引言和概述
上一篇Seata的RPC通信源码分析01:传输篇已经介绍了RPC通信的传输机制,这一篇我们继续来看协议部分的内容,把这个图里没解析清楚的encode/decode部分给补充完整。

同样的,我们以提问来深入的方式去探究它。在本文中,我们不仅要了解二进制如何解析成rpcMsg类型,还要知道如何兼容不同版本的协议,那么第一个问题:协议长什么样?
协议结构

上图展示了协议在0.7.1之前和之后的变化,(在ProtocolDecoderV1的注释也可以看到,更旧版本的要看ProtocolV1Decoder),可以看到新版本的有以下这些构成部分
- magic-code:0xdada
- protocal-verson:版本号
- full-length:总长度
- head-length:头部长度
- msgtype:消息类型
- serializer/codecType:序列化方式
- compress:压缩方式
- requestid:请求id
这里我们说明一下seata各版本的server之间对协议的处理差异
- version
<0.7.1 : 只能处理v0版本的协议(上图中的上半部分,带有flag段的),无法识别其他版本协议 - 0.7.1
<=version<2.2.0 : 只能处理v1版本的协议(上图中的下半部分),无法识别其他版本协议 - version
>=2.2.0 : 可以同时识别v0和v1版本的协议,并处理
那么2.2.0是怎样做到兼容的呢?先卖个关子,在说明这个之前我们先看看v1的encoder和decoder分别都是怎样运作的。需要注意的是,和之前提到的传输机制一样,协议处理也是client和server共用的,所以下面提到的都是通用逻辑。
从ByteBuf到RpcMessage(Encoder/Decoder做了什么)
先来看ProtocolDecoderV1
public RpcMessage decodeFrame(ByteBuf frame) {
byte b0 = frame.readByte();
byte b1 = frame.readByte();
// 获取version
byte version = frame.readByte();
// 获取header和body以外的字段
int fullLength = frame.readInt();
short headLength = frame.readShort();
byte messageType = frame.readByte();
byte codecType = frame.readByte();
byte compressorType = frame.readByte();
int requestId = frame.readInt();
ProtocolRpcMessageV1 rpcMessage = new ProtocolRpcMessageV1();
rpcMessage.setCodec(codecType);
rpcMessage.setId(requestId);
rpcMessage.setCompressor(compressorType);
rpcMessage.setMessageType(messageType);
// 头部信息
int headMapLength = headLength - ProtocolConstants.V1_HEAD_LENGTH;
if (headMapLength > 0) {
Map<String, String> map = HeadMapSerializer.getInstance().decode(frame, headMapLength);
rpcMessage.getHeadMap().putAll(map);
}
// 如果是心跳信息不需要对body进行序列化
if (messageType == ProtocolConstants.MSGTYPE_HEARTBEAT_REQUEST) {
rpcMessage.setBody(HeartbeatMessage.PING);
} else if (messageType == ProtocolConstants.MSGTYPE_HEARTBEAT_RESPONSE) {
rpcMessage.setBody(HeartbeatMessage.PONG);
} else {
int bodyLength = fullLength - headLength;
if (bodyLength > 0) {
byte[] bs = new byte[bodyLength];
frame.readBytes(bs);
// 根据刚才得到的compressorType来按需做解压处理
Compressor compressor = CompressorFactory.getCompressor(compressorType);
bs = compressor.decompress(bs);
SerializerType protocolType = SerializerType.getByCode(rpcMessage.getCodec());
if (this.supportDeSerializerTypes.contains(protocolType)) {
// 序列化器,由于这个是v1专用的ProtocolDecoderV1,所以可以直接传入version1
Serializer serializer = SerializerServiceLoader.load(protocolType, ProtocolConstants.VERSION_1);
rpcMessage.setBody(serializer.deserialize(bs));
} else {
throw new IllegalArgumentException("SerializerType not match");
}
}
}
return rpcMessage.protocolMsg2RpcMsg();
}
由于encode操作正好和decode操作相反,这里不再重复介绍,我们继续看里面的serialize操作。上面的serialize类来自SerializerServiceLoader
public static Serializer load(SerializerType type, byte version) throws EnhancedServiceNotFoundException {
// 先处理PROTOBUF方式的序列化,通过反射工具取得
if (type == SerializerType.PROTOBUF) {
try {
ReflectionUtil.getClassByName(PROTOBUF_SERIALIZER_CLASS_NAME);
} catch (ClassNotFoundException e) {
throw new EnhancedServiceNotFoundException("'ProtobufSerializer' not found. " +
"Please manually reference 'org.apache.seata:seata-serializer-protobuf' dependency ", e);
}
}
String key = serialzerKey(type, version);
// 这里是一个SERIALIZER_MAP,相当于序列化类的缓存。为什么需要缓存,因为SeataSerializer的scope = Scope.PROTOTYPE,防止多次创建类
Serializer serializer = SERIALIZER_MAP.get(key);
if (serializer == null) {
if (type == SerializerType.SEATA) {
// 这里是seata的SPI机制,本文不再往里深入加载类的逻辑,只需要知道去加载Serializer这个接口,并且把version给到了构造方法
serializer = EnhancedServiceLoader.load(Serializer.class, type.name(), new Object[]{version});
} else {
serializer = EnhancedServiceLoader.load(Serializer.class, type.name());
}
SERIALIZER_MAP.put(key, serializer);
}
return serializer;
}
// 这里是SeataSerializer构造方法,里面是单例模式的构造器,因为现在是两个版本各一个类,也可以说是双例
public SeataSerializer(Byte version) {
if (version == ProtocolConstants.VERSION_0) {
versionSeataSerializer = SeataSerializerV0.getInstance();
} else if (version == ProtocolConstants.VERSION_1) {
versionSeataSerializer = SeataSerializerV1.getInstance();
}
if (versionSeataSerializer == null) {
throw new UnsupportedOperationException("version is not supported");
}
}
这样,decoder就得到了一个Serializer,程序运行到rpcMessage.setBody(serializer.deserialize(bs)),我们来看看deserialize是怎样处理的
public <T> T deserialize(byte[] bytes) {
return deserializeByVersion(bytes, ProtocolConstants.VERSION_0);
}
private static <T> T deserializeByVersion(byte[] bytes, byte version) {
//前面是合法性判断,此处忽略
ByteBuffer byteBuffer = ByteBuffer.wrap(bytes);
short typecode = byteBuffer.getShort();
ByteBuffer in = byteBuffer.slice();
//创建父类,并根据版本号创建Codec
AbstractMessage abstractMessage = MessageCodecFactory.getMessage(typecode);
MessageSeataCodec messageCodec = MessageCodecFactory.getMessageCodec(typecode, version);
//codec的decode操作
messageCodec.decode(abstractMessage, in);
return (T) abstractMessage;
}
很遗憾,这个serialize并没有太多逻辑,关键还是在MessageCodecFactory和Codec,我们继续往里看。可以看到MessageCodecFactory内容不少,但形式单一,都是根据MessageType返回message和codec,所以这里不再展示factory的内容,我们直接看message和codec,也就是messageCodec.decode(abstractMessage, in),虽然codec类型还是很多,但我们可以看到他们的结构都是相似的,逐个字段解析:
// BranchRegisterRequestCodec的decode,这个请求是注册一个事务分支
public <T> void decode(T t, ByteBuffer in) {
BranchRegisterRequest branchRegisterRequest = (BranchRegisterRequest)t;
// 解析xid
short xidLen = in.getShort();
if (xidLen > 0) {
byte[] bs = new byte[xidLen];
in.get(bs);
branchRegisterRequest.setXid(new String(bs, UTF8));
}
// 解析branchType
branchRegisterRequest.setBranchType(BranchType.get(in.get()));
short len = in.getShort();
if (len > 0) {
byte[] bs = new byte[len];
in.get(bs);
branchRegisterRequest.setResourceId(new String(bs, UTF8));
}
// 解析lockKey
int iLen = in.getInt();
if (iLen > 0) {
byte[] bs = new byte[iLen];
in.get(bs);
branchRegisterRequest.setLockKey(new String(bs, UTF8));
}
// 解析applicationData
int applicationDataLen = in.getInt();
if (applicationDataLen > 0) {
byte[] bs = new byte[applicationDataLen];
in.get(bs);
branchRegisterRequest.setApplicationData(new String(bs, UTF8));
}
}
好了,到这里,我们已经得到了branchRegisterRequest,可以愉快地交给TCInboundHandler处理了。
但是问题又来了,我们只看到client(RM/TM)有以下这种添加encoder/decoder的代码,也就是我们知道client都使用当前版本的encoder/decoder处理:
bootstrap.handler(
new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new IdleStateHandler(nettyClientConfig.getChannelMaxReadIdleSeconds(),nettyClientConfig.getChannelMaxWriteIdleSeconds(),nettyClientConfig.getChannelMaxAllIdleSeconds()))
.addLast(new ProtocolDecoderV1())
.addLast(new ProtocolEncoderV1());
if (channelHandlers != null) {
addChannelPipelineLast(ch, channelHandlers);
}
}
});
但server如何处理?还有说好的多版本协议呢?
多版本协议(版本识别和绑定)
我们先来看encoder/decoder的一个类图:
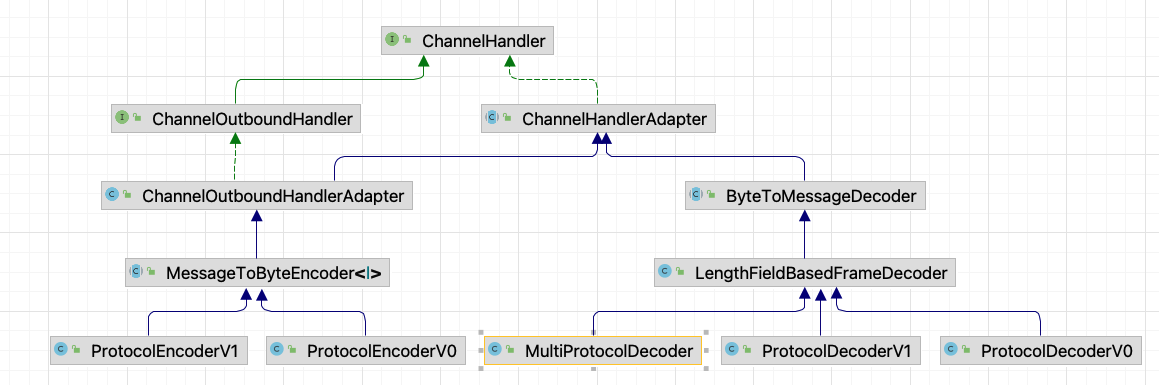
ProtocolDecoderV1我们已经分析完了,ProtocolEncoderV1是反向操作,应该比较好理解,至于ProtocolDecoderV0和ProtocolEncoderV0,从图上也可以看到他们和v1是平行关系,除了v0的操作(虽然目前为止我们还没让他派上用场),他们都是netty里典型的encode和decode的子类,但MultiProtocolDecoder又是什么?他是多版本协议的主角,而且在启动的时候已经注册进server的bootstrap。
protected boolean isV0(ByteBuf in) {
boolean isV0 = false;
in.markReaderIndex();
byte b0 = in.readByte();
byte b1 = in.readByte();
// 实际上,识别协议就靠第3个byte(b2),只要是正常的新版本,b2就是大于0的版本号,而对于0.7以下的版本来说,b2是FLAG的第一位,正好无论是哪种情况他都是0
// v1/v2/v3 : b2 = version
// v0 : b2 = 0 ,1st byte in FLAG(2byte:0x10/0x20/0x40/0x80)
byte b2 = in.readByte();
if (ProtocolConstants.MAGIC_CODE_BYTES[0] == b0 && ProtocolConstants.MAGIC_CODE_BYTES[1] == b1 && 0 == b2) {
isV0 = true;
}
// 读完的字节还要吐回去,为了让各版本的decoder能从头解析
in.resetReaderIndex();
return isV0;
}
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
ByteBuf frame;
Object decoded;
byte version;
try {
// 识别版本号,获取当前版本号
if (isV0(in)) {
decoded = in;
version = ProtocolConstants.VERSION_0;
} else {
decoded = super.decode(ctx, in);
version = decideVersion(decoded);
}
if (decoded instanceof ByteBuf) {
frame = (ByteBuf) decoded;
ProtocolDecoder decoder = protocolDecoderMap.get(version);
ProtocolEncoder encoder = protocolEncoderMap.get(version);
try {
if (decoder == null || encoder == null) {
throw new UnsupportedOperationException("Unsupported version: " + version);
}
// 首次进来,使用判断好的decoder进行操作
return decoder.decodeFrame(frame);
} finally {
if (version != ProtocolConstants.VERSION_0) {
frame.release();
}
// 首次进来,绑定对应version的encoder和decoder,也就相当于绑定了channel
ctx.pipeline().addLast((ChannelHandler)decoder);
ctx.pipeline().addLast((ChannelHandler)encoder);
if (channelHandlers != null) {
ctx.pipeline().addLast(channelHandlers);
}
// 绑定好之后,将自身移除,后续不再判断
ctx.pipeline().remove(this);
}
}
} catch (Exception exx) {
LOGGER.error("Decode frame error, cause: {}", exx.getMessage());
throw new DecodeException(exx);
}
return decoded;
}
protected byte decideVersion(Object in) {
if (in instanceof ByteBuf) {
ByteBuf frame = (ByteBuf) in;
frame.markReaderIndex();
byte b0 = frame.readByte();
byte b1 = frame.readByte();
// 和isV0方法相似,取第3个byte
if (ProtocolConstants.MAGIC_CODE_BYTES[0] != b0 || ProtocolConstants.MAGIC_CODE_BYTES[1] != b1) {
throw new IllegalArgumentException("Unknown magic code: " + b0 + ", " + b1);
}
byte version = frame.readByte();
frame.resetReaderIndex();
return version;
}
return -1;
}
通过上面的分析,v0终于派上用场(当有旧版本的client注册时,server就会为其分配低版本的encoder/decoder),我们也摸清了多版本协议如何识别、如何绑定。