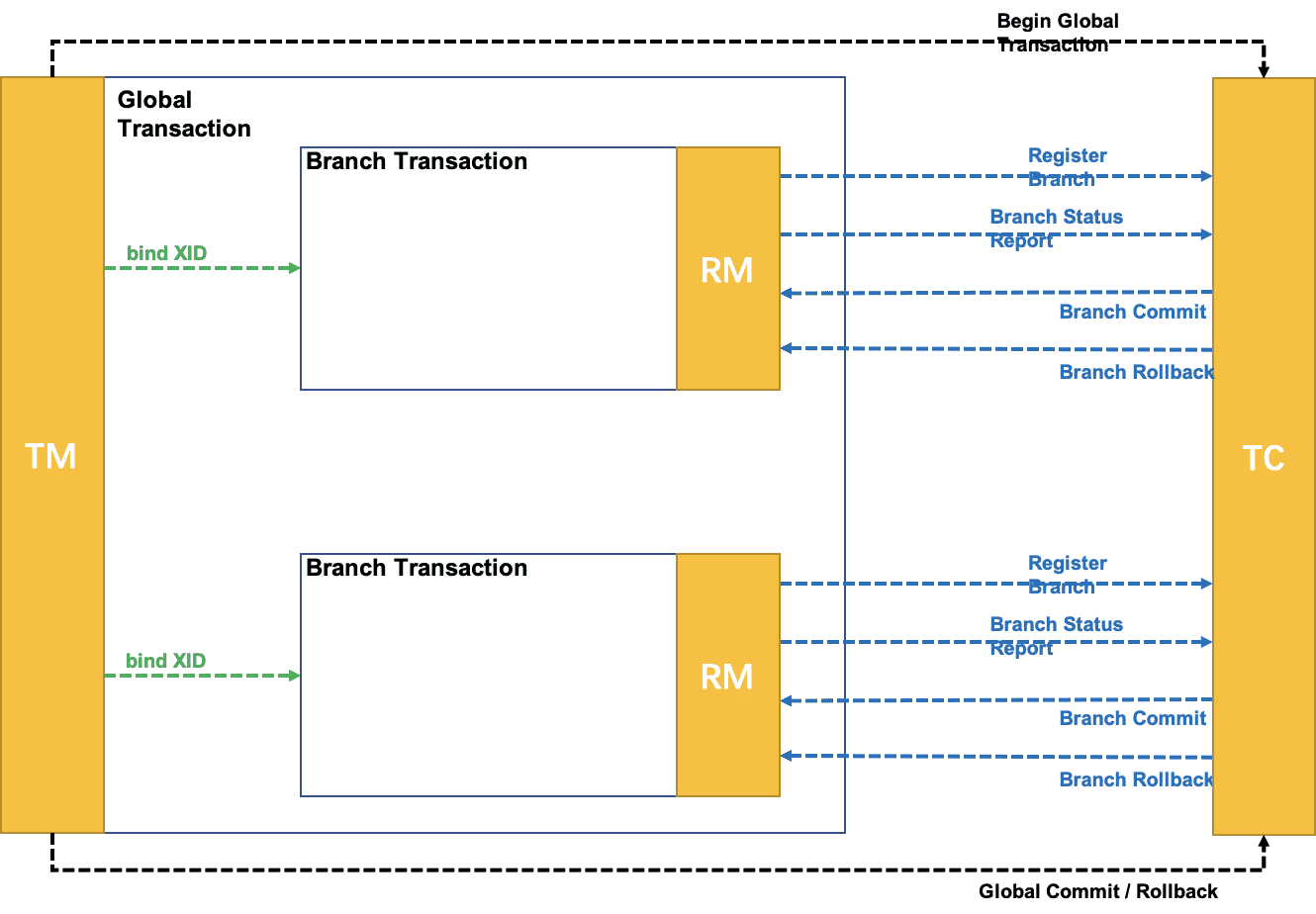
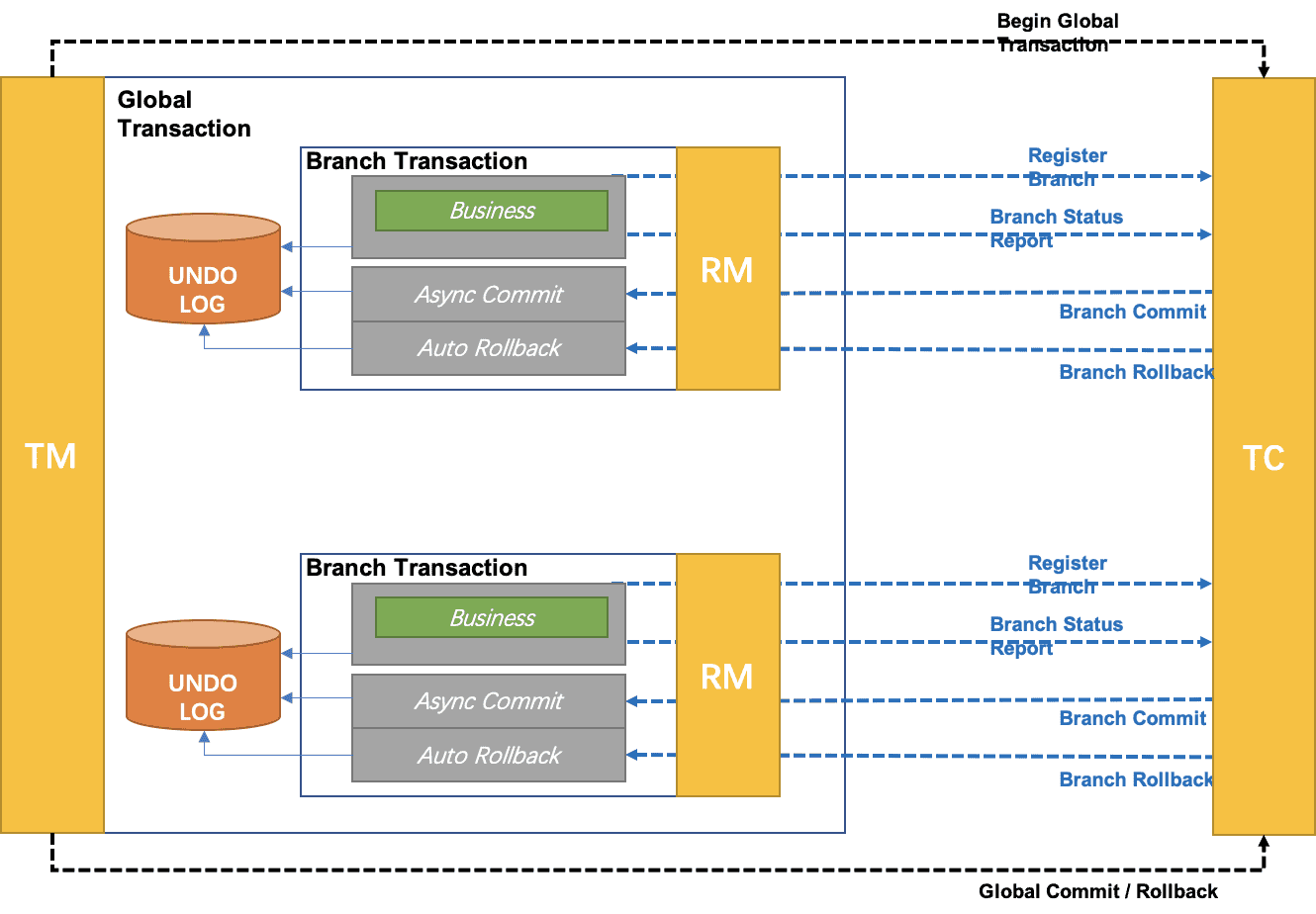
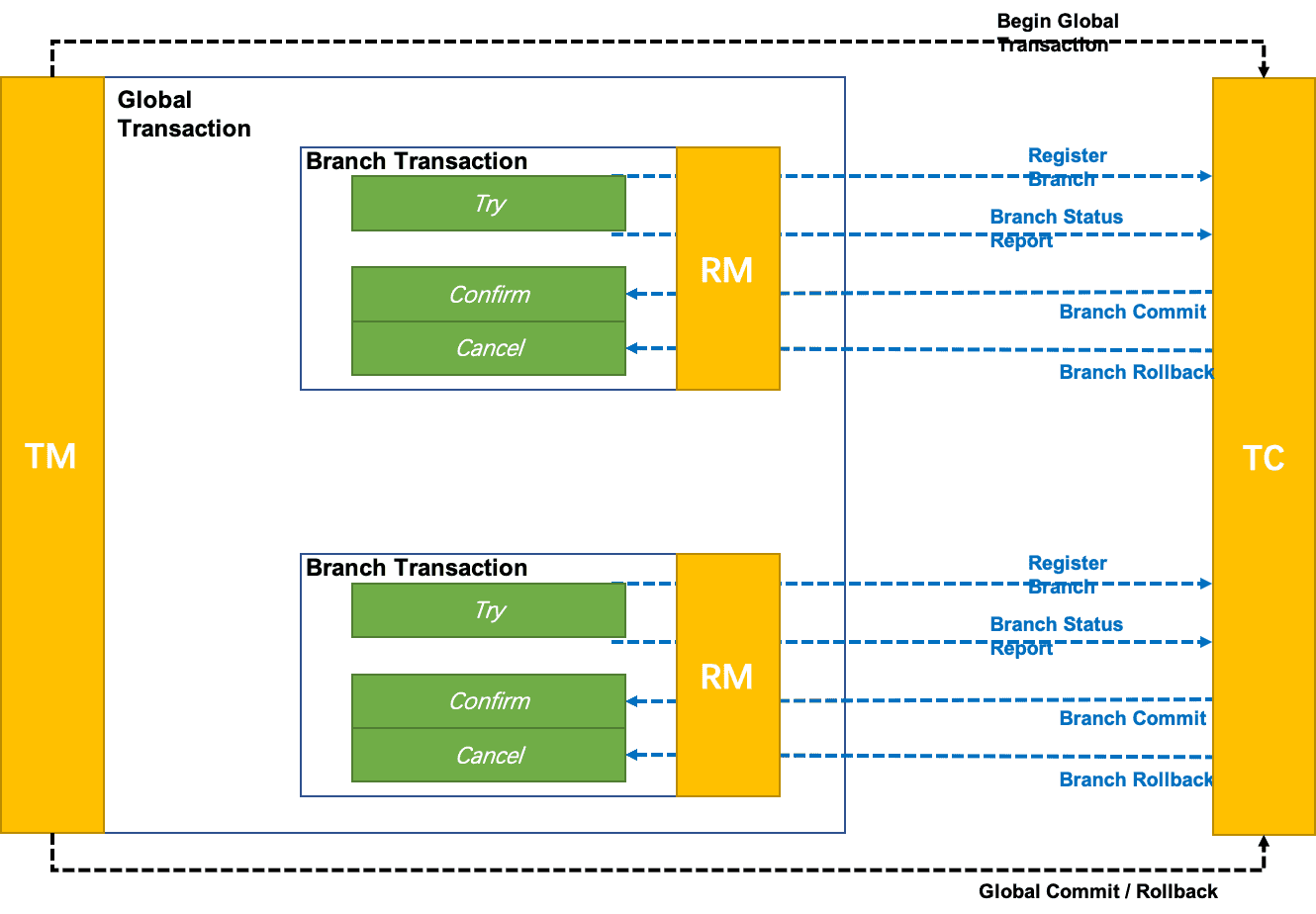
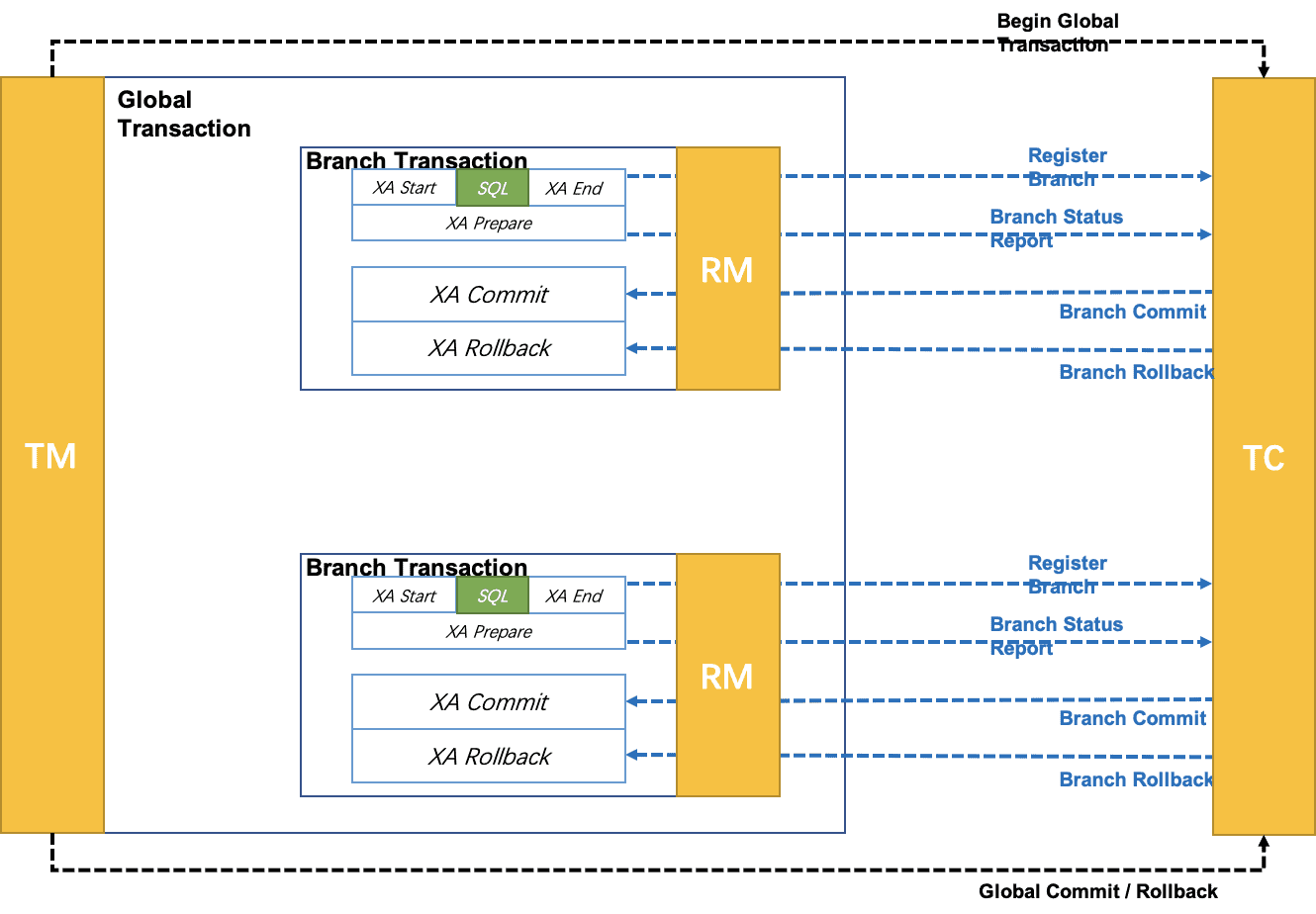
【Distributed Transaction Seata source code interpretation II】 Client-side startup process
In this paper, we analyse the Client-side startup process in AT mode from the source code point of view, the so-called Client-side, i.e. the business application side. Distributed transactions are divided into three modules: TC, TM, RM, where TC is located in the seata-server side, while TM, RM through the SDK way to run in the client side.
The following figure shows a distributed transaction scenario of Seata's official demo, divided into the following several microservices, which together implement a distributed transaction of placing an order, deducting inventory, and deducting balance.
- **BusinessService: ** business service, the entrance to the order placing service
- StorageService: Inventory microservice, used to deduct the inventory of goods
- OrderService: Order microservice, to create orders
- AccountService: Account microservice, debits the balance of the user's account
! [Insert image description here](https://img-blog.csdnimg.cn/20200820184156758.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10, text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NTE0NTg0OA==,size_16,colour_FFFFFF,t_70#pic_center)
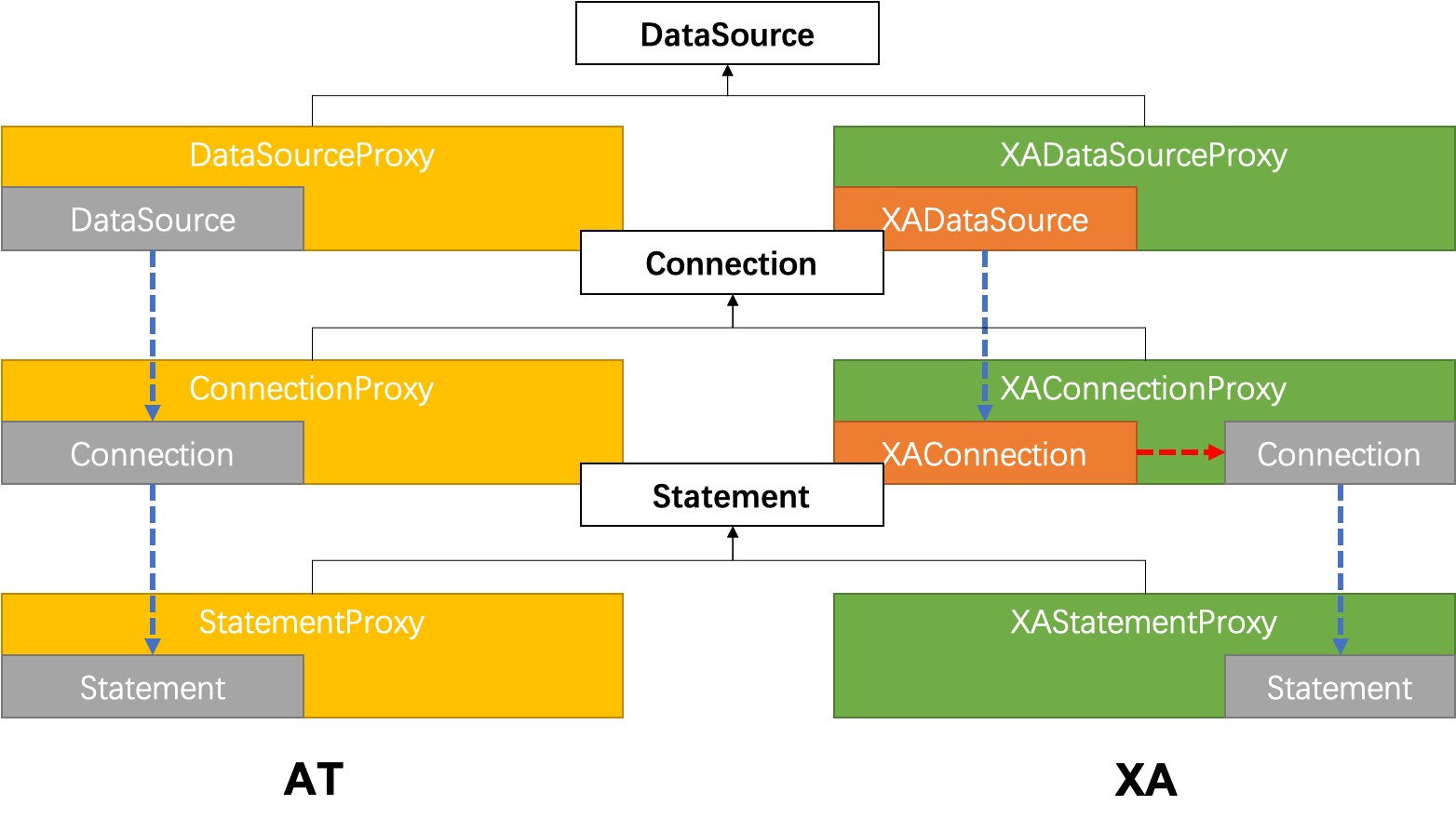
It can also be seen from the above figure that in AT mode Seata Client side implements distributed transactions mainly through the following three modules:
- GlobalTransactionScanner: GlobalTransactionScanner is responsible for initialising the TM, RM module and adding interceptors for methods that add distributed transaction annotations, the interceptors are responsible for the opening, committing or rolling back of the global transaction
- DatasourceProxy: DatasourceProxy for DataSource to add interception , the interceptor will intercept all SQL execution , and as RM transaction participant role in the distributed transaction execution .
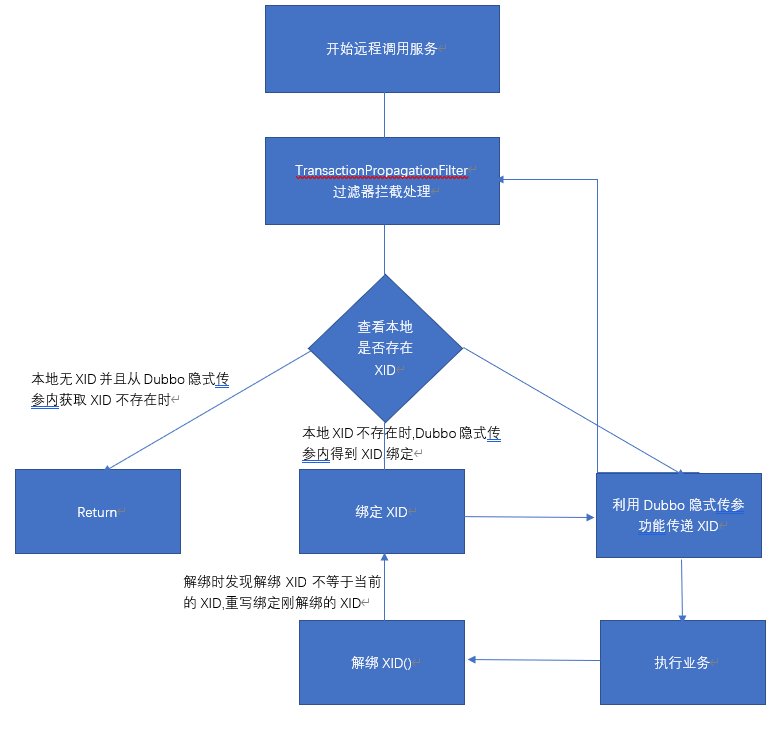
- Rpc Interceptor: In the previous article Distributed Transaction Seata Source Code Interpretation I there are a few core points of distributed transaction mentioned, one of which is Cross-Service Instance Propagation of Distributed Transactions The Rpc Interceptor is responsible for propagating transactions across multiple microservices.
seata-spring-boot-starter
There are two ways to refer to the seata Distributed Transaction SDK, relying on seata-all or seata-spring-boot-starter. It is recommended to use the seata-spring-boot-starter because the starter has automatically injected the three modules mentioned above, and the user only needs to add the corresponding configuration in the business code to add a global distributed transaction annotation can be. Here's how to start with the code in the seata-spring-boot-starter project:
The following figure shows the project structure of seata-spring-boot-starter: ! [Insert image description here](https://img-blog.csdnimg.cn/20200810204518853.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10, text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NTE0NTg0OA==,size_16,colour_FFFFFF,t_70) It is mainly divided into the following modules:
- properties: The properties directory contains the configuration classes that Springboot adapts to seata, i.e., you can use SpringBoot's configuration to configure the parameters of seata.
- provider: The classes in the provider directory are responsible for adapting Springboot and SpringCloud configurations to the Seata configuration.
- resources: There are two main files in the resources directory, spring.facts for registering Springboot auto-assembly classes and ExtConfigurationProvider for registering the SpringbootConfigurationProvider class, the Provider class is responsible for adapting SpringBoot related configuration classes to Seata.
For the springboot-starter project, let's first look at the resources/META-INF/spring.factors file:
# Auto Configure
org.springframework.boot.autoconfigure.EnableAutoConfiguration=
io.seata.spring.boot.autoconfigure.SeataAutoConfiguration
You can see that the autoconfiguration class is configured in spring.facts: SeataAutoConfiguration, in which two instances of GlobalTransactionScanner and seataAutoDataSourceProxyCreator are injected. The code is as follows:
@ComponentScan(basePackages = "io.seata.spring.boot.autoconfigure.properties")
@ConditionalOnProperty(prefix = StarterConstants.SEATA_PREFIX, name = "enabled",
havingValue = "true",
matchIfMissing = true)
@Configuration
@EnableConfigurationProperties({SeataProperties.class})
public class SeataAutoConfiguration {
...
// GlobalTransactionScanner is responsible for adding interceptors to methods that add the GlobalTransaction annotation.
// and is responsible for initialising the RM, TM
@Bean
@DependsOn({BEAN_NAME_SPRING_APPLICATION_CONTEXT_PROVIDER, BEAN_NAME_FAILURE_HANDLER})
@ConditionalOnMissingBean(GlobalTransactionScanner.class)
public GlobalTransactionScanner globalTransactionScanner(SeataProperties seataProperties,
FailureHandler failureHandler) {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("Automatically configure Seata");
}
return new GlobalTransactionScanner(seataProperties.getApplicationId(),
seataProperties.getApplicationId(), seataProperties.getTxServiceGroup(), failureHandler); }
failureHandler); }
}
// The SeataAutoDataSourceProxyCreator is responsible for generating proxies for all DataSources in Spring.
// This enables the interception of all SQL execution.
@Bean(BEAN_NAME_SEATA_AUTO_DATA_SOURCE_PROXY_CREATOR)
@ConditionalOnProperty(prefix = StarterConstants.SEATA_PREFIX, name = {
"enableAutoDataSourceProxy", "enable-auto" +
"-data-source-proxy"}, havingValue = "true", matchIfMissing = true)
@ConditionalOnMissingBean(SeataAutoDataSourceProxyCreator.class)
public SeataAutoDataSourceProxyCreator seataAutoDataSourceProxyCreator(SeataProperties seataProperties) {
return new SeataAutoDataSourceProxyCreator(seataProperties.isUseJdkProxy(), seataProperties.getExpressionCreator(seataProperties.getExpressionCreator))
seataProperties.getExcludesForAutoProxying());
}
}
GlobalTransactionScanner
GlobalTransactionScanner inherits from AutoProxyCreator, which is a way to implement AOP in Spring to intercept all instances in Spring and determine whether they need to be proxied. Below is a list of some of the more important fields in GlobalTransactionScanner and the core methods for intercepting proxies:
public class GlobalTransactionScanner extends AbstractAutoProxyCreator
implements InitialisingBean, ApplicationContextAware,
DisposableBean {
...
// The interceptor field is the interceptor corresponding to a proxy object.
// It can be thought of as a temporary variable with an expiration date of a proxied object.
private MethodInterceptor interceptor; // globalTransactionalInterceptor.
// globalTransactionalInterceptor is the generic Interceptor.
// It is used by all non-TCC transactional methods.
private MethodInterceptor globalTransactionalInterceptor; // PROXYED_SETTING_OBJECT
// PROXYED_SET stores instances that have already been proxied to prevent duplicate processing.
private static final Set<String> PROXYED_SET = new HashSet<>(); // applicationId is the name of a service.
// applicationId is a unique identifier for a service.
// corresponds to spring.application.name in the springcloud project
private final String applicationId; // The group identifier of the transaction.
// Grouping identifier for the transaction, refer to the wiki article: https://seata.apache.org/zh-cn/docs/user/txgroup/transaction-group/
private final String txServiceGroup; // The group identifier of the transaction.
...
// Determine whether the target object needs to be proxied, and if so, generate an interceptor and assign it to the class variable interceptor.
@Override
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
// Determine if distributed transactions are disabled
if (disableGlobalTransaction) {
return bean; }
}
try {
synchronized (PROXYED_SET) {
if (PROXYED_SET.contains(beanName)) {
return bean; }
}
// Each time a proxied object is processed, the intermediary is set to null, so the intermediary's // lifecycle is that of a proxied object.
// lifecycle is a proxied object, and since the intermediary is used in a separate method, getAdvicesAndAdvisorsForBean
// Since the interceptor is used in a separate method getAdvicesAndAdvisorsForBean, the interceptor is defined as a class variable
interceptor = null; // Determine if this is a TCC transaction.
// Determine whether this is TCC transaction mode, primarily based on the presence of the TwoPhaseBusinessAction annotation on the method
if (TCCBeanParserUtils.isTccAutoProxy(bean, beanName, applicationContext)) { if (TCCBeanParserUtils.isTccAutoProxy(bean, beanName,
applicationContext)) {
// Create an interceptor for the TCC transaction
interceptor =
new TccActionInterceptor(TCCBeanParserUtils.getRemotingDesc(beanName));
} else {
// Get the class type of the object to be processed
Class<? > serviceInterface = SpringProxyUtils.findTargetClass(bean); } else { // Get the class type of the object to be processed.
// Get all interfaces inherited by the object to be processed
Class<? >[] interfacesIfJdk = SpringProxyUtils.findInterfaces(bean); // Get all interfaces inherited by the pending object.
// If there is a GlobalTransactional annotation on the class of the pending object or on the inherited interfaces.
// or any of the methods of the class of the object to be handled have a GlobalTransactional or
// GlobalLock annotation on any of the methods of the class of the object to be handled returns true, i.e., it needs to be proxied.
if (!existsAnnotation(new Class[]{serviceInterface})
&& !existsAnnotation(interfacesIfJdk)) {
return bean;
}
// If the interceptor is null, i.e. not in TCC mode.
// then use globalTransactionalInterceptor as the interceptor
if (interceptor == null) {
// globalTransactionalInterceptor will only be created once
if (globalTransactionalInterceptor == null) {
globalTransactionalInterceptor =
new GlobalTransactionalInterceptor(failureHandlerHook);
ConfigurationCache.addConfigListener(
ConfigurationKeys.DISABLE_GLOBAL_TRANSACTION, (ConfigurationChangeListener.addConfigListener(
(ConfigurationChangeListener) globalTransactionalInterceptor);
}
interceptor = globalTransactionalInterceptor;
}
}
if (!AopUtils.isAopProxy(bean)) {
// If the bean itself is not a Proxy object, then the parent class wrapIfNecessary is called to generate the proxy object
// In the parent class, getAdvicesAndAdvisorsForBean is called to get the interceptor defined above.
bean = super.wrapIfNecessary(bean, beanName, cacheKey); } else { getAdvicesAndAdvisorsForBean(bean, beanName, cacheKey); }
} else {
// If the bean is already a proxy, add a new interceptor directly to the proxy's interceptor call chain, AdvisedSupport
// and add the new interceptor directly to the proxy's interception invocation chain.
AdvisedSupport advised = SpringProxyUtils.getAdvisedSupport(bean);
Advisor[] advisor = buildAdvisors(beanName,
getAdvicesAndAdvisorsForBean(null, null, null));
for (Advisor avr : advisor) {
advised.addAdvisor(0, avr);
}
}
// Mark that the beanName has been processed
PROXYED_SET.add(beanName);
return bean; }
}
} catch (Exception exx) {
throw new RuntimeException(exx); }
}
}
// Return the interceptor object computed in the wrapIfNecessary method.
@Override
protected Object[] getAdvicesAndAdvisorsForBean(Class beanClass, String beanName,
TargetSource customTargetSource)
throws BeansException {
return new Object[]{interceptor};
}
}
The above describes how GlobalTransactionScanner intercepts global transactions via annotations, the specific interceptor implementations are TccActionInterceptor and GlobalTransactionalInterceptor, for the AT pattern we are mainly concerned with the GlobalTransactionalInterceptor, in subsequent articles will introduce the specific implementation of GlobalTransactionalInterceptor.
In addition GloabalTransactionScanner is also responsible for the initialisation of TM, RM, which is implemented in the initClient method:
private void initClient() {
...
// Initialise the TM
TMClient.init(applicationId, txServiceGroup); ...
...
//Initialise RM
RMClient.init(applicationId, txServiceGroup); ...
...
// Register the Spring shutdown callback to free up resources.
registerSpringShutdownHook(); ... // Register the Spring shutdown callback for releasing resources.
}
TMClient, RMClient are Seata based on Netty implementation of the Rpc framework of the client class, just business logic is different, due to TMClient is relatively more simple, we take RMClient as an example to see the source code:
public class RMClient {
// RMClient's init is a static method that creates an instance of RmNettyRemotingClient and calls the init method.
public static void init(String applicationId, String transactionServiceGroup) {
RmNettyRemotingClient rmNettyRemotingClient =
RmNettyRemotingClient.getInstance(applicationId, transactionServiceGroup);
rmNettyRemotingClient.setResourceManager(DefaultResourceManager.get());
rmNettyRemotingClient.setTransactionMessageHandler(DefaultRMHandler.get()); rmNettyRemotingClient.setTransactionMessageHandler(DefaultRMHandler.get());
rmNettyRemotingClient.init();
}
}
RmNettyRemotingClient is implemented as follows:
@Sharable
public final class RmNettyRemotingClient extends AbstractNettyRemotingClient {
// ResourceManager is responsible for handling transaction participants, supports AT, TCC and Saga modes.
// RmNettyRemotingClient singleton.
private static volatile RmNettyRemotingClient instance; // RmNettyRemotingClient instance; // RmNettyRemotingClient instance.
private final AtomicBoolean initialised = new AtomicBoolean(false); // The unique identifier of the microservice.
// Unique identifier of the microservice
private String applicationId; // Distributed transaction group name.
// Distributed transaction group name
private String transactionServiceGroup; // The name of the distributed transaction group.
// The init method is called by the init method in RMClient.
public void init() {
// Register the Processor for Seata's custom Rpc.
registerProcessor(); // If (initialised.compareAndAndroid)
if (initialised.compareAndSet(false, true)) {
// Call the init method of the parent class, which is responsible for initialising Netty and establishing a connection to the Seata-Server in the parent class
super.init();
}
}
// Register the Processor for the Seata custom Rpc.
private void registerProcessor() {
// 1. Register the Processor for the Seata-Server initiating the branchCommit.
RmBranchCommitProcessor rmBranchCommitProcessor =
new RmBranchCommitProcessor(getTransactionMessageHandler(), this);
super.registerProcessor(MessageType.TYPE_BRANCH_COMMIT, rmBranchCommitProcessor,
messageExecutor); messageExecutor
// 2. Register the Processor for the Seata-Server initiating the branchRollback.
RmBranchRollbackProcessor rmBranchRollbackProcessor =
new RmBranchRollbackProcessor(getTransactionMessageHandler(), this);
super.registerProcessor(MessageType.TYPE_BRANCH_ROLLBACK, rmBranchRollbackProcessor
, messageExecutor);
// 3. Register the Processor for the Seata-Server initiating the deletion of the undoLog.
RmUndoLogProcessor rmUndoLogProcessor =
new RmUndoLogProcessor(getTransactionMessageHandler());
super.registerProcessor(MessageType.TYPE_RM_DELETE_UNDOLOG, rmUndoLogProcessor,
rmUndoLogProcessor, rmUndoLogProcessor); messageExecutor);
// 4. Register the Processor for the response returned by Seata-Server, ClientOnResponseProcessor.
// Used to process the Request initiated by the Client and the Response returned by the Seata-Server.
The ClientOnResponseProcessor // is responsible for processing the Request sent by the Client and the Response returned by the Seata-Server.
// Response returned by the Seata-Server, thus implementing Rpc.
ClientOnResponseProcessor onResponseProcessor =
new ClientOnResponseProcessor(mergeMsgMap, super.getFutures(),
getTransactionMessageHandler());
super.registerProcessor(MessageType.TYPE_SEATA_MERGE_RESULT, onResponseProcessor,
null); super.registerProcessor(MessageType.TYPE_SEATA_MERGE_RESULT, onResponseProcessor, null)
super.registerProcessor(MessageType.TYPE_BRANCH_REGISTER_RESULT, onResponseProcessor, null); super.registerProcessor(MessageType.
onResponseProcessor, null); super.registerProcessor(MessageType.
super.registerProcessor(MessageType.TYPE_BRANCH_STATUS_REPORT_RESULT, onResponseProcessor, null); super.registerProcessor(MessageType.
onResponseProcessor, null);
super.registerProcessor(MessageType.TYPE_GLOBAL_LOCK_QUERY_RESULT,
onResponseProcessor, null); super.registerProcessor(MessageType.
super.registerProcessor(MessageType.TYPE_REG_RM_RESULT, onResponseProcessor, null);
// 5. Processing Pong messages returned by Seata-Server
ClientHeartbeatProcessor clientHeartbeatProcessor = new ClientHeartbeatProcessor();
super.registerProcessor(MessageType.TYPE_HEARTBEAT_MSG, clientHeartbeatProcessor,
null);
}
}
The above logic seems to be quite complex, and there are many related classes, such as Processor, MessageType, TransactionMessageHandler, ResourceManager, etc. In fact, it's essentially an Rpc call, which can be divided into Rm-initiated and Seata-initiated calls.
- Rm active call methods: such as: registering branches, reporting branch status, applying global locks, etc. Rm active call methods need to be in the ClientOnResponseProcessor to handle the Response returned by Seata-Server.
- Seata-Server active call methods: such as: commit branch transactions, rollback branch transactions, delete undolog log. Seata-Server active call methods, the Client side corresponds to a different Processor to deal with, and after the end of processing to return to the Seata-Server processing results. Response. The core implementation logic of transaction commit and rollback are in TransactionMessageHandler and ResourceManager.
About TransactionMessageHandler, ResourceManager implementation will also be described in detail in subsequent chapters.
The next article will introduce the SeataAutoDataSourceProxyCreator, Rpc Interceptor is how to initialise and intercept.