seata目前支持多种注册中心的实现,为了提供整个链路的闭环功能,seata设计推出了原生的注册中心namingserver
2. 领域模型
2.1 命名空间与事务分组
- Namespace:在NamingServer模型中,命名空间(Namespace)用于实现命名空间的环境隔离。它允许在不同的环境(如开发、测试、生产)中隔离各自的服务实例。
- Cluster与Unit:Cluster(集群)负责事务分组的处理,Unit则在每个集群内部做负载均衡。事务分组(vgroup)在命名空间和集群的配合下,通过元数据定位到具体的TC节点。
2.2 事务处理流程与namingserver的交互
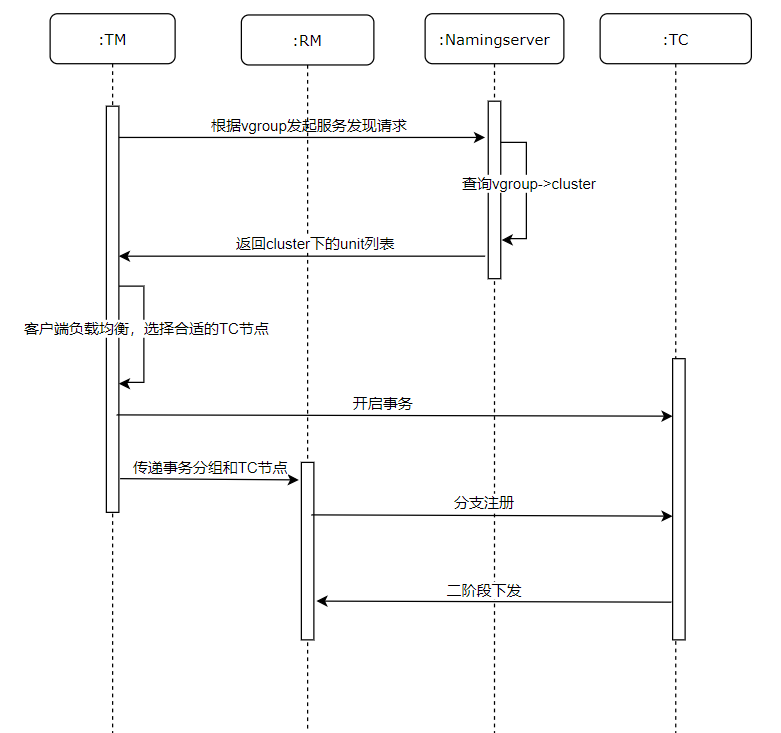 事务处理流程与namingserver的交互的流程如下:
事务处理流程与namingserver的交互的流程如下:
1.在client侧配置好Namingserver的地址和相关配置
2.client启动后TM向namingserver发起服务发现的请求
3.namingserver根据TM传来的vGroup参数和内存中的事务分组映射关系返回相关的集群列表,namingserver返回的集群列表元数据如下
{
"clusterList": [
{
"clusterName": "cluster2",
"clusterType": "default",
"groupList":[group1,group2]
"unitData": [
{
"unitName": "115482ee-cf27-45d6-b17e-31b9e2d7892f",
"namingInstanceList": [
{
"ip": "172.31.31.191",
"port": 8092,
"nettyPort": 0,
"grpcPort": 0,
"weight": 1.0,
"healthy": true,
"timeStamp": 1695042063334,
"role": member,
"metadata": {
"weight": 1,
"cluster-type": "default"
}
}
]
},
{
"unitName": "097e6ab7-d2d2-47e4-a578-fae1a4f4c517",
"namingInstanceList": [
{
"ip": "172.31.31.191",
"port": 8091,
"nettyPort": 0,
"grpcPort": 0,
"weight": 1.0,
"healthy": true,
"timeStamp": 1695042076481,
"role": member,
"metadata": {
"weight": 1,
"cluster-type": "default"
}
}
]
}
]
}
],
"term": 1695042076578
}
4.客户端通过负载均衡策略找出合适的TC节点开启事务
5.TM将事务分组和TC节点传递给RM
6.RM向TC节点发起分支注册的请求
7.TC节点完成二阶段下发
3.设计思路
3.1 AP还是CP?
CAP协议又称CAP定理,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。 分布式系统的CAP理论:理论首先把分布式系统中的三个特性进行了如下归纳:
● 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
● 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
● 分区容错性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
对于namingserver而言,我们更倾向于使用AP模型,即注重可用性和分区容错性,牺牲一定的一致性。NamingServer作为服务注册中心,主要职责是提供高效的服务发现与注册服务,而对短时间内的数据一致性要求可以适当放松。在分布式环境中,可能会出现多个节点短暂的注册数据不一致现象。例如,当多个NamingServer节点发生了网络分区时,某些节点获取的注册信息可能有延迟。 对于NamingServer来说,这种短暂的不一致性我们认为是可以容忍的。由于服务注册与发现的强一致性要求并不高,即使在某个时刻有部分节点的注册数据滞后或不一致,也不会立刻影响到整个系统的正常服务。通过心跳机制、周期性同步等方式,最终一致性可以逐渐得到保证。
3.2 Quorum NWR机制在NamingServer中的应用
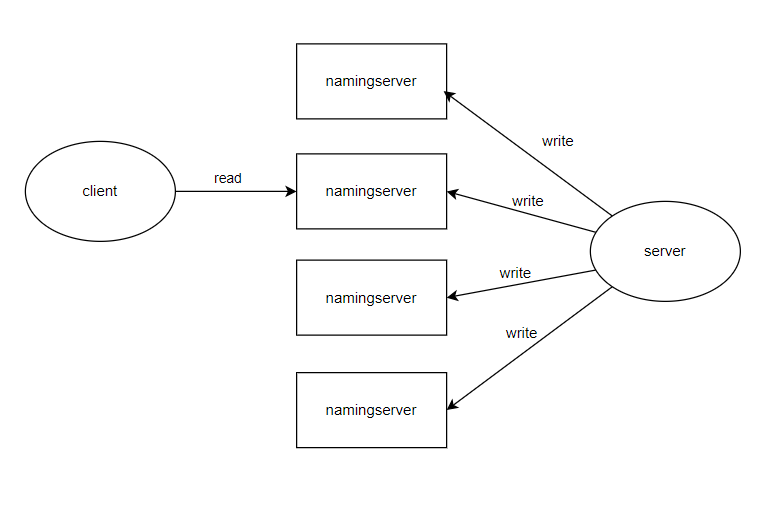
Quorum NWR(仲裁读写)是一种在分布式系统中用于确保数据一致性的机制。该机制通过设置副本的总数(N)、写操作需要成功的副本数(W)、读操作需要访问的副本数(R)来协调数据的一致性。在NamingServer的设计中,采用了多写+补偿机制来保证多个NamingServer节点之间的信息一致性,而客户端则与某一个NamingServer节点交互以获取注册信息。
- 写入操作(W-写仲裁): 当有集群节点变化时,server端会将请求发送到NamingServer集群中的多个节点。 根据NWR机制,系统确保至少有W个副本成功写入注册信息。 通过多写机制,即使某些节点暂时不可用或存在网络延迟,仍能确保写操作的高可用性。一旦W个节点写入成功,客户端将收到成功响应。 补偿机制:对于没有立即成功写入的副本,系统会通过异步补偿方式,在稍后的时间段内同步这些节点,确保最终一致性。
- 读取操作(R-读仲裁): 客户端通过与NamingServer集群中的任意一个节点进行交互,发送读取请求以获取服务注册信息。 系统会从至少R个副本中读取数据,采用最新版本的数据作为返回结果。即使某些节点的数据存在短暂不一致,客户端通过读取多个副本并比较其版本号或一致性标记,能够确保读取到最新的注册信息。 由于客户端只与一个NamingServer节点进行交互,读取操作的效率得到了提升,并且避免了多个节点之间的复杂协调,系统依然能保证最终一致性。
- NWR参数的设计与权衡:
在namingserver中我们设置W=N、R=1。W=N虽然意味着写入需要发送到所有节点,但并不要求所有节点必须立即成功写入。系统允许某些节点暂时失败,通过补偿机制在后续阶段同步这些节点,从而提高系统的容错性,因为即便某些节点在写入时发生故障或网络中断,数据更新仍然可以通过补偿机制最终传播到所有节点。这既保证了系统的高可用性,也确保了数据最终在所有节点上是一致的。由于写操作要求所有节点参与,因此每个节点都会接收到最新的数据更新。
客户端在执行读取操作时,可以从任意一个NamingServer节点读取数据,而不必担心数据不一致的问题。即使某些节点未能在写�入时立即成功,客户端仍能从其他已成功写入的节点获取最新的注册信息。这样,R值可以设定较低(如R=1),从而提高读取操作的效率,同时系统通过补偿机制确保所有节点最终达到一致。
3.2 架构图
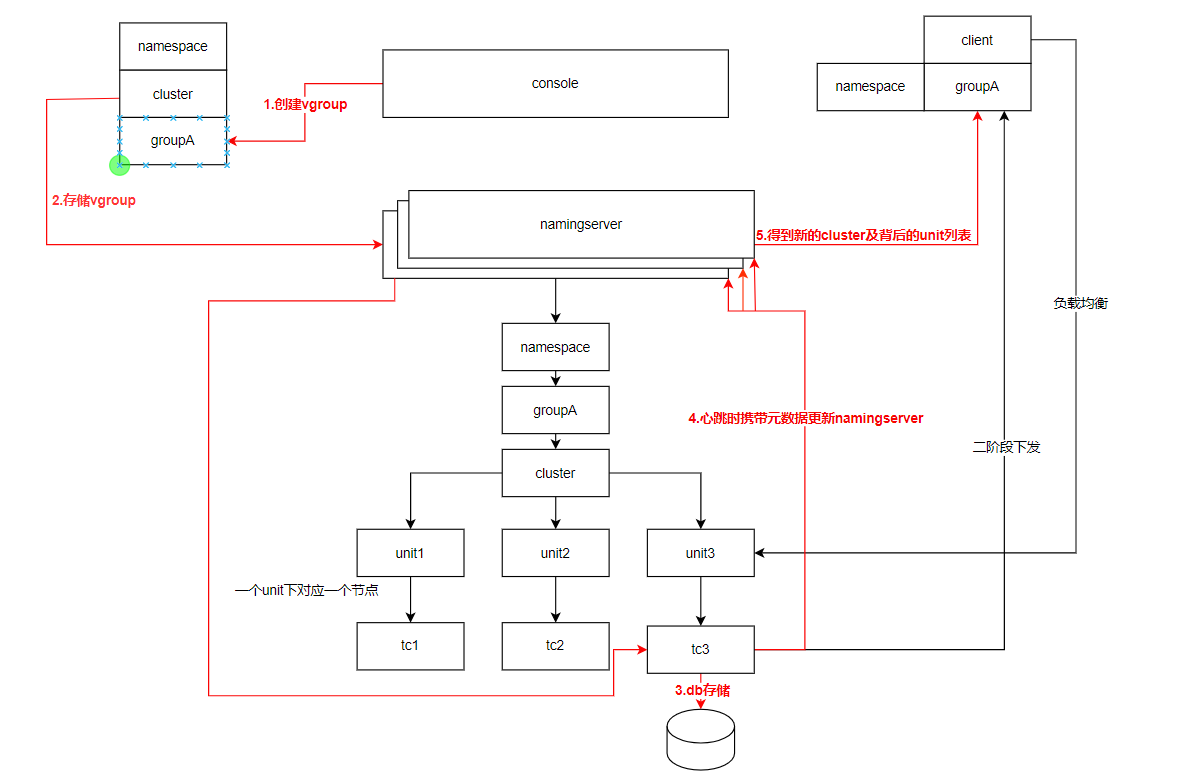
namingserver的运行链路如上图所示:
- 通过控制台在某个cluster下创建一个事务分组vgroup。
- 创建vgroup->cluster的请求发送给namingserver,namingserver再传递给对应的tc节点。
- tc节点将vgroup->cluster映射关系持久化保存。
- tc节点在心跳的时候将vgroup->cluster的映射关系更新到所有的namingserver。
- client通过自己配置的事务分组vgroup从namingserver获取对应cluster元数据。
- client在事务流程中,使用cluster下的unit进行负载均衡,再进行begin,registry,commit,rollback等。
- 事务决议后,对应的unit下的leader节点下发二阶段,无状态节点下,每个unit的唯一node就是leader。
3.3 设计细节
3.3.1 长轮询推送集群变化情况
如上图所示,每隔30s client侧需要向namingserver发起一次服务发现的请求,用以拉取最新的tc列表。而在这30s的间隔中,client侧将采用HTTP长轮询的方式一直watch namingserver节点,如果namingserver 侧有如下的变化:
1.事务分组映射关系的变化;
2.集群中实例的增加或者减少;
3.集群中实例的属性的变化;
那么watch返回200状态码,告知client需要获取最新集群信息;否则namingserver将一直挂起watch方法,直到HTTP长轮询超时,然后返回304状态码, 告知client进行下一轮watch。