverBootstrap.group(this.eventLoopGroupBoss, this.eventLoopGroupWorker)
.channel(NettyServerConfig.SERVER_CHANNEL_CLAZZ)
.option(ChannelOption.SO_BACKLOG, nettyServerConfig.getSoBackLogSize())
.option(ChannelOption.SO_REUSEADDR, true)
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childOption(ChannelOption.TCP_NODELAY, true)
.childOption(ChannelOption.SO_SNDBUF, nettyServerConfig.getServerSocketSendBufSize())
.childOption(ChannelOption.SO_RCVBUF, nettyServerConfig.getServerSocketResvBufSize())
.childOption(ChannelOption.WRITE_BUFFER_WATER_MARK, new WriteBufferWaterMark(nettyServerConfig.getWriteBufferLowWaterMark(), nettyServerConfig.getWriteBufferHighWaterMark()))
.localAddress(new InetSocketAddress(port))
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
MultiProtocolDecoder multiProtocolDecoder = new MultiProtocolDecoder(channelHandlers);
ch.pipeline()
.addLast(new IdleStateHandler(nettyServerConfig.getChannelMaxReadIdleSeconds(), 0, 0))
.addLast(multiProtocolDecoder);
}
});
try {
this.serverBootstrap.bind(port).sync();
LOGGER.info("Server started, service listen port: {}", getListenPort());
InetSocketAddress address = new InetSocketAddress(XID.getIpAddress(), XID.getPort());
for (RegistryService<?> registryService : MultiRegistryFactory.getInstances()) {
registryService.register(address);
}
initialized.set(true);
} catch (SocketException se) {
throw new RuntimeException("Server start failed, the listen port: " + getListenPort(), se);
} catch (Exception exx) {
throw new RuntimeException("Server start failed", exx);
}
}
The childOption settings during the startup of ServerBootstrap belong to the networking part and won't be explained in depth here.
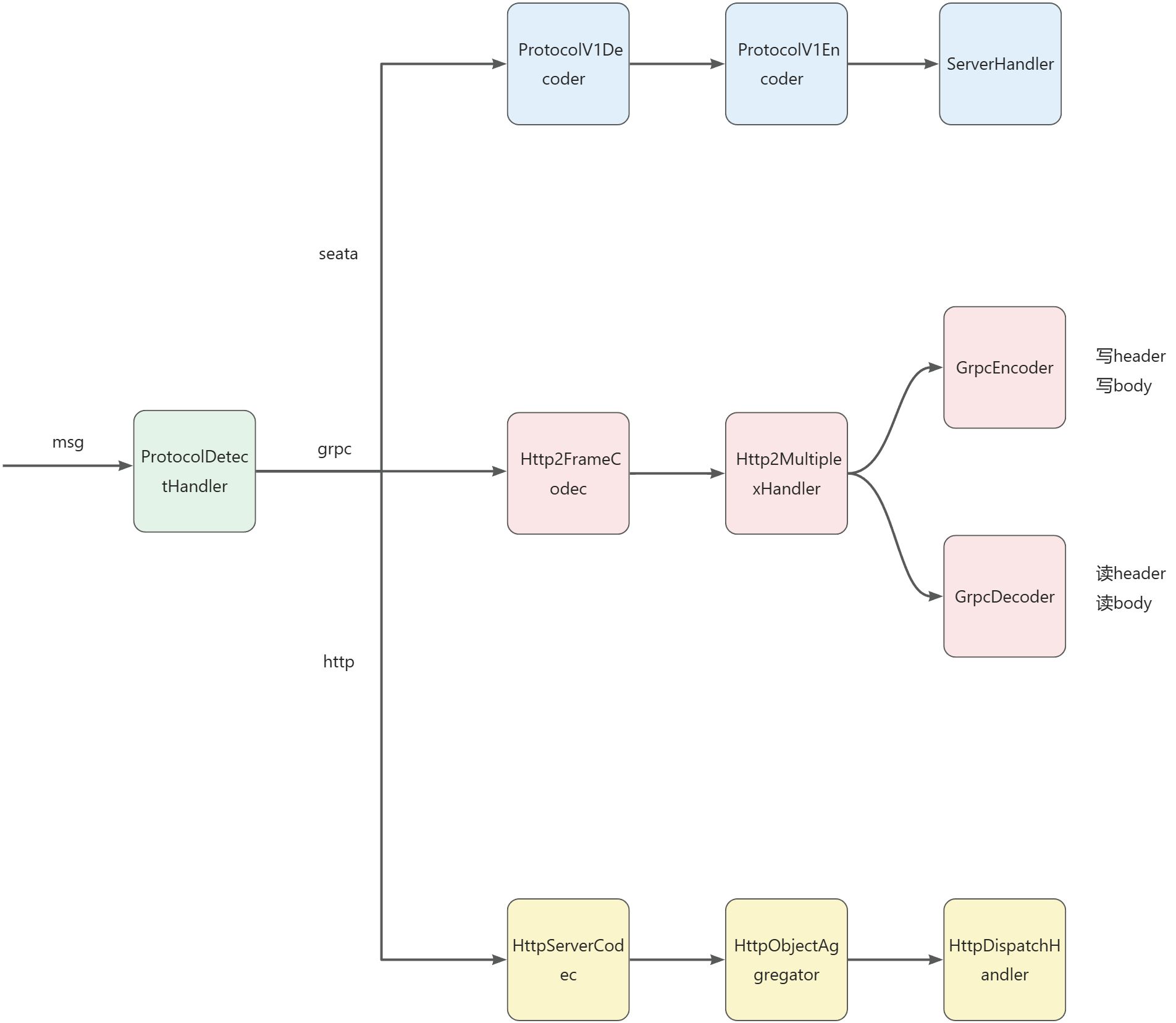
You might have a question regarding why only a MultiProtocolDecoder is added to the pipeline, what about the business handler?
In fact, the channelHandlers passed into the constructor of MultiProtocolDecoder include the ServerHandler, which is set when creating the NettyRemotingServer.
This approach is related to Seata's multi-version protocol support.
When the Seata Server decodes messages for the first time after starting, it removes the MultiProtocolDecoder from the pipeline and adds specific Encoder and Decoder based on the version to the pipeline. At this point, the ServerHandler is also added to the pipeline.
How the Client Starts
For the Client, since we typically use Seata within a Spring Boot application, our focus lies within the SeataAutoConfiguration class.
In this class, a GlobalTransactionScanner object is created. Notably, it implements InitializingBean, so we turn our attention to the afterPropertiesSet method.
Indeed, within this method, the initialization of TM (Transaction Manager) and RM (Resource Manager) takes place.
Initialization of TM
For TM, the initialization logic is as follows:
public static void init(String applicationId, String transactionServiceGroup, String accessKey, String secretKey) {
TmNettyRemotingClient tmNettyRemotingClient = TmNettyRemotingClient.getInstance(applicationId, transactionServiceGroup, accessKey, secretKey);
tmNettyRemotingClient.init();
}
The logic for starting the client Bootstrap is as follows:
@Override
public void start() {
if (this.defaultEventExecutorGroup == null) {
this.defaultEventExecutorGroup = new DefaultEventExecutorGroup(nettyClientConfig.getClientWorkerThreads(),
new NamedThreadFactory(getThreadPrefix(nettyClientConfig.getClientWorkerThreadPrefix()), nettyClientConfig.getClientWorkerThreads()));
}
this.bootstrap.group(this.eventLoopGroupWorker)
.channel(nettyClientConfig.getClientChannelClazz())
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.SO_KEEPALIVE, true)
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, nettyClientConfig.getConnectTimeoutMillis())
.option(ChannelOption.SO_SNDBUF, nettyClientConfig.getClientSocketSndBufSize())
.option(ChannelOption.SO_RCVBUF, nettyClientConfig.getClientSocketRcvBufSize());
if (nettyClientConfig.enableNative()) {
if (PlatformDependent.isOsx()) {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("client run on macOS");
}
} else {
bootstrap.option(EpollChannelOption.EPOLL_MODE, EpollMode.EDGE_TRIGGERED)
.option(EpollChannelOption.TCP_QUICKACK, true);
}
}
bootstrap.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline().addLast(new IdleStateHandler(nettyClientConfig.getChannelMaxReadIdleSeconds(),
nettyClientConfig.getChannelMaxWriteIdleSeconds(),
nettyClientConfig.getChannelMaxAllIdleSeconds()))
.addLast(new ProtocolDecoderV1())
.addLast(new ProtocolEncoderV1());
if (channelHandlers != null) {
addChannelPipelineLast(ch, channelHandlers);
}
}
});
if (initialized.compareAndSet(false, true) && LOGGER.isInfoEnabled()) {
LOGGER.info("NettyClientBootstrap has started");
}
}
Since the protocol version for the client can be determined based on different versions of Seata, V1 version encoders and decoders are directly added here. The channelHandlers are actually the ClientHandler, which is also a composite handler in Netty.
Initialization of RM
The initialization logic for RM is largely similar to that of TM and will not be elaborated on further here.
How Messages Are Sent and Handled
After understanding the general startup processes of the Seata Server and Client, we can delve deeper into how Seata sends and handles messages.
We mentioned earlier that the core logic for sending requests and processing messages lies within AbstractNettyRemoting. Let's take a closer look at this class.
Synchronous and Asynchronous
First, let's briefly discuss what synchronous and asynchronous mean.
Synchronous (Synchronous) and Asynchronous (Asynchronous), in essence, describe different behavior patterns when a program handles multiple events or tasks.
Synchronous means one process must wait for another to complete before it can proceed. In other words, in synchronous operations, the caller will block waiting for a response after issuing a request until it receives a response result or times out before continuing with subsequent code execution.
In contrast, asynchronous allows the caller to continue executing without waiting for a response after making a request, but when the request is completed, it notifies the caller of the response in some way (such as through callback functions or Future). The asynchronous model can improve concurrency and efficiency.
From another perspective, synchronous calls require the calling thread to obtain the result, whereas asynchronous calls either have an asynchronous thread place the result somewhere (Future) or execute pre-prepared call success/failure callback methods (callback function).
Below is a simple example demonstrating three invocation styles: synchronous, asynchronous with Future, and asynchronous with Callback.
import lombok.Data;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
public class AsyncTest {
private static final Logger LOGGER = LoggerFactory.getLogger(AsyncTest.class);
public static void main(String[] args) throws InterruptedException, ExecutionException {
Result syncResponse = testSync();
LOGGER.info("Synchronous response result: {}", syncResponse.getString());
CompletableFuture<Result> result = testAsyncFuture();
testAsyncCallback();
LOGGER.info("Main thread continues executing~~");
TimeUnit.SECONDS.sleep(1);
LOGGER.info("Main thread retrieves result from async Future: {}", result.get().getString());
}
public static void testAsyncCallback() {
new AsyncTask().execute(new AsyncCallback() {
@Override
public void onComplete(Result result) {
try {
TimeUnit.MILLISECONDS.sleep(50);
} catch (InterruptedException e) {
}
LOGGER.info("Async Callback gets result: {}", result.getString());
}
});
}
public static CompletableFuture<Result> testAsyncFuture() {
return CompletableFuture.supplyAsync(() -> {
try {
TimeUnit.MILLISECONDS.sleep(50);
} catch (InterruptedException e) {
}
Result asyncResponse = getResult();
LOGGER.info("Async Future gets result: {}", asyncResponse.getString());
return asyncResponse;
});
}
public static Result testSync() {
return getResult();
}
@Data
static class Result {
private String string;
}
interface AsyncCallback {
void onComplete(Result result);
}
static class AsyncTask {
void execute(AsyncCallback callback) {
new Thread(() -> {
Result asyncRes = getResult();
callback.onComplete(asyncRes);
}).start();
}
}
private static Result getResult() {
Result result = new Result();
result.setString("result");
return result;
}
}
Output:
22:26:38.788 [main] INFO org.hein.netty.AsyncTest - Synchronous response result: result
22:26:38.849 [main] INFO org.hein.netty.AsyncTest - Main thread continues executing~~
22:26:38.911 [Thread-0] INFO org.hein.netty.AsyncTest - Async Callback gets result: result
22:26:38.911 [ForkJoinPool.commonPool-worker-1] INFO org.hein.netty.AsyncTest - Async Future gets result: result
22:26:39.857 [main] INFO org.hein.netty.AsyncTest - Main thread retrieves result from async Future: result
From the output, we can observe at least three points:
- One is that asynchronous Future and asynchronous Callback do not block the main thread from continuing its execution.
- Two, the handling of results during asynchronous calls is not done by the main thread.
- Finally, the difference between Future and Callback lies in that Future has the asynchronous thread store the result in a specific location (CompletableFuture#result), but retrieving the result still requires the main thread (or another thread) to call the get method. With Callback, it's essentially setting up the predefined way to handle the result, which is executed by the asynchronous thread.
Of course, CompletableFuture can also be used for callbacks, for example, by calling the whenComplete method.
Asynchronous Invocation
Netty, as a high-performance asynchronous IO framework, is designed to be asynchronous at its core. Therefore, implementing asynchronous calls based on Netty is relatively straightforward.
protected void sendAsync(Channel channel, RpcMessage rpcMessage) {
channelWritableCheck(channel, rpcMessage.getBody());
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("write message: {}, channel: {}, active? {}, writable? {}, isopen? {}", rpcMessage.getBody(), channel, channel.isActive(), channel.isWritable(), channel.isOpen());
}
doBeforeRpcHooks(ChannelUtil.getAddressFromChannel(channel), rpcMessage);
channel.writeAndFlush(rpcMessage).addListener((ChannelFutureListener) future -> {
if (!future.isSuccess()) {
destroyChannel(future.channel());
}
});
}
An asynchronous call can be achieved by simply invoking the writeAndFlush method of the channel.
It's important to note that the writeAndFlush method will operate synchronously when called from an EventLoop thread.
Synchronous Invocation
Implementing asynchronous calls in Netty is simple, but converting them into synchronous calls requires more effort since it involves transforming an asynchronous call into a synchronous one.
Essentially, converting asynchronous to synchronous means that after the calling thread initiates a call, it should block until it receives a response, and then it continues execution.
The core of Seata's handling for this conversion lies within the MessageFuture class, as follows:
package org.apache.seata.core.protocol;
import org.apache.seata.common.exception.ShouldNeverHappenException;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
public class MessageFuture {
private RpcMessage requestMessage;
private long timeout;
private final long start = System.currentTimeMillis();
private final transient CompletableFuture<Object> origin = new CompletableFuture<>();
public boolean isTimeout() {
return System.currentTimeMillis() - start > timeout;
}
public Object get(long timeout, TimeUnit unit) throws TimeoutException, InterruptedException {
Object result;
try {
result = origin.get(timeout, unit);
if (result instanceof TimeoutException) {
throw (TimeoutException) result;
}
} catch (ExecutionException e) {
throw new ShouldNeverHappenException("Should not get results in a multi-threaded environment", e);
} catch (TimeoutException e) {
throw new TimeoutException(String.format("%s, cost: %d ms", e.getMessage(), System.currentTimeMillis() - start));
}
if (result instanceof RuntimeException) {
throw (RuntimeException) result;
} else if (result instanceof Throwable) {
throw new RuntimeException((Throwable) result);
}
return result;
}
public void setResultMessage(Object obj) {
origin.complete(obj);
}
public RpcMessage getRequestMessage() { return requestMessage; }
public void setRequestMessage(RpcMessage requestMessage) { this.requestMessage = requestMessage;}
public long getTimeout() { return timeout; }
public void setTimeout(long timeout) { this.timeout = timeout;}
}
With this class, the process of a synchronous call works as follows, using a client request and server response as an example:
- First, the client constructs the request into a
MessageFuture, then stores the request ID along with this MessageFuture object in a hash table.
- The client then calls
channel.writeAndFlush to initiate an asynchronous call. Yes, it's still asynchronous at this point.
- The key to converting asynchronous to synchronous lies in the fact that the thread needs to call the
get method on the MessageFuture object, which blocks the thread, effectively calling the get method on CompletableFuture to enter a blocking state.
- When the server finishes processing and sends a request from its perspective, the client sees this as a response.
- When the client receives the response, the EventLoop thread sets the response result in the
MessageFuture. Since the request and response IDs are the same, the corresponding MessageFuture object can be retrieved from the aforementioned hash table.
- Once the response result is set, the previously blocked thread can resume execution, thereby achieving a synchronous effect.
Thus, Seata's solution essentially uses CompletableFuture objects as containers for storing results.
protected Object sendSync(Channel channel, RpcMessage rpcMessage, long timeoutMillis) throws TimeoutException {
if (timeoutMillis <= 0) {
throw new FrameworkException("timeout should more than 0ms");
}
if (channel == null) {
LOGGER.warn("sendSync nothing, caused by null channel.");
return null;
}
MessageFuture messageFuture = new MessageFuture();
messageFuture.setRequestMessage(rpcMessage);
messageFuture.setTimeout(timeoutMillis);
futures.put(rpcMessage.getId(), messageFuture);
channelWritableCheck(channel, rpcMessage.getBody());
String remoteAddr = ChannelUtil.getAddressFromChannel(channel);
doBeforeRpcHooks(remoteAddr, rpcMessage);
channel.writeAndFlush(rpcMessage).addListener((ChannelFutureListener) future -> {
if (!future.isSuccess()) {
MessageFuture mf = futures.remove(rpcMessage.getId());
if (mf != null) {
mf.setResultMessage(future.cause());
}
destroyChannel(future.channel());
}
});
try {
Object result = messageFuture.get(timeoutMillis, TimeUnit.MILLISECONDS);
doAfterRpcHooks(remoteAddr, rpcMessage, result);
return result;
} catch (Exception exx) {
LOGGER.error("wait response error:{},ip:{},request:{}", exx.getMessage(), channel.remoteAddress(), rpcMessage.getBody());
if (exx instanceof TimeoutException) {
throw (TimeoutException) exx;
} else {
throw new RuntimeException(exx);
}
}
}
Message Handling
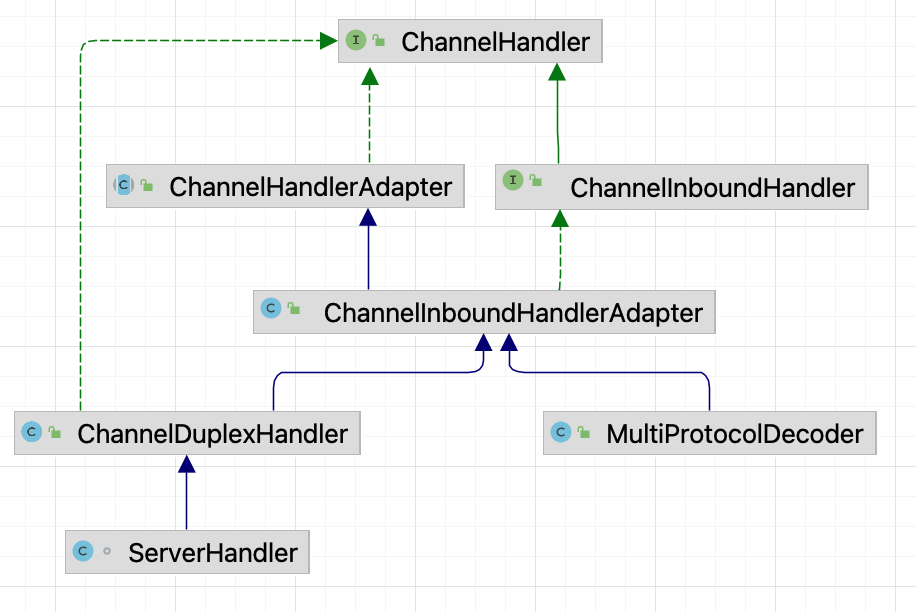
When it comes to message handling in Netty, one should think of inbound and outbound handlers first.
In the Seata Server side, besides common encoding and decoding handlers, there is also the ServerHandler. Here's an example:
@ChannelHandler.Sharable
class ServerHandler extends ChannelDuplexHandler {
@Override
public void channelRead(final ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof RpcMessage) {
processMessage(ctx, (RpcMessage) msg);
} else {
LOGGER.error("rpcMessage type error");
}
}
}
The channelRead method has significant business meaning, as all messages sent to the Server will come to this method after being decoded.
The processMessage method within this context refers to the business processing method found in AbstractNettyRemoting, as follows:
protected void processMessage(ChannelHandlerContext ctx, RpcMessage rpcMessage) throws Exception {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("{} msgId: {}, body: {}", this, rpcMessage.getId(), rpcMessage.getBody());
}
Object body = rpcMessage.getBody();
if (body instanceof MessageTypeAware) {
MessageTypeAware messageTypeAware = (MessageTypeAware) body;
final Pair<RemotingProcessor, ExecutorService> pair = this.processorTable.get((int) messageTypeAware.getTypeCode());
if (pair != null) {
if (pair.getSecond() != null) {
try {
pair.getSecond().execute(() -> {
try {
pair.getFirst().process(ctx, rpcMessage);
} catch (Throwable th) {
LOGGER.error(FrameworkErrorCode.NetDispatch.getErrCode(), th.getMessage(), th);
} finally {
MDC.clear();
}
});
} catch (RejectedExecutionException e) {
LOGGER.error(FrameworkErrorCode.ThreadPoolFull.getErrCode(), "thread pool is full, current max pool size is " + messageExecutor.getActiveCount());
if (allowDumpStack) {
String name = ManagementFactory.getRuntimeMXBean().getName();
String pid = name.split("@")[0];
long idx = System.currentTimeMillis();
try {
String jstackFile = idx + ".log";
LOGGER.info("jstack command will dump to {}", jstackFile);
Runtime.getRuntime().exec(String.format("jstack %s > %s", pid, jstackFile));
} catch (IOException exx) {
LOGGER.error(exx.getMessage());
}
allowDumpStack = false;
}
}
} else {
try {
pair.getFirst().process(ctx, rpcMessage);
} catch (Throwable th) {
LOGGER.error(FrameworkErrorCode.NetDispatch.getErrCode(), th.getMessage(), th);
}
}
} else {
LOGGER.error("This message type [{}] has no processor.", messageTypeAware.getTypeCode());
}
} else {
LOGGER.error("This rpcMessage body[{}] is not MessageTypeAware type.", body);
}
}
The logic of this method is quite straightforward.
During the startup process of Seata Server, a multitude of processors are registered into the processorTable, so here we can obtain the corresponding processor and thread pool based on the message type code.
If there is a thread pool, the processor's method is executed within that thread pool; otherwise, it is handed over to the EventLoop thread for execution.
Of course, the same approach applies to the Client.
Batch Sending
In network programming, there are times when batch sending is also required. Let's see how Seata implements this, focusing on the client sending to the server.
Recall that during the Client startup process, we mentioned a thread pool mergeSendExecutorService. If batch sending is allowed, then upon Client startup, a MergedSendRunnable task is submitted. First, let's look at what this task does:
private class MergedSendRunnable implements Runnable {
@Override
public void run() {
while (true) {
synchronized (mergeLock) {
try {
mergeLock.wait(MAX_MERGE_SEND_MILLS);
} catch (InterruptedException ignore) {
}
}
isSending = true;
basketMap.forEach((address, basket) -> {
if (basket.isEmpty()) {
return;
}
MergedWarpMessage mergeMessage = new MergedWarpMessage();
while (!basket.isEmpty()) {
RpcMessage msg = basket.poll();
mergeMessage.msgs.add((AbstractMessage) msg.getBody());
mergeMessage.msgIds.add(msg.getId());
}
if (mergeMessage.msgIds.size() > 1) {
printMergeMessageLog(mergeMessage);
}
Channel sendChannel = null;
try {
sendChannel = clientChannelManager.acquireChannel(address);
AbstractNettyRemotingClient.this.sendAsyncRequest(sendChannel, mergeMessage);
} catch (FrameworkException e) {
if (e.getErrorCode() == FrameworkErrorCode.ChannelIsNotWritable && sendChannel != null) {
destroyChannel(address, sendChannel);
}
for (Integer msgId : mergeMessage.msgIds) {
MessageFuture messageFuture = futures.remove(msgId);
if (messageFuture != null) {
messageFuture.setResultMessage(new RuntimeException(String.format("%s is unreachable", address), e));
}
}
LOGGER.error("client merge call failed: {}", e.getMessage(), e);
}
});
isSending = false;
}
}
}
The related batch sending code follows:
public Object sendSyncRequest(Object msg) throws TimeoutException {
String serverAddress = loadBalance(getTransactionServiceGroup(), msg);
long timeoutMillis = this.getRpcRequestTimeout();
RpcMessage rpcMessage = buildRequestMessage(msg, ProtocolConstants.MSGTYPE_RESQUEST_SYNC);
if (this.isEnableClientBatchSendRequest()) {
MessageFuture messageFuture = new MessageFuture();
messageFuture.setRequestMessage(rpcMessage);
messageFuture.setTimeout(timeoutMillis);
futures.put(rpcMessage.getId(), messageFuture);
BlockingQueue<RpcMessage> basket = CollectionUtils.computeIfAbsent(basketMap, serverAddress,
key -> new LinkedBlockingQueue<>());
if (!basket.offer(rpcMessage)) {
LOGGER.error("put message into basketMap offer failed, serverAddress: {}, rpcMessage: {}", serverAddress, rpcMessage);
return null;
}
if (!isSending) {
synchronized (mergeLock) {
mergeLock.notifyAll();
}
}
try {
return messageFuture.get(timeoutMillis, TimeUnit.MILLISECONDS);
} catch (Exception exx) {
LOGGER.error("wait response error: {}, ip: {}, request: {}", exx.getMessage(), serverAddress, rpcMessage.getBody());
if (exx instanceof TimeoutException) {
throw (TimeoutException) exx;
} else {
throw new RuntimeException(exx);
}
}
} else {
Channel channel = clientChannelManager.acquireChannel(serverAddress);
return super.sendSync(channel, rpcMessage, timeoutMillis);
}
}
As can be seen, object lock synchronization-wait mechanisms are used here, resulting in the following effects:
- Messages are sent by traversing the
basketMap every 1ms at most.
- During the blocking period of threads inside
mergeSendExecutorService (mainLock.wait), if a message that needs to be sent arrives, the thread on mainLock is awakened to continue sending.
How does the Server handle this? It mainly looks at the TypeCode of the MergedWarpMessage, which is actually TYPE_SEATA_MERGE. During Server startup, the processor registered for this Code is actually ServerOnRequestProcessor.
This shows you how to find out how a certain message is processed; teaching you how to fish is better than giving you fish!
On the ServerOnRequestProcessor side, there are actually two ways to handle MergedWarpMessage messages:
- After processing all individual requests within
MergedWarpMessage, send a unified MergeResultMessage.
- Handle the sending task with the
batchResponseExecutorService thread pool, ensuring two points: one is to respond immediately when there is a message result, even if the thread is waiting, it will notify it, and secondly, it responds at least once every 1ms because the thread executing within batchResponseExecutorService waits for no more than 1ms.
Note that these two methods respond with different message types; the first responds with MergeResultMessage, and the second with BatchResultMessage, each handled differently on the Client side.
The core processing method within ServerOnRequestProcessor is as follows:
private void onRequestMessage(ChannelHandlerContext ctx, RpcMessage rpcMessage) {
Object message = rpcMessage.getBody();
RpcContext rpcContext = ChannelManager.getContextFromIdentified(ctx.channel());
if (message instanceof MergedWarpMessage) {
final List<AbstractMessage> msgs = ((MergedWarpMessage) message).msgs;
final List<Integer> msgIds = ((MergedWarpMessage) message).msgIds;
if (NettyServerConfig.isEnableTcServerBatchSendResponse() && StringUtils.isNotBlank(rpcContext.getVersion())
&& Version.isAboveOrEqualVersion150(rpcContext.getVersion())) {
for (int i = 0; i < msgs.size(); i++) {
if (PARALLEL_REQUEST_HANDLE) {
int finalI = i;
CompletableFuture.runAsync(
() -> handleRequestsByMergedWarpMessageBy150(msgs.get(finalI), msgIds.get(finalI), rpcMessage, ctx, rpcContext));
} else {
handleRequestsByMergedWarpMessageBy150(msgs.get(i), msgIds.get(i), rpcMessage, ctx, rpcContext);
}
}
} else {
List<AbstractResultMessage> results = new ArrayList<>();
List<CompletableFuture<AbstractResultMessage>> futures = new ArrayList<>();
for (int i = 0; i < msgs.size(); i++) {
if (PARALLEL_REQUEST_HANDLE) {
int finalI = i;
futures.add(CompletableFuture.supplyAsync(() -> handleRequestsByMergedWarpMessage(msgs.get(finalI), rpcContext)));
} else {
results.add(i, handleRequestsByMergedWarpMessage(msgs.get(i), rpcContext));
}
}
if (CollectionUtils.isNotEmpty(futures)) {
try {
for (CompletableFuture<AbstractResultMessage> future : futures) {
results.add(future.get());
}
} catch (InterruptedException | ExecutionException e) {
LOGGER.error("handle request error: {}", e.getMessage(), e);
}
}
MergeResultMessage resultMessage = new MergeResultMessage();
resultMessage.setMsgs(results.toArray(new AbstractResultMessage[0]));
remotingServer.sendAsyncResponse(rpcMessage, ctx.channel(), resultMessage);
}
} else {
}
}
The difference between handleRequestsByMergedWarpMessage and handleRequestsByMergedWarpMessageBy150 lies in the fact that the latter encapsulates the result into a QueueItem and adds it to a blocking queue for actual sending by threads in batchResponseExecutorService, while the former simply returns the processing result.
private AbstractResultMessage handleRequestsByMergedWarpMessage(AbstractMessage subMessage, RpcContext rpcContext) {
AbstractResultMessage resultMessage = transactionMessageHandler.onRequest(subMessage, rpcContext);
return resultMessage;
}
private void handleRequestsByMergedWarpMessageBy150(AbstractMessage msg, int msgId, RpcMessage rpcMessage,
ChannelHandlerContext ctx, RpcContext rpcContext) {
AbstractResultMessage resultMessage = transactionMessageHandler.onRequest(msg, rpcContext);
BlockingQueue<QueueItem> msgQueue = CollectionUtils.computeIfAbsent(basketMap, ctx.channel(), key -> new LinkedBlockingQueue<>());
if (!msgQueue.offer(new QueueItem(resultMessage, msgId, rpcMessage))) {
LOGGER.error("put message into basketMap offer failed, channel: {}, rpcMessage: {}, resultMessage: {}", ctx.channel(), rpcMessage, resultMessage);
}
if (!isResponding) {
synchronized (batchResponseLock) {
batchResponseLock.notifyAll();
}
}
}
Now, let's look at how the batchResponseExecutorService thread pool handles batch sending tasks:
private class BatchResponseRunnable implements Runnable {
@Override
public void run() {
while (true) {
synchronized (batchResponseLock) {
try {
batchResponseLock.wait(MAX_BATCH_RESPONSE_MILLS);
} catch (InterruptedException e) {
LOGGER.error("BatchResponseRunnable Interrupted error", e);
}
}
isResponding = true;
basketMap.forEach((channel, msgQueue) -> {
if (msgQueue.isEmpty()) {
return;
}
Map<ClientRequestRpcInfo, BatchResultMessage> batchResultMessageMap = new HashMap<>();
while (!msgQueue.isEmpty()) {
QueueItem item = msgQueue.poll();
BatchResultMessage batchResultMessage = CollectionUtils.computeIfAbsent(batchResultMessageMap,
new ClientRequestRpcInfo(item.getRpcMessage()),
key -> new BatchResultMessage());
batchResultMessage.getResultMessages().add(item.getResultMessage());
batchResultMessage.getMsgIds().add(item.getMsgId());
}
batchResultMessageMap.forEach((clientRequestRpcInfo, batchResultMessage) ->
remotingServer.sendAsyncResponse(buildRpcMessage(clientRequestRpcInfo), channel, batchResultMessage));
});
isResponding = false;
}
}
}
Finally, let's see how the Client side processes Server's batch response messages. According to the processor registered by the Client, the processor handling batch messages is ClientOnResponseProcessor, as follows:
public void process(ChannelHandlerContext ctx, RpcMessage rpcMessage) throws Exception {
if (rpcMessage.getBody() instanceof MergeResultMessage) {
MergeResultMessage results = (MergeResultMessage) rpcMessage.getBody();
MergedWarpMessage mergeMessage = (MergedWarpMessage) mergeMsgMap.remove(rpcMessage.getId());
for (int i = 0; i < mergeMessage.msgs.size(); i++) {
int msgId = mergeMessage.msgIds.get(i);
MessageFuture future = futures.remove(msgId);
if (future == null) {
LOGGER.error("msg: {} is not found in futures, result message: {}", msgId, results.getMsgs()[i]);
} else {
future.setResultMessage(results.getMsgs()[i]);
}
}
} else if (rpcMessage.getBody() instanceof BatchResultMessage) {
try {
BatchResultMessage batchResultMessage = (BatchResultMessage) rpcMessage.getBody();
for (int i = 0; i < batchResultMessage.getMsgIds().size(); i++) {
int msgId = batchResultMessage.getMsgIds().get(i);
MessageFuture future = futures.remove(msgId);
if (future == null) {
LOGGER.error("msg: {} is not found in futures, result message: {}", msgId, batchResultMessage.getResultMessages().get(i));
} else {
future.setResultMessage(batchResultMessage.getResultMessages().get(i));
}
}
} finally {
mergeMsgMap.clear();
}
} else {
MessageFuture messageFuture = futures.remove(rpcMessage.getId());
if (messageFuture != null) {
messageFuture.setResultMessage(rpcMessage.getBody());
} else {
if (rpcMessage.getBody() instanceof AbstractResultMessage) {
if (transactionMessageHandler != null) {
transactionMessageHandler.onResponse((AbstractResultMessage) rpcMessage.getBody(), null);
}
}
}
}
}
Of course, the logic here is quite simple: it involves putting the results into the corresponding MessageFuture, so the initially blocked thread that sent the request can obtain the result, thereby completing one cycle of batch sending and response handling.
Let's do some extra thinking: Why does Seata have two methods for batch sending, and which is better?
For the MergeResultMessage approach, it must wait until all messages have been processed before sending them out, so its response speed is limited by the longest-processing message, even if other messages could be sent out much sooner.
However, the BatchResultMessage approach differs in that it can achieve sending as soon as a message is processed, without waiting for other messages, thanks to parallel processing with CompletableFuture. This method definitely responds faster.
The latter approach was introduced in Seata version 1.5 onwards, which can be seen as a better way to handle batch sending.
Lastly, sharing an interaction flow diagram for global transaction commit requests by the author of the Seata RPC refactoring would be beneficial.
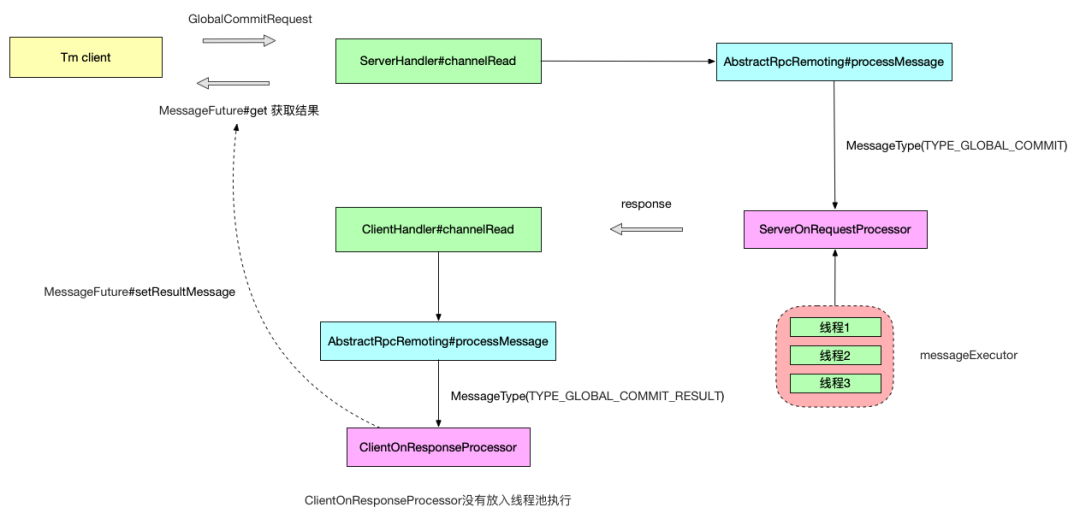
How Seata Manages Channel
Throughout the network communication process involving TC, TM, and RM, Channel is a critical communication component. To understand how Seata manages Channels, the easiest approach is to examine where the Server and Client obtain the Channel when sending messages.
In the sendSyncRequest method of the AbstractNettyRemotingClient class, we can see the following code:
public Object sendSyncRequest(Object msg) throws TimeoutException {
Channel channel = clientChannelManager.acquireChannel(serverAddress);
return super.sendSync(channel, rpcMessage, timeoutMillis);
}
And in the sendSyncRequest method of the AbstractNettyRemotingServer class, we can see the following code:
public Object sendSyncRequest(String resourceId, String clientId, Object msg, boolean tryOtherApp) throws TimeoutException {
Channel channel = ChannelManager.getChannel(resourceId, clientId, tryOtherApp);
if (channel == null) {
throw new RuntimeException("rm client is not connected. dbkey:" + resourceId + ",clientId:" + clientId);
}
RpcMessage rpcMessage = buildRequestMessage(msg, ProtocolConstants.MSGTYPE_RESQUEST_SYNC);
return super.sendSync(channel, rpcMessage, NettyServerConfig.getRpcRequestTimeout());
}
Therefore, on the Client side, it mainly acquires Channels through NettyClientChannelManager, while the Server retrieves Channels from ChannelManager based on resourceId and clientId.
So, below we will primarily investigate these two classes along with some related logic.
Client Channel
Let's first look at how Channels are managed on the Client side; the core class here is NettyClientChannelManager.
First, let's take a simple look at the attributes of this class,
private final ConcurrentMap<String, Object> channelLocks = new ConcurrentHashMap<>();
private final ConcurrentMap<String, NettyPoolKey> poolKeyMap = new ConcurrentHashMap<>();
private final ConcurrentMap<String, Channel> channels = new ConcurrentHashMap<>();
private final GenericKeyedObjectPool<NettyPoolKey, Channel> nettyClientKeyPool;
private final Function<String, NettyPoolKey> poolKeyFunction;
Core Classes of the Object Pool
Seata uses GenericKeyedObjectPool as the object pool managing Channels.
GenericKeyedObjectPool is an implementation from the Apache Commons Pool library, primarily used for managing a set of object pools, each distinguished by a unique Key. It can support pooling requirements for multiple types of objects.
When using GenericKeyedObjectPool, it's typically necessary to configure a KeyedPoolableObjectFactory. This factory defines how to create, validate, activate, passivate, and destroy objects within the pool.
When GenericKeyedObjectPool needs to create an object, it calls the makeObject method of the KeyedPoolableObjectFactory factory, and when it needs to destroy an object, it calls the destroyObject method to destroy it……
How to Pool Channel
The object being pooled is the Channel, and the corresponding Key is NettyPoolKey, as follows:
public class NettyPoolKey {
private TransactionRole transactionRole;
private String address;
private AbstractMessage message;
}
In NettyPoolKey, three pieces of information are maintained: the transaction role (TM, RM, Server), the target TC Server address, and the RPC message sent by the Client when connecting to the Server.
How is this NettyPoolKey created? In Seata, the client actually has two roles, TM and RM, and the creation logic for each will be different. Therefore, Seata abstracts a method in AbstractNettyRemotingClient whose return value is a functional interface that encapsulates the logic for creating a NettyPoolKey based on serverAddress.
protected abstract Function<String, NettyPoolKey> getPoolKeyFunction();
For example, the implementation in TM is:
protected Function<String, NettyPoolKey> getPoolKeyFunction() {
return severAddress -> {
RegisterTMRequest message = new RegisterTMRequest(applicationId, transactionServiceGroup, getExtraData());
return new NettyPoolKey(NettyPoolKey.TransactionRole.TM_ROLE, severAddress, message);
};
}
And the implementation in RM is:
protected Function<String, NettyPoolKey> getPoolKeyFunction() {
return serverAddress -> {
String resourceIds = getMergedResourceKeys();
if (resourceIds != null && LOGGER.isInfoEnabled()) {
LOGGER.info("RM will register: {}", resourceIds);
}
RegisterRMRequest message = new RegisterRMRequest(applicationId, transactionServiceGroup);
message.setResourceIds(resourceIds);
return new NettyPoolKey(NettyPoolKey.TransactionRole.RM_ROLE, serverAddress, message);
};
}
From here, you can see that the message sent by TM after connecting to the Server is RegisterTMRequest, while for RM it is RegisterRMRequest.
When is this functional interface called? We'll look at that later.
We also mentioned earlier that an object pool comes with a corresponding object creation factory KeyedPoolableObjectFactory. In Seata, NettyPoolableFactory extends KeyedPoolableObjectFactory to implement this.
public class NettyPoolableFactory implements KeyedPoolableObjectFactory<NettyPoolKey, Channel> {
@Override
public Channel makeObject(NettyPoolKey key) {
InetSocketAddress address = NetUtil.toInetSocketAddress(key.getAddress());
Channel tmpChannel = clientBootstrap.getNewChannel(address);
long start = System.currentTimeMillis();
Object response;
Channel channelToServer = null;
if (key.getMessage() == null) {
throw new FrameworkException("register msg is null, role:" + key.getTransactionRole().name());
}
try {
response = rpcRemotingClient.sendSyncRequest(tmpChannel, key.getMessage());
if (!isRegisterSuccess(response, key.getTransactionRole())) {
rpcRemotingClient.onRegisterMsgFail(key.getAddress(), tmpChannel, response, key.getMessage());
} else {
channelToServer = tmpChannel;
rpcRemotingClient.onRegisterMsgSuccess(key.getAddress(), tmpChannel, response, key.getMessage());
}
} catch (Exception exx) {
if (tmpChannel != null) {
tmpChannel.close();
}
throw new FrameworkException("register " + key.getTransactionRole().name() + " error, errMsg:" + exx.getMessage());
}
return channelToServer;
}
@Override
public void destroyObject(NettyPoolKey key, Channel channel) throws Exception {
if (channel != null) {
channel.disconnect();
channel.close();
}
}
@Override
public boolean validateObject(NettyPoolKey key, Channel obj) {
if (obj != null && obj.isActive()) {
return true;
}
return false;
}
@Override
public void activateObject(NettyPoolKey key, Channel obj) throws Exception {}
@Override
public void passivateObject(NettyPoolKey key, Channel obj) throws Exception {}
}
Acquiring Channel
Throughout the Seata client, there are three ways to acquire a Channel: initialization, scheduled reconnection, and acquiring Channel when sending messages.
private void initConnection() {
boolean failFast =
ConfigurationFactory.getInstance().getBoolean(ConfigurationKeys.ENABLE_TM_CLIENT_CHANNEL_CHECK_FAIL_FAST, DefaultValues.DEFAULT_CLIENT_CHANNEL_CHECK_FAIL_FAST);
getClientChannelManager().initReconnect(transactionServiceGroup, failFast);
}
public void init() {
timerExecutor.scheduleAtFixedRate(() -> {
try {
clientChannelManager.reconnect(getTransactionServiceGroup());
} catch (Exception ex) {
LOGGER.warn("reconnect server failed. {}", ex.getMessage());
}
}, SCHEDULE_DELAY_MILLS, SCHEDULE_INTERVAL_MILLS, TimeUnit.MILLISECONDS);
}
public Object sendSyncRequest(Object msg) throws TimeoutException {
Channel channel = clientChannelManager.acquireChannel(serverAddress);
return super.sendSync(channel, rpcMessage, timeoutMillis);
}
However, these three entry points will eventually call the acquireChannel method of clientChannelManager to obtain a Channel.
Channel acquireChannel(String serverAddress) {
Channel channelToServer = channels.get(serverAddress);
if (channelToServer != null) {
channelToServer = getExistAliveChannel(channelToServer, serverAddress);
if (channelToServer != null) {
return channelToServer;
}
}
Object lockObj = CollectionUtils.computeIfAbsent(channelLocks, serverAddress, key -> new Object());
synchronized (lockObj) {
return doConnect(serverAddress);
}
}
private Channel doConnect(String serverAddress) {
Channel channelToServer = channels.get(serverAddress);
if (channelToServer != null && channelToServer.isActive()) {
return channelToServer;
}
Channel channelFromPool;
try {
NettyPoolKey currentPoolKey = poolKeyFunction.apply(serverAddress);
poolKeyMap.put(serverAddress, currentPoolKey);
channelFromPool = nettyClientKeyPool.borrowObject(currentPoolKey);
channels.put(serverAddress, channelFromPool);
} catch (Exception exx) {
LOGGER.error("{} register RM failed.", FrameworkErrorCode.RegisterRM.getErrCode(), exx);
throw new FrameworkException("can not register RM,err:" + exx.getMessage());
}
return channelFromPool;
}
Server Channel
On the Server side, almost all core logic related to Channel management is within ChannelManager. So how does the Server get its Channels? Remember that on the Client side, after initiating a connection to the Server, it also sends a registration request for TM and RM.
Let's first take a look at how the Server handles these registerRequests.
Handling Client Registration
The related handlers are RegRmProcessor and RegTmProcessor. In these two processors, the core logic involves calling the ChannelManager's registerTMChannel and registerRMChannel methods.
public static void registerTMChannel(RegisterTMRequest request, Channel channel) throws IncompatibleVersionException {
RpcContext rpcContext = buildChannelHolder(NettyPoolKey.TransactionRole.TM_ROLE, request.getVersion(),
request.getApplicationId(),
request.getTransactionServiceGroup(),
null, channel);
rpcContext.holdInIdentifiedChannels(IDENTIFIED_CHANNELS);
String clientIdentified = rpcContext.getApplicationId() + Constants.CLIENT_ID_SPLIT_CHAR + ChannelUtil.getClientIpFromChannel(channel);
ConcurrentMap<Integer, RpcContext> clientIdentifiedMap = CollectionUtils.computeIfAbsent(TM_CHANNELS, clientIdentified, key -> new ConcurrentHashMap<>());
rpcContext.holdInClientChannels(clientIdentifiedMap);
}
public static void registerRMChannel(RegisterRMRequest resourceManagerRequest, Channel channel) throws IncompatibleVersionException {
Set<String> dbkeySet = dbKeytoSet(resourceManagerRequest.getResourceIds());
RpcContext rpcContext;
if (!IDENTIFIED_CHANNELS.containsKey(channel)) {
rpcContext = buildChannelHolder(NettyPoolKey.TransactionRole.RM_ROLE, resourceManagerRequest.getVersion(),
resourceManagerRequest.getApplicationId(), resourceManagerRequest.getTransactionServiceGroup(),
resourceManagerRequest.getResourceIds(), channel);
rpcContext.holdInIdentifiedChannels(IDENTIFIED_CHANNELS);
} else {
rpcContext = IDENTIFIED_CHANNELS.get(channel);
rpcContext.addResources(dbkeySet);
}
if (dbkeySet == null || dbkeySet.isEmpty()) {
return;
}
for (String resourceId : dbkeySet) {
String clientIp;
ConcurrentMap<Integer, RpcContext> portMap = CollectionUtils.computeIfAbsent(RM_CHANNELS, resourceId, key -> new ConcurrentHashMap<>())
.computeIfAbsent(resourceManagerRequest.getApplicationId(), key -> new ConcurrentHashMap<>())
.computeIfAbsent(clientIp = ChannelUtil.getClientIpFromChannel(channel), key -> new ConcurrentHashMap<>());
rpcContext.holdInResourceManagerChannels(resourceId, portMap);
updateChannelsResource(resourceId, clientIp, resourceManagerRequest.getApplicationId());
}
}
These two methods have relatively simple logic. They construct an RpcContext based on the registration request and Channel information, maintaining relevant Map collections within the Server such as IDENTIFIED_CHANNELS, RM_CHANNELS, and TM_CHANNELS.
However, to be honest, these collections are nested quite deeply, and it is uncertain whether they can be optimized.
private static final ConcurrentMap<Channel, RpcContext> IDENTIFIED_CHANNELS = new ConcurrentHashMap<>();
private static final ConcurrentMap<String, ConcurrentMap<String, ConcurrentMap<String,
ConcurrentMap<Integer, RpcContext>>>> RM_CHANNELS = new ConcurrentHashMap<>();
private static final ConcurrentMap<String, ConcurrentMap<Integer, RpcContext>> TM_CHANNELS = new ConcurrentHashMap<>();
Acquiring Channel
On the Server side, the logic for acquiring a Channel is really long; those interested can take a look by themselves. Essentially, it involves obtaining an effective Channel from the map.
public static Channel getChannel(String resourceId, String clientId, boolean tryOtherApp) {
Channel resultChannel = null;
String[] clientIdInfo = parseClientId(clientId);
if (clientIdInfo == null || clientIdInfo.length != 3) {
throw new FrameworkException("Invalid Client ID: " + clientId);
}
if (StringUtils.isBlank(resourceId)) {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("No channel is available, resourceId is null or empty");
}
return null;
}
String targetApplicationId = clientIdInfo[0];
String targetIP = clientIdInfo[1];
int targetPort = Integer.parseInt(clientIdInfo[2]);
ConcurrentMap<String, ConcurrentMap<String, ConcurrentMap<Integer, RpcContext>>> applicationIdMap = RM_CHANNELS.get(resourceId);
if (targetApplicationId == null || applicationIdMap == null || applicationIdMap.isEmpty()) {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("No channel is available for resource[{}]", resourceId);
}
return null;
}
ConcurrentMap<String, ConcurrentMap<Integer, RpcContext>> ipMap = applicationIdMap.get(targetApplicationId);
if (ipMap != null && !ipMap.isEmpty()) {
ConcurrentMap<Integer, RpcContext> portMapOnTargetIP = ipMap.get(targetIP);
if (portMapOnTargetIP != null && !portMapOnTargetIP.isEmpty()) {
RpcContext exactRpcContext = portMapOnTargetIP.get(targetPort);
if (exactRpcContext != null) {
Channel channel = exactRpcContext.getChannel();
if (channel.isActive()) {
resultChannel = channel;
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("Just got exactly the one {} for {}", channel, clientId);
}
} else {
if (portMapOnTargetIP.remove(targetPort, exactRpcContext)) {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("Removed inactive {}", channel);
}
}
}
}
if (resultChannel == null) {
for (ConcurrentMap.Entry<Integer, RpcContext> portMapOnTargetIPEntry : portMapOnTargetIP.entrySet()) {
Channel channel = portMapOnTargetIPEntry.getValue().getChannel();
if (channel.isActive()) {
resultChannel = channel;
if (LOGGER.isInfoEnabled()) {
LOGGER.info(
"Choose {} on the same IP[{}] as alternative of {}", channel, targetIP, clientId);
}
break;
} else {
if (portMapOnTargetIP.remove(portMapOnTargetIPEntry.getKey(),
portMapOnTargetIPEntry.getValue())) {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("Removed inactive {}", channel);
}
}
}
}
}
}
if (resultChannel == null) {
for (ConcurrentMap.Entry<String, ConcurrentMap<Integer, RpcContext>> ipMapEntry : ipMap.entrySet()) {
if (ipMapEntry.getKey().equals(targetIP)) {
continue;
}
ConcurrentMap<Integer, RpcContext> portMapOnOtherIP = ipMapEntry.getValue();
if (portMapOnOtherIP == null || portMapOnOtherIP.isEmpty()) {
continue;
}
for (ConcurrentMap.Entry<Integer, RpcContext> portMapOnOtherIPEntry : portMapOnOtherIP.entrySet()) {
Channel channel = portMapOnOtherIPEntry.getValue().getChannel();
if (channel.isActive()) {
resultChannel = channel;
if (LOGGER.isInfoEnabled()) {
LOGGER.info("Choose {} on the same application[{}] as alternative of {}", channel, targetApplicationId, clientId);
}
break;
} else {
if (portMapOnOtherIP.remove(portMapOnOtherIPEntry.getKey(), portMapOnOtherIPEntry.getValue())) {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("Removed inactive {}", channel);
}
}
}
}
if (resultChannel != null) {
break;
}
}
}
}
if (resultChannel == null && tryOtherApp) {
resultChannel = tryOtherApp(applicationIdMap, targetApplicationId);
if (resultChannel == null) {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("No channel is available for resource[{}] as alternative of {}", resourceId, clientId);
}
} else {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("Choose {} on the same resource[{}] as alternative of {}", resultChannel, resourceId, clientId);
}
}
}
return resultChannel;
}
private static Channel tryOtherApp(ConcurrentMap<String, ConcurrentMap<String, ConcurrentMap<Integer, RpcContext>>> applicationIdMap, String myApplicationId) {
Channel chosenChannel = null;
for (ConcurrentMap.Entry<String, ConcurrentMap<String, ConcurrentMap<Integer, RpcContext>>> applicationIdMapEntry : applicationIdMap.entrySet()) {
if (!StringUtils.isNullOrEmpty(myApplicationId) && applicationIdMapEntry.getKey().equals(myApplicationId)) {
continue;
}
ConcurrentMap<String, ConcurrentMap<Integer, RpcContext>> targetIPMap = applicationIdMapEntry.getValue();
if (targetIPMap == null || targetIPMap.isEmpty()) {
continue;
}
for (ConcurrentMap.Entry<String, ConcurrentMap<Integer, RpcContext>> targetIPMapEntry : targetIPMap.entrySet()) {
ConcurrentMap<Integer, RpcContext> portMap = targetIPMapEntry.getValue();
if (portMap == null || portMap.isEmpty()) {
continue;
}
for (ConcurrentMap.Entry<Integer, RpcContext> portMapEntry : portMap.entrySet()) {
Channel channel = portMapEntry.getValue().getChannel();
if (channel.isActive()) {
chosenChannel = channel;
break;
} else {
if (portMap.remove(portMapEntry.getKey(), portMapEntry.getValue())) {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("Removed inactive {}", channel);
}
}
}
}
if (chosenChannel != null) {
break;
}
}
if (chosenChannel != null) {
break;
}
}
return chosenChannel;
}
Summary in a Sequence Diagram
Finally, let's summarize the Channel management process with a sequence diagram.
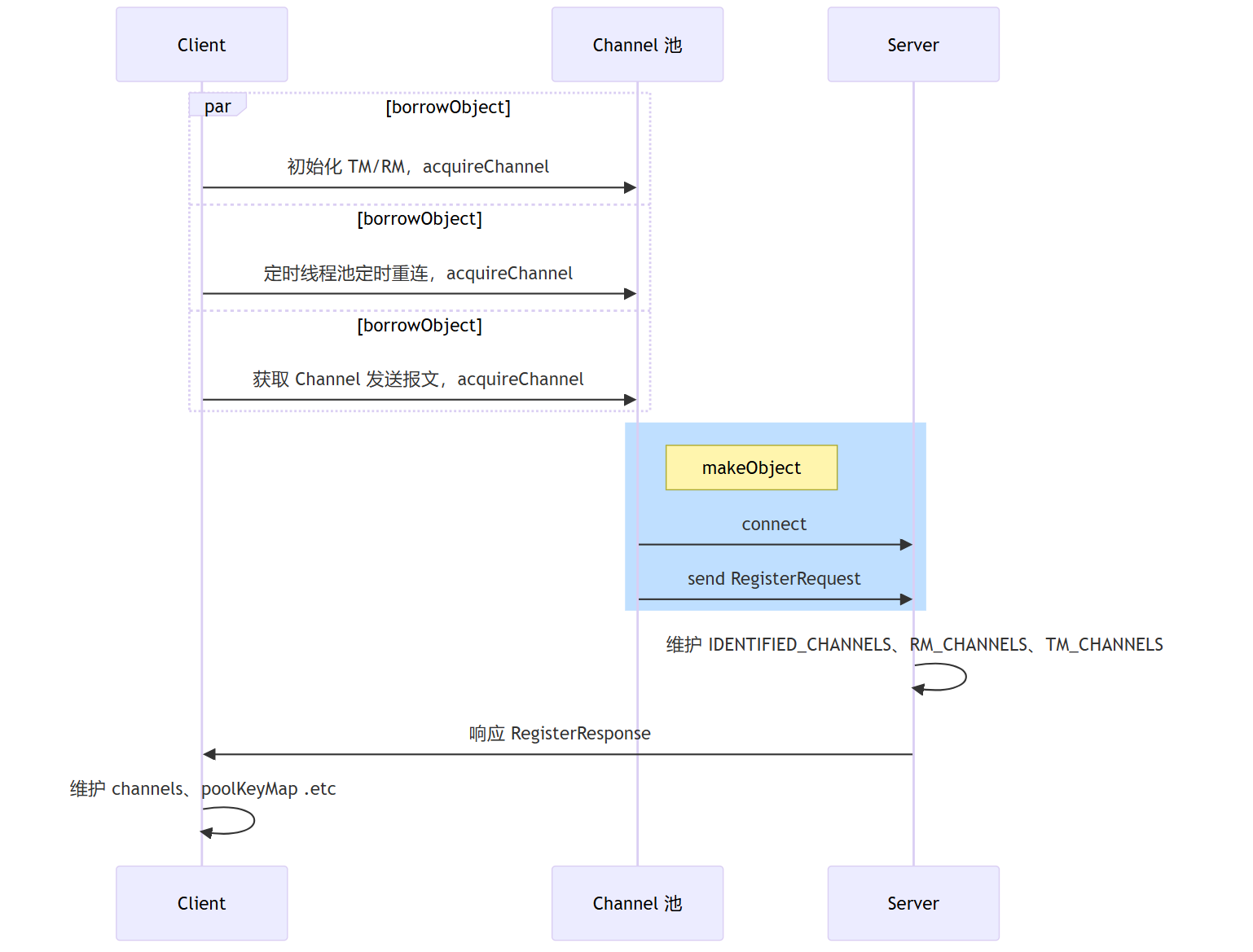
How Seata Designs Its Protocol
For any network program, communication protocols are indispensable, and Seata is no exception. Here we will look at how the V1 version of the Seata protocol is implemented.
The main related classes are ProtocolEncoderV1 and ProtocolDecoderV1.
Of course, as we know from before, the processor added when the Seata Server starts is actually MultiProtocolDecoder. In this class's decode method, it works as follows:
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
ByteBuf frame;
Object decoded;
byte version;
try {
if (isV0(in)) {
decoded = in;
version = ProtocolConstants.VERSION_0;
} else {
decoded = super.decode(ctx, in);
version = decideVersion(decoded);
}
if (decoded instanceof ByteBuf) {
frame = (ByteBuf) decoded;
ProtocolDecoder decoder = protocolDecoderMap.get(version);
ProtocolEncoder encoder = protocolEncoderMap.get(version);
try {
if (decoder == null || encoder == null) {
throw new UnsupportedOperationException("Unsupported version: " + version);
}
return decoder.decodeFrame(frame);
} finally {
if (version != ProtocolConstants.VERSION_0) {
frame.release();
}
ctx.pipeline().addLast((ChannelHandler) decoder);
ctx.pipeline().addLast((ChannelHandler) encoder);
if (channelHandlers != null) {
ctx.pipeline().addLast(channelHandlers);
}
ctx.pipeline().remove(this);
}
}
} catch (Exception exx) {
LOGGER.error("Decode frame error, cause: {}", exx.getMessage());
throw new DecodeException(exx);
}
return decoded;
}
Therefore, here the corresponding codec for the version is chosen, then added to the pipeline, which will remove the MultiProtocolDecoder.
V1 Version Protocol
Seata's protocol design is quite comprehensive and general, also being a mainstream solution to address issues like message fragmentation and partial messages, namely message length + message content.
The format of the protocol is as follows:
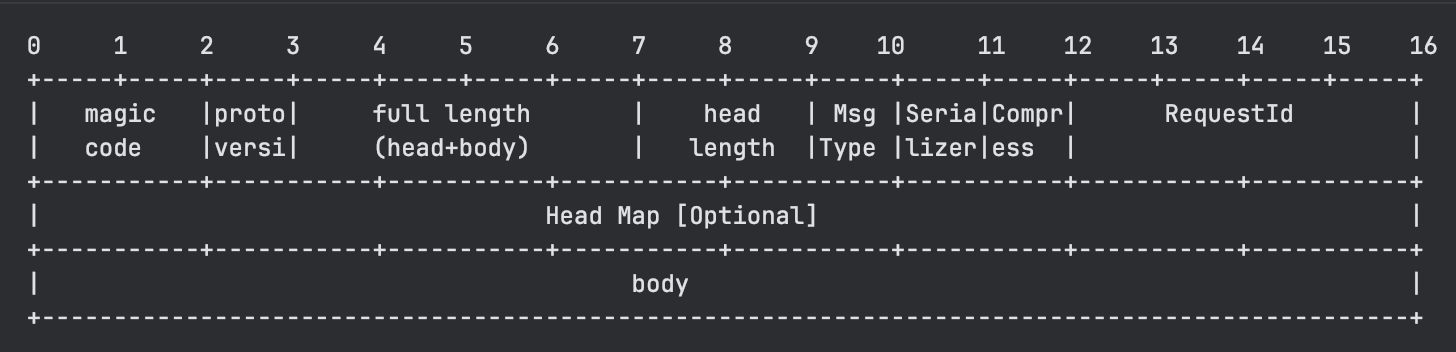
As can be seen, it includes magic numbers, protocol version numbers, length fields, header lengths, message types, serialization algorithms, compression algorithms, request IDs, optional map extensions, and the message body.
Seata decoders use Netty's built-in LengthFieldBasedFrameDecoder; those unfamiliar with it can take a look.
However, encoding and decoding are not difficult, so I'll simply provide the code without much explanation.
package org.apache.seata.core.rpc.netty.v1;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.MessageToByteEncoder;
import org.apache.seata.core.rpc.netty.ProtocolEncoder;
import org.apache.seata.core.serializer.Serializer;
import org.apache.seata.core.compressor.Compressor;
import org.apache.seata.core.compressor.CompressorFactory;
import org.apache.seata.core.protocol.ProtocolConstants;
import org.apache.seata.core.protocol.RpcMessage;
import org.apache.seata.core.serializer.SerializerServiceLoader;
import org.apache.seata.core.serializer.SerializerType;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Map;
public class ProtocolEncoderV1 extends MessageToByteEncoder implements ProtocolEncoder {
private static final Logger LOGGER = LoggerFactory.getLogger(ProtocolEncoderV1.class);
public void encode(RpcMessage message, ByteBuf out) {
try {
ProtocolRpcMessageV1 rpcMessage = new ProtocolRpcMessageV1();
rpcMessage.rpcMsgToProtocolMsg(message);
int fullLength = ProtocolConstants.V1_HEAD_LENGTH;
int headLength = ProtocolConstants.V1_HEAD_LENGTH;
byte messageType = rpcMessage.getMessageType();
out.writeBytes(ProtocolConstants.MAGIC_CODE_BYTES);
out.writeByte(ProtocolConstants.VERSION_1);
out.writerIndex(out.writerIndex() + 6);
out.writeByte(messageType);
out.writeByte(rpcMessage.getCodec());
out.writeByte(rpcMessage.getCompressor());
out.writeInt(rpcMessage.getId());
Map<String, String> headMap = rpcMessage.getHeadMap();
if (headMap != null && !headMap.isEmpty()) {
int headMapBytesLength = HeadMapSerializer.getInstance().encode(headMap, out);
headLength += headMapBytesLength;
fullLength += headMapBytesLength;
}
byte[] bodyBytes = null;
if (messageType != ProtocolConstants.MSGTYPE_HEARTBEAT_REQUEST && messageType != ProtocolConstants.MSGTYPE_HEARTBEAT_RESPONSE) {
Serializer serializer = SerializerServiceLoader.load(SerializerType.getByCode(rpcMessage.getCodec()), ProtocolConstants.VERSION_1);
bodyBytes = serializer.serialize(rpcMessage.getBody());
Compressor compressor = CompressorFactory.getCompressor(rpcMessage.getCompressor());
bodyBytes = compressor.compress(bodyBytes);
fullLength += bodyBytes.length;
}
if (bodyBytes != null) {
out.writeBytes(bodyBytes);
}
int writeIndex = out.writerIndex();
out.writerIndex(writeIndex - fullLength + 3);
out.writeInt(fullLength);
out.writeShort(headLength);
out.writerIndex(writeIndex);
} catch (Throwable e) {
LOGGER.error("Encode request error!", e);
throw e;
}
}
@Override
protected void encode(ChannelHandlerContext ctx, Object msg, ByteBuf out) throws Exception {
try {
if (msg instanceof RpcMessage) {
this.encode((RpcMessage) msg, out);
} else {
throw new UnsupportedOperationException("Not support this class:" + msg.getClass());
}
} catch (Throwable e) {
LOGGER.error("Encode request error!", e);
}
}
}
package org.apache.seata.core.rpc.netty.v1;
import java.util.List;
import java.util.Map;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.LengthFieldBasedFrameDecoder;
import org.apache.seata.core.compressor.Compressor;
import org.apache.seata.core.compressor.CompressorFactory;
import org.apache.seata.core.exception.DecodeException;
import org.apache.seata.core.protocol.HeartbeatMessage;
import org.apache.seata.core.protocol.ProtocolConstants;
import org.apache.seata.core.protocol.RpcMessage;
import org.apache.seata.core.rpc.netty.ProtocolDecoder;
import org.apache.seata.core.serializer.Serializer;
import org.apache.seata.core.serializer.SerializerServiceLoader;
import org.apache.seata.core.serializer.SerializerType;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class ProtocolDecoderV1 extends LengthFieldBasedFrameDecoder implements ProtocolDecoder {
private static final Logger LOGGER = LoggerFactory.getLogger(ProtocolDecoderV1.class);
private final List<SerializerType> supportDeSerializerTypes;
public ProtocolDecoderV1() {
super(ProtocolConstants.MAX_FRAME_LENGTH, 3, 4, -7, 0);
supportDeSerializerTypes = SerializerServiceLoader.getSupportedSerializers();
if (supportDeSerializerTypes.isEmpty()) {
throw new IllegalArgumentException("No serializer found");
}
}
@Override
public RpcMessage decodeFrame(ByteBuf frame) {
byte b0 = frame.readByte();
byte b1 = frame.readByte();
if (ProtocolConstants.MAGIC_CODE_BYTES[0] != b0 || ProtocolConstants.MAGIC_CODE_BYTES[1] != b1) {
throw new IllegalArgumentException("Unknown magic code: " + b0 + ", " + b1);
}
byte version = frame.readByte();
int fullLength = frame.readInt();
short headLength = frame.readShort();
byte messageType = frame.readByte();
byte codecType = frame.readByte();
byte compressorType = frame.readByte();
int requestId = frame.readInt();
ProtocolRpcMessageV1 rpcMessage = new ProtocolRpcMessageV1();
rpcMessage.setCodec(codecType);
rpcMessage.setId(requestId);
rpcMessage.setCompressor(compressorType);
rpcMessage.setMessageType(messageType);
int headMapLength = headLength - ProtocolConstants.V1_HEAD_LENGTH;
if (headMapLength > 0) {
Map<String, String> map = HeadMapSerializer.getInstance().decode(frame, headMapLength);
rpcMessage.getHeadMap().putAll(map);
}
if (messageType == ProtocolConstants.MSGTYPE_HEARTBEAT_REQUEST) {
rpcMessage.setBody(HeartbeatMessage.PING);
} else if (messageType == ProtocolConstants.MSGTYPE_HEARTBEAT_RESPONSE) {
rpcMessage.setBody(HeartbeatMessage.PONG);
} else {
int bodyLength = fullLength - headLength;
if (bodyLength > 0) {
byte[] bs = new byte[bodyLength];
frame.readBytes(bs);
Compressor compressor = CompressorFactory.getCompressor(compressorType);
bs = compressor.decompress(bs);
SerializerType protocolType = SerializerType.getByCode(rpcMessage.getCodec());
if (this.supportDeSerializerTypes.contains(protocolType)) {
Serializer serializer = SerializerServiceLoader.load(protocolType, ProtocolConstants.VERSION_1);
rpcMessage.setBody(serializer.deserialize(bs));
} else {
throw new IllegalArgumentException("SerializerType not match");
}
}
}
return rpcMessage.protocolMsgToRpcMsg();
}
@Override
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
Object decoded;
try {
decoded = super.decode(ctx, in);
if (decoded instanceof ByteBuf) {
ByteBuf frame = (ByteBuf) decoded;
try {
return decodeFrame(frame);
} finally {
frame.release();
}
}
} catch (Exception exx) {
LOGGER.error("Decode frame error, cause: {}", exx.getMessage());
throw new DecodeException(exx);
}
return decoded;
}
}
Summary
From the current perspective, the implementation of network communication in Seata is relatively easy to understand. However, this article's analysis is only superficial and does not delve into deeper, more critical aspects such as code robustness, exception handling, graceful shutdown, etc. Further analysis will be provided if there are new insights in the future.
Original Article Link
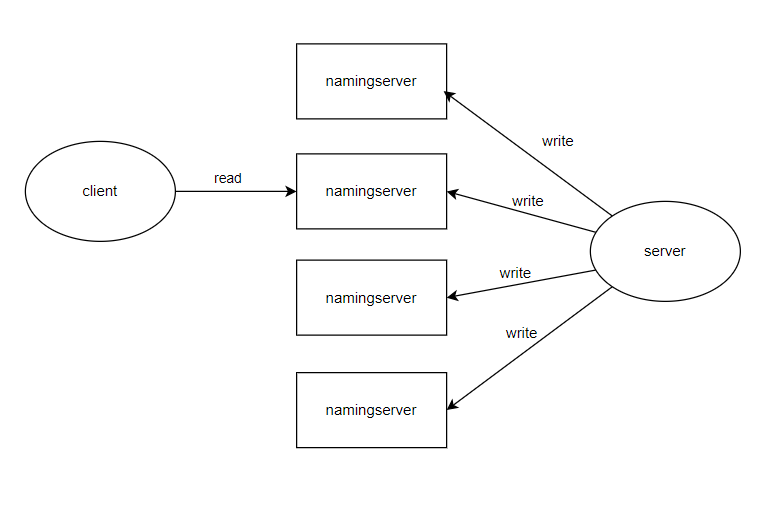
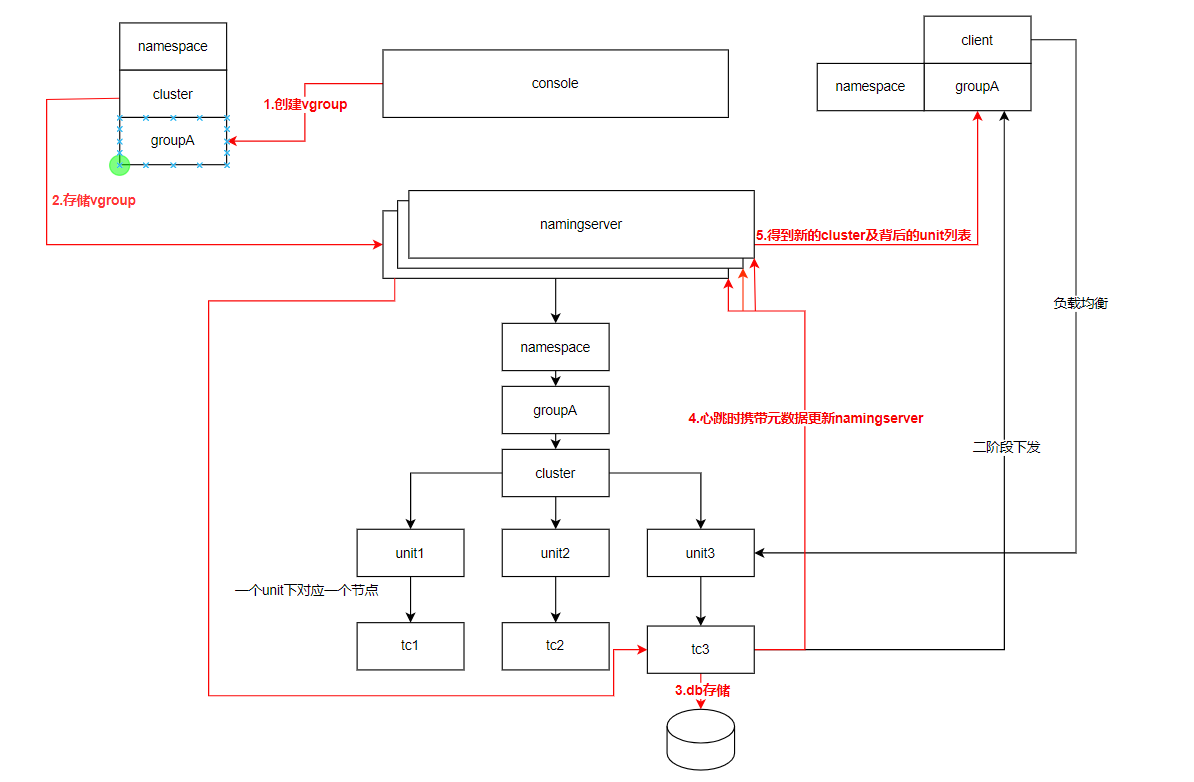
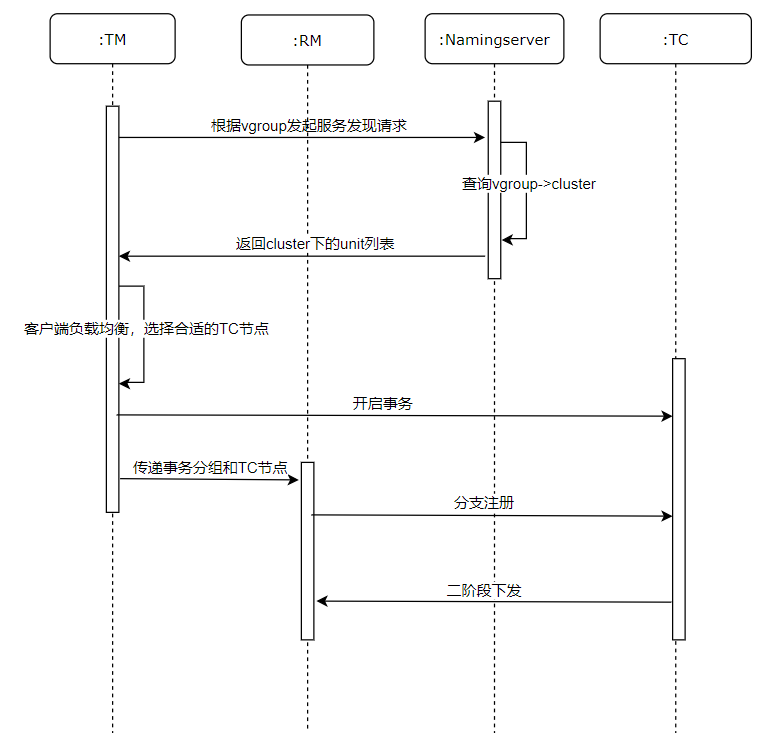 The interaction flow between transaction processing and namingserver is as follows:
The interaction flow between transaction processing and namingserver is as follows: