Seata 意为:Simple Extensible Autonomous Transaction Architecture,是一套一站式分布式事务解决方案,提供了 AT、TCC、Saga 和 XA 事务模式,本文详解其中的 Saga 模式。
项目地址:https://github.com/apache/incubator-seata
本文作者:屹远(陈龙),蚂蚁金服分布式事务核心研发。
金融分布式应用开发的痛点
分布式系统有一个比较明显的问题就是,一个业务流程需要组合一组服务。这样的事情在微服务下就更为明显了,因为这需要业务上的一致性的保证。也就是说,如果一个步骤失败了,那么要么回滚到以前的服务调用,要么不断重试保证所有的步骤都成功。---《左耳听风-弹力设计之“补偿事务”》
而在金融领域微服务架构下的业务流程往往会更复杂,流程很长,比如一个互联网微贷业务流程调十几个服务很正常,再加上异常处理的流程那就更复杂了,做过金融业务开发的同学会很有体感。
所以在金融分布式应用开发过程中我们面临一些痛点:
- 业务一致性难以保障
我们接触到的大多数业务(比如在渠道层、产品层、集成层的系统),为了保障业务最终一致性,往往会采用“补偿”的方式来做,如果没有一个协调器来支持,开发难度是比较大的,每一步都要在 catch 里去处理前面所有的“回滚”操作,这将会形成“箭头形”的代码,可读性及维护性差。或者重试异常的操作,如果重试不成功可能要转异步重试,甚至最后转人工处理。这些都给开发人员带来极大的负担,开发效率低,且容易出错。
- 业务状态难以管理
业务实体很多、实体的状态也很多,往往做完一个业务活动后就将实体的状态更新到了数据库里,没有一个状态机来管理整个状态的变迁过程,不直观,容易出错,造成业务进入一个不正确的状态。
- 幂等性难以保障
服务的幂等性是分布式环境下的基本要求,为了保证服务的幂等性往往需要服务开发者逐个去设计,有用数据库唯一键实现的,有用分布式缓存实现的,没有一个统一的方案,开发人员负担大,也容易遗漏,从而造成资损。
- 业务监控运维难,缺乏统一的差错守护能力
业务的执行情况监控一般通过打印日志,再基于日志监控平台查看,大多数情况是没有问题的,但是如果业务出错,这些监控缺乏当时的业务上下文,对排查问题不友好,往往需要再去数据库里查。同时日志的打印也依赖于开发,容易遗漏。对于补偿事务往往需要有“差错守护触发补偿”、“工人触发补偿”操作,没有统一的差错守护和处理规范,这些都要开发者逐个开发,负担沉重。
理论基础
一些场景下,我们对数据有强一致性的需求时,会采用在业务层上需要使用“两阶段提交”这样的分布式事务方案。而在另外一些场景下,我们并不需要这么强的一致性,那就只需要保证最终一致性就可以了。
例如蚂蚁金服目前在金融核心系统使用的就是 TCC 模式,金融核心系统的特点是一致性要求高(业务上的隔离性)、短流程、并发高。
而在很多金融核心以上的业务(比如在渠道层、产品层、集成层的系统),这些系统的特点是最终一致即可、流程多、流程长、还可能要调用其它公司的服务(如金融网络)。这是如果每个服务都开发 Try、Confirm、Cancel 三个方法成本高。如果事务中有其它公司的服务,也无法要��求其它公司的服务也遵循 TCC 这种开发模式。同时流程长,事务边界太长会影响性能。
对于事务我们都知道 ACID,也很熟悉 CAP 理论最多只能满足其中两个,所以,为了提高性能,出现了 ACID 的一个变种 BASE。ACID 强调的是一致性(CAP 中的 C),而 BASE 强调的是可用性(CAP 中的 A)。我们知道,在很多情况下,我们是无法做到强一致性的 ACID 的。特别是我们需要跨多个系统的时候,而且这些系统还不是由一个公司所提供的。BASE 的系统倾向于设计出更加有弹力的系统,在短时间内,就算是有数据不同步的风险,我们也应该允许新的交易可以发生,而后面我们在业务上将可能出现问题的事务通过补偿的方式处理掉,以保证最终的一致性。
所以我们在实际开发中会进行取舍,对于更多的金融核心以上的业务系统可以采用补偿事务,补偿事务处理方面在 30 年前就提出了 Saga 理论,随着微服务的发展,近些年才逐步受到大家的关注。目前业界比较也公认 Saga 是作为长事务的解决方案。
https://github.com/aphyr/dist-sagas/blob/master/sagas.pdf[1] > http://microservices.io/patterns/data/saga.html[2]
社区和业界的方案
Apache Camel Saga
Camel 是实现 EIP(Enterprise Integration Patterns)企业集成模式的一款开源产品,它基于事件驱动的架构,有着良好的性能和吞吐量,它在 2.21 版本新增加了 Saga EIP。
Saga EIP 提供了一种方式可以通过 camel route 定义一系列有关联关系的 Action,这些 Action 要么都执行成功,要么都回滚,Saga 可以协调任何通讯协议的分布式服务或本地服务,并达到全局的最终一致性。Saga 不要求整个处理在短时间内完成,因为它不占用任何数据库锁,它可以支持需要长时间处理的请求,从几秒到几天,Camel 的 Saga EIP 是基于 Microprofile 的 LRA[3](Long Running Action),同样也是支持协调任何通讯协议任何语言实现的分布式服务。
Saga 的实现不会对数据进行加锁,而是在给操作定义它的“补偿操作”,当正常流程执行出错的时候触发那些已经执行过的操作的“补偿操作”,将流程回滚掉。“补偿操作”可以在 Camel route 上用 Java 或 XML DSL(Definition Specific Language)来定义。
下面是一个 Java DSL 示例:
// action
from("direct:reserveCredit")
.bean(idService, "generateCustomId") // generate a custom Id and set it in the body
.to("direct:creditReservation")
// delegate action
from("direct:creditReservation")
.saga()
.propagation(SagaPropagation.SUPPORTS)
.option("CreditId", body()) // mark the current body as needed in the compensating action
.compensation("direct:creditRefund")
.bean(creditService, "reserveCredit")
.log("Credit ${header.amount} reserved. Custom Id used is ${body}");
// called only if the saga is cancelled
from("direct:creditRefund")
.transform(header("CreditId")) // retrieve the CreditId option from headers
.bean(creditService, "refundCredit")
.log("Credit for Custom Id ${body} refunded");
XML DSL 示例:
<route>
<from uri="direct:start"/>
<saga>
<compensation uri="direct:compensation" />
<completion uri="direct:completion" />
<option optionName="myOptionKey">
<constant>myOptionValue</constant>
</option>
<option optionName="myOptionKey2">
<constant>myOptionValue2</constant>
</option>
</saga>
<to uri="direct:action1" />
<to uri="direct:action2" />
</route>
Eventuate Tram Saga
Eventuate Tram Saga[4] 框架是使用 JDBC / JPA 的 Java 微服务的一个 Saga 框架。它也和 Camel Saga 一样采用了 Java DSL 来定义补偿操作:
public class CreateOrderSaga implements SimpleSaga<CreateOrderSagaData> {
private SagaDefinition<CreateOrderSagaData> sagaDefinition =
step()
.withCompensation(this::reject)
.step()
.invokeParticipant(this::reserveCredit)
.step()
.invokeParticipant(this::approve)
.build();
@Override
public SagaDefinition<CreateOrderSagaData> getSagaDefinition() {
return this.sagaDefinition;
}
private CommandWithDestination reserveCredit(CreateOrderSagaData data) {
long orderId = data.getOrderId();
Long customerId = data.getOrderDetails().getCustomerId();
Money orderTotal = data.getOrderDetails().getOrderTotal();
return send(new ReserveCreditCommand(customerId, orderId, orderTotal))
.to("customerService")
.build();
...
Apache ServiceComb Saga
ServiceComb Saga[5] 也是一个微服务应用的数据最终一致性解决方案。相对于 TCC 而言,在 try 阶段,Saga 会直接提交事务,后续 rollback 阶段则通过反向的补偿操作来完成。与前面两种不同是它是采用 Java 注解+拦截器的方式来进行“补偿”服务的定义。
架构:
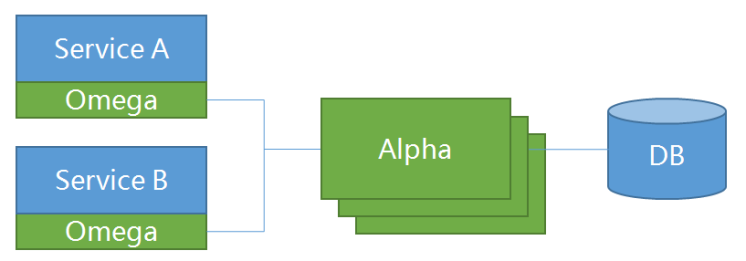
Saga 是由 alpha 和 **omega **组成,其中:
- alpha 充当协调者的角色,主要负责对事务进行管理和协调;
- omega 是微服务中内嵌的一个 agent,负责对网络请求进行拦截并向 alpha 上报事务事件;
下图展示了 alpha,omega 以及微服务三者的关系:
使用示例:
public class ServiceA extends AbsService implements IServiceA {
private static final Logger LOG = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
@Autowired
private IServiceB serviceB;
@Autowired
private IServiceC serviceC;
@Override
public String getServiceName() {
return "servicea";
}
@Override
public String getTableName() {
return "testa";
}
@Override
@SagaStart
@Compensable(compensationMethod = "cancelRun")
@Transactional(rollbackFor = Exception.class)
public Object run(InvokeContext invokeContext) throws Exception {
LOG.info("A.run called");
doRunBusi();
if (invokeContext.isInvokeB(getServiceName())) {
serviceB.run(invokeContext);
}
if (invokeContext.isInvokeC(getServiceName())) {
serviceC.run(invokeContext);
}
if (invokeContext.isException(getServiceName())) {
LOG.info("A.run exception");
throw new Exception("A.run exception");
}
return null;
}
public void cancelRun(InvokeContext invokeContext) {
LOG.info("A.cancel called");
doCancelBusi();
}
蚂蚁金服的实践
蚂蚁金服内部大规模在使用 TCC 模式分布式事务,主要用于金融核心等对一致性要求高、性能要求高的场景。在更上层的业务系统因为流程多流程长,开发 TCC 成本比较高,大都会权衡采用 Saga 模式来到达业务最终一致性,由于历史的原因不同的 BU 有自己的一套“补偿”事务的方案,基本上是两种:
- 一种是当一个服务在失败时需要“重试”或“补偿”时,在执行服务前在数据库插入一条记录,记录状态,当异常时通过定时任务去查询数据库记录并进行“重试”或“补偿”,当业务流程执行成功则删除记录;
- 另一种是设计一个状态机引擎和简单的 DSL,编排业务流程和记录业务状态,状态机引擎可以定义“补偿服务”,当异常时由状态机引擎反向调用“补偿服务”进行回滚,同时还会有一个“差错守护”平台,监控那些执行失败或补偿失败的业务流水,并不断进行“补偿”或“重试”;
方案对比
社区和业界的解决方案一般是两种,一种基本状态机或流程引擎通过 DSL 方式编排流程程和补偿定义,一种是基于 Java 注解+拦截器��实现补偿,那么这两种方案有什么优缺点呢?
| 方式 | 优点 | 缺点 |
|---|---|---|
| 状态机+DSL | - 可以用可视化工具来定义业务流程,标准化,可读性高,可实现服务编排的功能 - 提高业务分析人员与程序开发人员的沟通效率 - 业务状态管理:流程本质就是一个状态机,可以很好的反映业务状态的流转 - 提高异常处理灵活性:可以实现宕机恢复后的“向前重试”或“向后补偿” - 天然可以使用 Actor 模型或 SEDA 架构等异步处理引擎来执行,提高整体吞吐量 | - 业务流程实际是由 JAVA 程序与 DSL 配置组成,程序与配置分离,开发起来比较繁琐 - 如果是改造现有业务,对业务侵入性高 - 引擎实现成本高 |
| 拦截器+java 注解 | - 程序与注解是在一起的,开发简单,学习成本低 - 方便接入现有业务 - 基于动态代理拦截器,框架实现成本低 | - 框架无法提供 Actor 模型或 SEDA 架构等异步处理模式来提高系统吞吐量 - 框架无法提供业务状态管理 - 难以实现宕机恢复后的“向前重试”,因为无法恢复线程上下文 |
Seata Saga 的方案
Seata Saga 的简介可以看一下《Seata Saga 官网文档》[6]。
Seata Saga 采用了状态机+DSL 方案来实现,原因有以下几个:
- 状态机+DSL 方案在实际生产中应用更广泛;
- 可以使用 Actor 模型或 SEDA 架构等异步处理引擎来执行,提高整体吞吐量;
- 通常在核心系统以上层的业务系统会伴随有“服务编排”的需求,而服务编排又有事务最终一致性要求,两者很难分割开,状态机+DSL 方案可以同时满足这两个需求;
- 由于 Saga 模式在理论上是不保证隔离性的,在极端情况下可能由于脏写无法完成回滚操作,比如举一个极端的例子, 分布式事务内先给用户 A 充值,然后给用户 B 扣减余额,如果在给 A 用户充值成功,在事务提交以前,A 用户把线消费掉了,如果事务发生回滚,这时则没有办法进行补偿了,有些业务场景可以允许让业务最终成功,在回滚不了的情况下可以继续重试完成后面的流程,状态机+DSL 的方案可以实现“向前”恢复上下文继续执行的能力, 让业务最终执行成功,达到最终一致性的目的。
在不保证隔离性的情况下:业务流程设计时要遵循“宁可长款, 不可短款”的原则,长款意思是客户少了线机构多了钱,以机构信誉可以给客户退款,反之则是短款,少的线可能追不回来了。所以在业务流程设计上一定是先扣款。
状态定义语言(Seata State Language)
-
通过状态图来定义服务调用的流程并生成 json 状态语言定义文件;
-
状态图中一个节点可以是调用一个服务,节点可以配置它的补偿节点;
-
状态图 json 由状态机引擎驱动执行,当出现异常时状态引擎反向执行已成功节点对应的补偿节点将事务回滚;
注意: 异常发生时是否进行补偿也可由用户自定义决定
-
可以实现服务编排需求,支持单项选择、并发、异步、子状态机、参数转换、参数映射、服务执行状态判断、异常捕获等功能;
假设有一个业务流程要调两个服务,先调库存扣减(InventoryService),再调余额扣减(BalanceService),保证在一个分布式内要么同时成功,要么同时回滚。两个参与者服务都有一个 reduce 方法,表示库存扣减或余额扣减,还有一个 compensateReduce 方法,表示补偿扣减操作。以 InventoryService 为例看一下它的接口定义:
public interface InventoryService {
/**
* reduce
* @param businessKey
* @param amount
* @param params
* @return
*/
boolean reduce(String businessKey, BigDecimal amount, Map<String, Object> params);
/**
* compensateReduce
* @param businessKey
* @param params
* @return
*/
boolean compensateReduce(String businessKey, Map<String, Object> params);
}
这个业务流程对应的状态图:
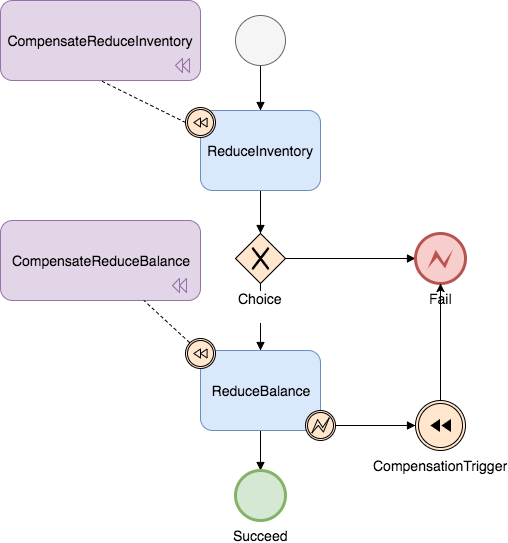
对应的 JSON
{
"Name": "reduceInventoryAndBalance",
"Comment": "reduce inventory then reduce balance in a transaction",
"StartState": "ReduceInventory",
"Version": "0.0.1",
"States": {
"ReduceInventory": {
"Type": "ServiceTask",
"ServiceName": "inventoryAction",
"ServiceMethod": "reduce",
"CompensateState": "CompensateReduceInventory",
"Next": "ChoiceState",
"Input": ["$.[businessKey]", "$.[count]"],
"Output": {
"reduceInventoryResult": "$.#root"
},
"Status": {
"#root == true": "SU",
"#root == false": "FA",
"$Exception{java.lang.Throwable}": "UN"
}
},
"ChoiceState": {
"Type": "Choice",
"Choices": [
{
"Expression": "[reduceInventoryResult] == true",
"Next": "ReduceBalance"
}
],
"Default": "Fail"
},
"ReduceBalance": {
"Type": "ServiceTask",
"ServiceName": "balanceAction",
"ServiceMethod": "reduce",
"CompensateState": "CompensateReduceBalance",
"Input": [
"$.[businessKey]",
"$.[amount]",
{
"throwException": "$.[mockReduceBalanceFail]"
}
],
"Output": {
"compensateReduceBalanceResult": "$.#root"
},
"Status": {
"#root == true": "SU",
"#root == false": "FA",
"$Exception{java.lang.Throwable}": "UN"
},
"Catch": [
{
"Exceptions": ["java.lang.Throwable"],
"Next": "CompensationTrigger"
}
],
"Next": "Succeed"
},
"CompensateReduceInventory": {
"Type": "ServiceTask",
"ServiceName": "inventoryAction",
"ServiceMethod": "compensateReduce",
"Input": ["$.[businessKey]"]
},
"CompensateReduceBalance": {
"Type": "ServiceTask",
"ServiceName": "balanceAction",
"ServiceMethod": "compensateReduce",
"Input": ["$.[businessKey]"]
},
"CompensationTrigger": {
"Type": "CompensationTrigger",
"Next": "Fail"
},
"Succeed": {
"Type": "Succeed"
},
"Fail": {
"Type": "Fail",
"ErrorCode": "PURCHASE_FAILED",
"Message": "purchase failed"
}
}
}
状态语言在一定程度上参考了 AWS Step Functions[7]。
"状态机" 属性简介:
- Name: 表示状态机的名称,必须唯一;
- Comment: 状态机的描述;
- Version: 状态机定义版本;
- StartState: 启动时运行的第一个"状态";
- States: 状态列表,是一个 map 结构,key 是"状态"的名称,在状态机内必须唯一;
"状态" 属性简介:
- Type:"状态" 的类型,比如有:
- ServiceTask: 执行调用服务任务;
- Choice: 单条件选择路由;
- CompensationTrigger: 触发补偿流程;
- Succeed: 状态机正常结束;
- Fail: 状态机异常结束;
- SubStateMachine: 调用子状态机;
- ServiceName: 服务名称,通常是服务的 beanId;
- ServiceMethod: 服务方法名称;
- CompensateState: 该"状态"的补偿"状态";
- Input: 调用服务的输入参数列表,是一个数组,对应于服务方法的参数列表, $.表示使用表达式从状态机上下文中取参数,表达使用的 SpringEL[8], 如果是常量直接写值即可;
- Output: 将服务返回的参数赋值到状态机上下文中,是一个 map 结构,key 为放入到状态机上文时的 key(状态机上下文也是一个 map),value 中 $. 是表示 SpringEL 表达式,表示从服务的返回参数中取值,#root 表示服务的整个返回参数;
- Status: 服务执行状态映射,框架定义了三个状态,SU 成功、FA 失败、UN 未知,我们需要把服务执行的状态映射成这三个状态,帮助框架判断整个事务的一致性,是一个 map 结构,key 是条件表达式,一般是取服务的返回值或抛出的异常进行判断,默认是 SpringEL 表达式判断服务返回参数,带 $Exception{开头表示判断异常类型,value 是当这个条件表达式成立时则将服务执行状态映射成这个值;
- Catch: 捕获到异常后的路由;
- Next: 服务执行完成后下一个执行的"状态";
- Choices: Choice 类型的"状态"里, 可选的分支列表, 分支中的 Expression 为 SpringEL 表达式,Next 为当表达式成立时执行的下一个"状态";
- ErrorCode: Fail 类型"状态"的错误码;
- Message: Fail 类型"状态"的错误信息�;
更多详细的状态语言解释请看《Seata Saga 官网文档》[6http://seata.io/zh-cn/docs/user/saga.html]。
状态机引擎原理:
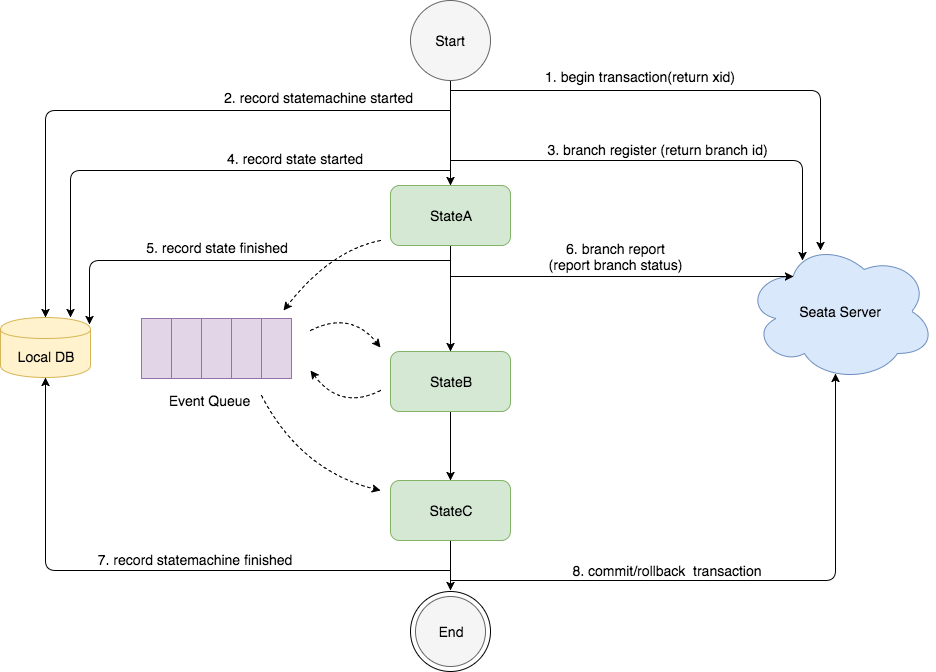
- 图中的状态图是先执行 stateA, 再执行 stataB,然后执行 stateC;
- "状态"的执行是基于事件驱动的模型,stataA 执行完成后,会产生路由消息放入 EventQueue,事件消费端从 EventQueue 取出消息,执行 stateB;
- 在整个状态机启动时会调用 Seata Server 开启分布式事务,并生产 xid, 然后记录"状态机实例"启动事件到本地数据库;
- 当执行到一个"状态"时会调用 Seata Server 注册分支事务,并生产 branchId, 然后记录"状态实例"开始执行事件到本地数据库;
- 当一个"状态"执行完成后会记录"状态实例"执行结束事件到本地数据库, 然后调用 Seata Server 上报分支事务的状态;
- 当整个状态机执行完成,会记录"状态机实例"执行完成事件到本地数据库, 然后调用 Seata Server 提交或回滚分布式事务;
状态机引擎设计:
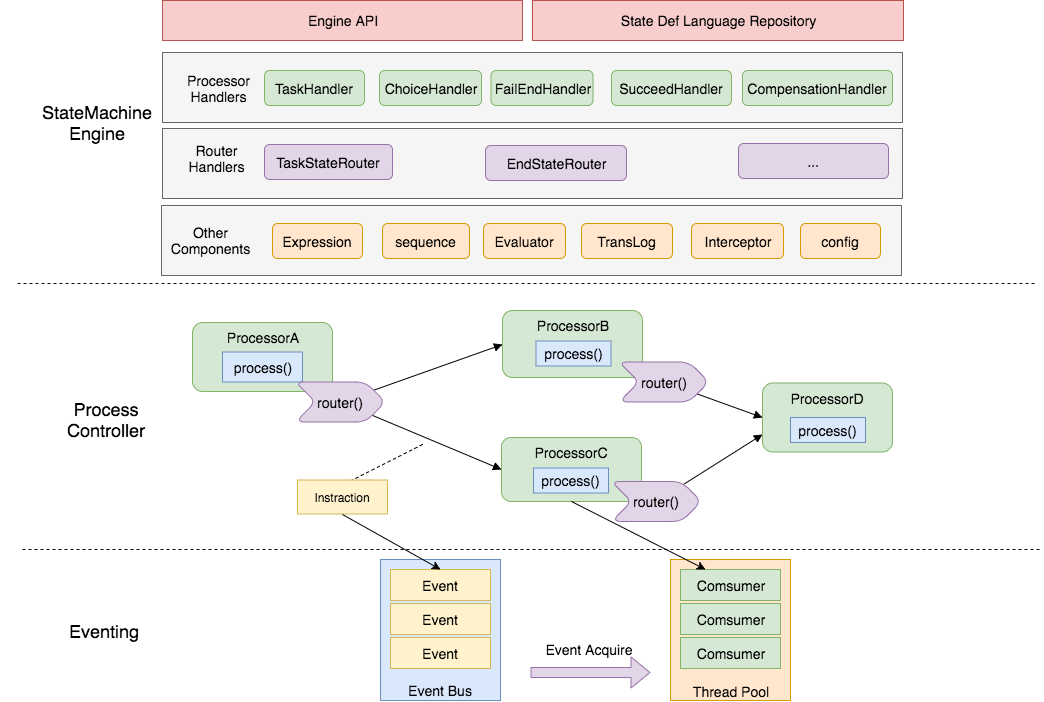
状态机引擎的设计主要分成三层, 上层依赖下层,从下往上分别是:
-
Eventing 层:
- 实现事件驱动架构, 可以压入事件, 并由消费端消费事件, 本层不关心事件是什么消费端执行什么,由上层实现;
-
ProcessController 层:
- 由于上层的 Eventing 驱动一个“空”流程执行的执行,"state"的行为和路由都未实现,由上层实现;
基于以上两层理论上可以自定义扩展任何"流程"引擎。这两层的设计是参考了内部金融网络平台的设计。
- 由于上层的 Eventing 驱动一个“空”流程执行的执行,"state"的行为和路由都未实现,由上层实现;
-
StateMachineEngine 层:
- 实现状态机引擎每种 state 的行为和路由逻辑;
- 提供 API、状态机语言仓库;
Saga 模式下服务设计的实践经验
下面是实践中总结的在 Saga 模式下微服务设计的一些经验,当然这是推荐做法,并不是说一定要 100% 遵循,没有遵循也有“绕过”方案。
好消息:Seata Saga 模式对微服务的接口参数没有任务要求,这使得 Saga 模式可用于集成遗留系统或外部机构的服务。
允许空补偿
- 空补偿:原服务未执行,补偿服务执行了;
- 出现原因:
- 原服务 超时(丢包);
- Saga 事务触发 回滚;
- 未收到原服务请求,先收到补偿请求;
所以服务设计时需要允许空补偿,即没有找到要补偿的业务主键时返回补偿成功并将原业务主键记录下来。
防悬挂控制
- 悬挂:补偿服务 比 原服务 先执行;
- 出现原因:
- 原服务 超时(拥堵);
- Saga 事务回滚,触发 回滚;
- 拥堵的原服务到达;
所以要检查当前业务主键是否已经在空补偿记录下来的业务主键中存在,如果存在则要拒绝服务的执行。
幂等控制
- 原服务与补偿服务都需要保证幂等性, 由于网络可能超时,可以设置重试策略,重试发生时要通过幂等控制避免业务数据重复更新。
总结
很多时候我们不需要强调强一性,我们基于 BASE 和 Saga 理论去设计更有弹性的系统,在分布式架构下获得更好的性能和容错能力。分布式架构没有银弹,只有适合特定场景的方案,事实上 Seata Saga 是一个具备“服务编排”和“Saga 分布式事务”能力的产品,总结下来它的适用场景是:
- 适用于微服务架构下的“长事务”处理;
- 适用于微服务架构下的“服务编排”需求;
- 适用于金融核心系统以上的有大量组合服务的业务系统(比如在渠道层、产品层、集成层的系统);
- 适用于业务流程中需要集成遗留系统或外部机构提供的服务的场景(这些服务不可变不能对其提出改造要求)。
文中涉及相关链接
[1]https://github.com/aphyr/dist-sagas/blob/master/sagas.pdf
[2]http://microservices.io/patterns/data/saga.html
[3]Microprofile 的 LRA:https://github.com/eclipse/microprofile-sandbox/tree/master/proposals/0009-LRA
[4]Eventuate Tram Saga:https://github.com/eventuate-tram/eventuate-tram-sagas
[5]ServiceComb Saga:https://github.com/apache/servicecomb-pack
[6]Seata Saga 官网文档:http://seata.io/zh-cn/docs/user/saga.html
[7]AWS Step Functions:https://docs.aws.amazon.com/zh_cn/step-functions/latest/dg/tutorial-creating-lambda-state-machine.html
[8]SpringEL:https://docs.spring.io/spring/docs/4.3.10.RELEASE/spring-framework-reference/html/expressions.html