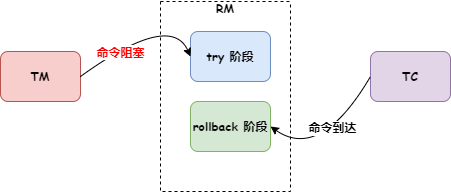
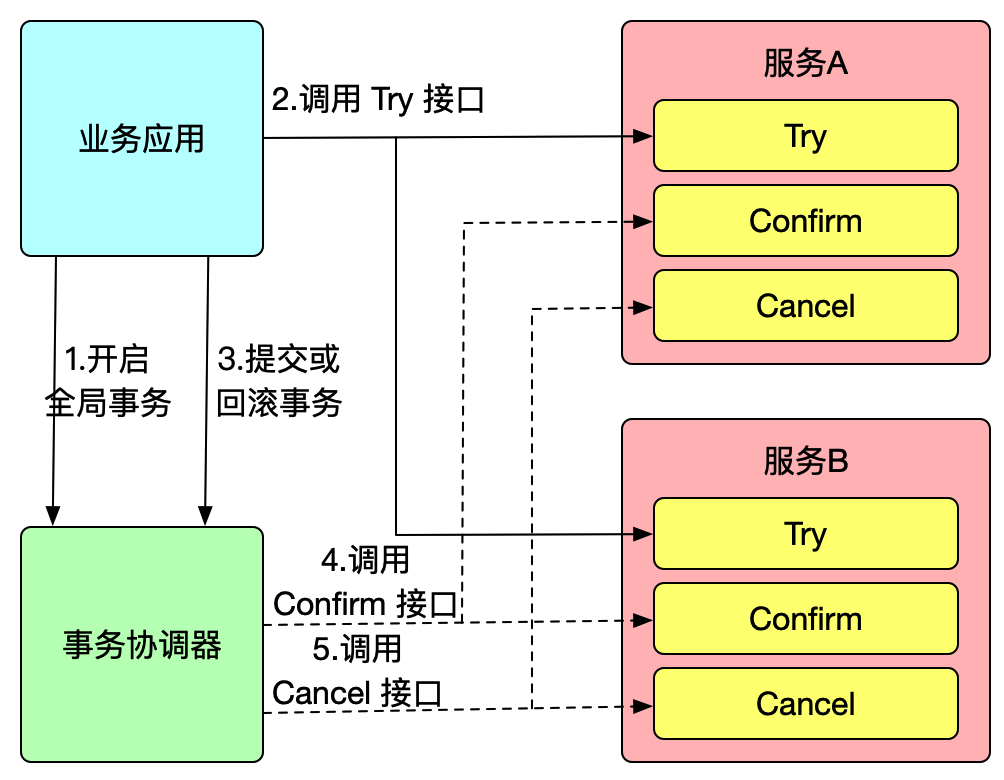
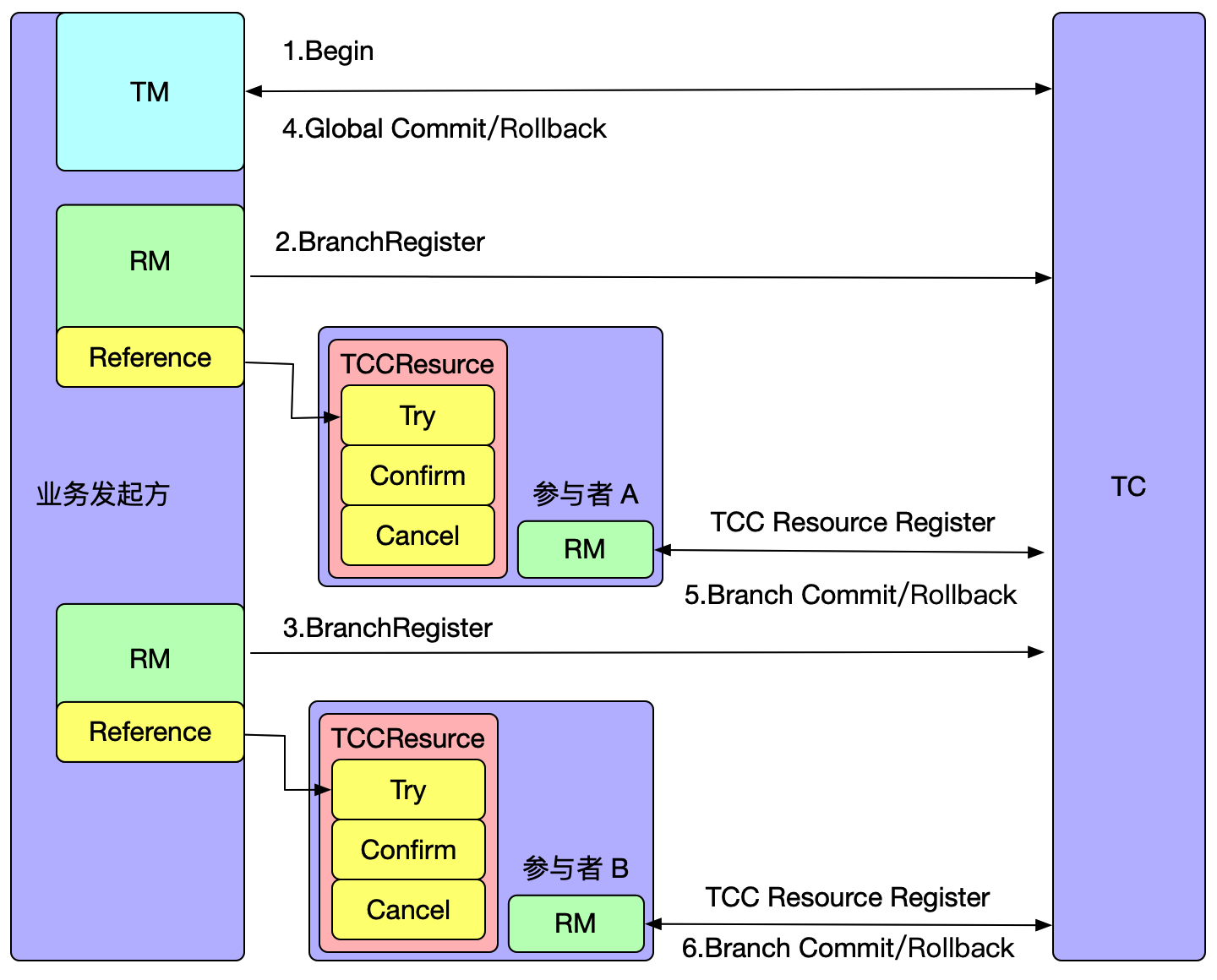
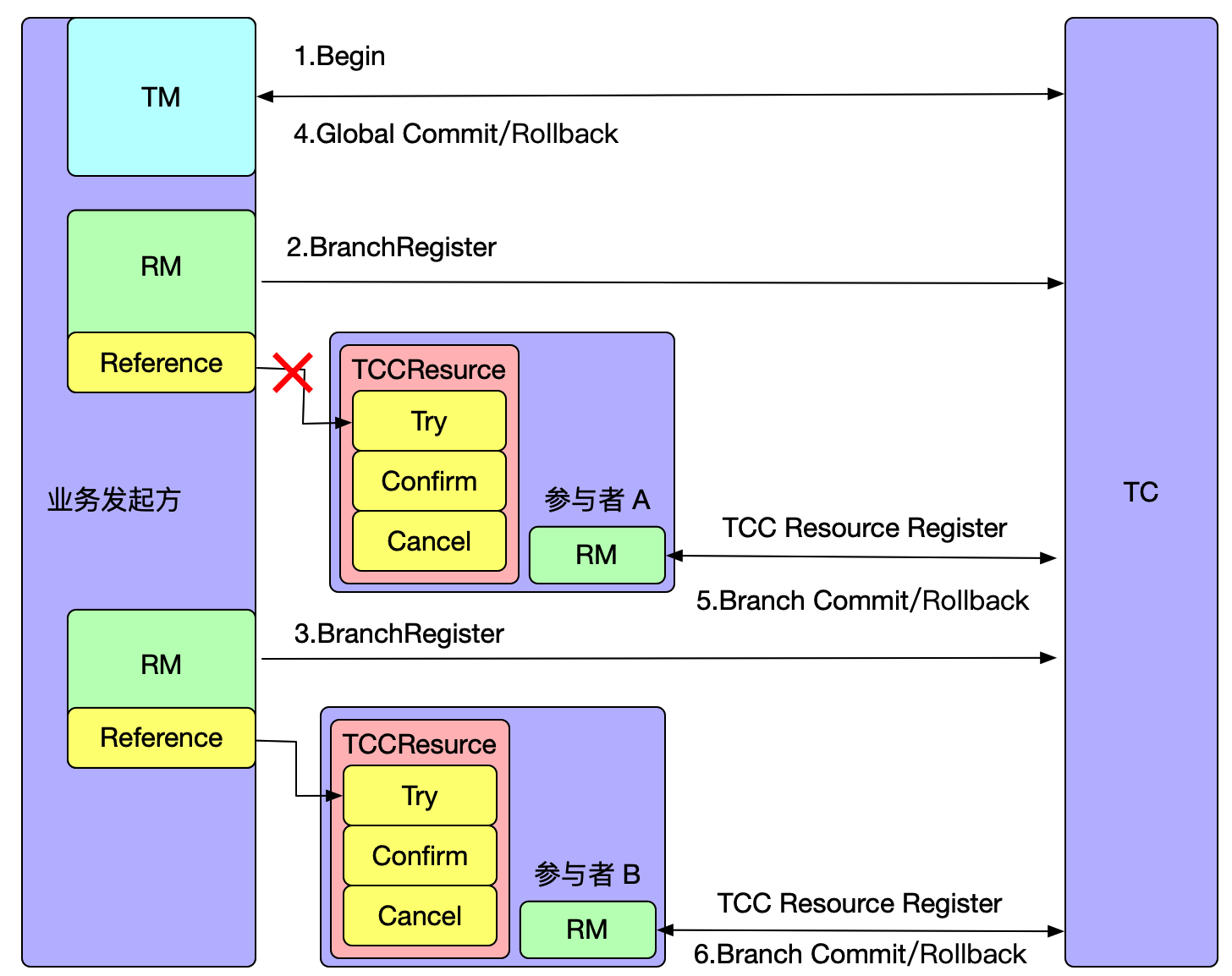
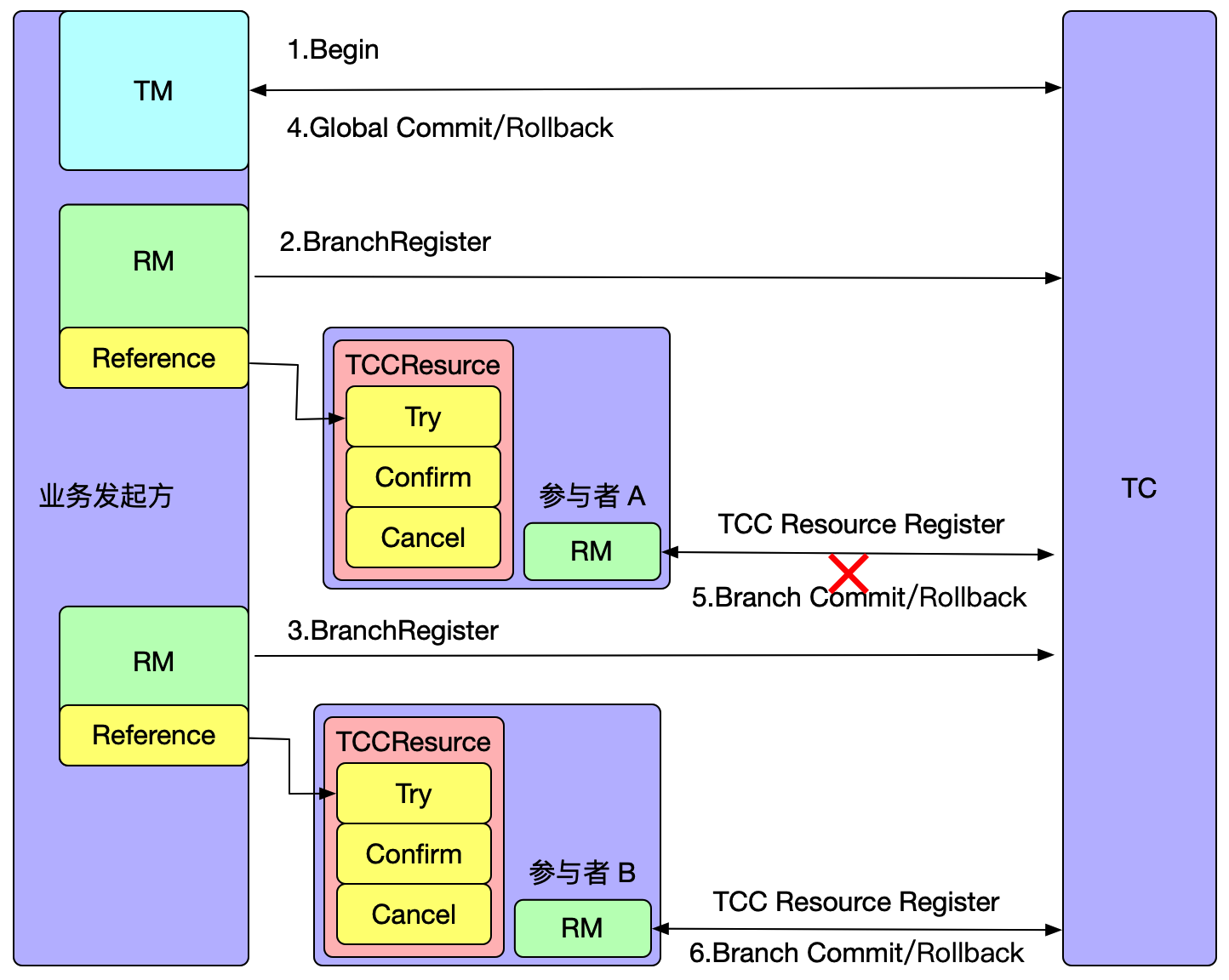
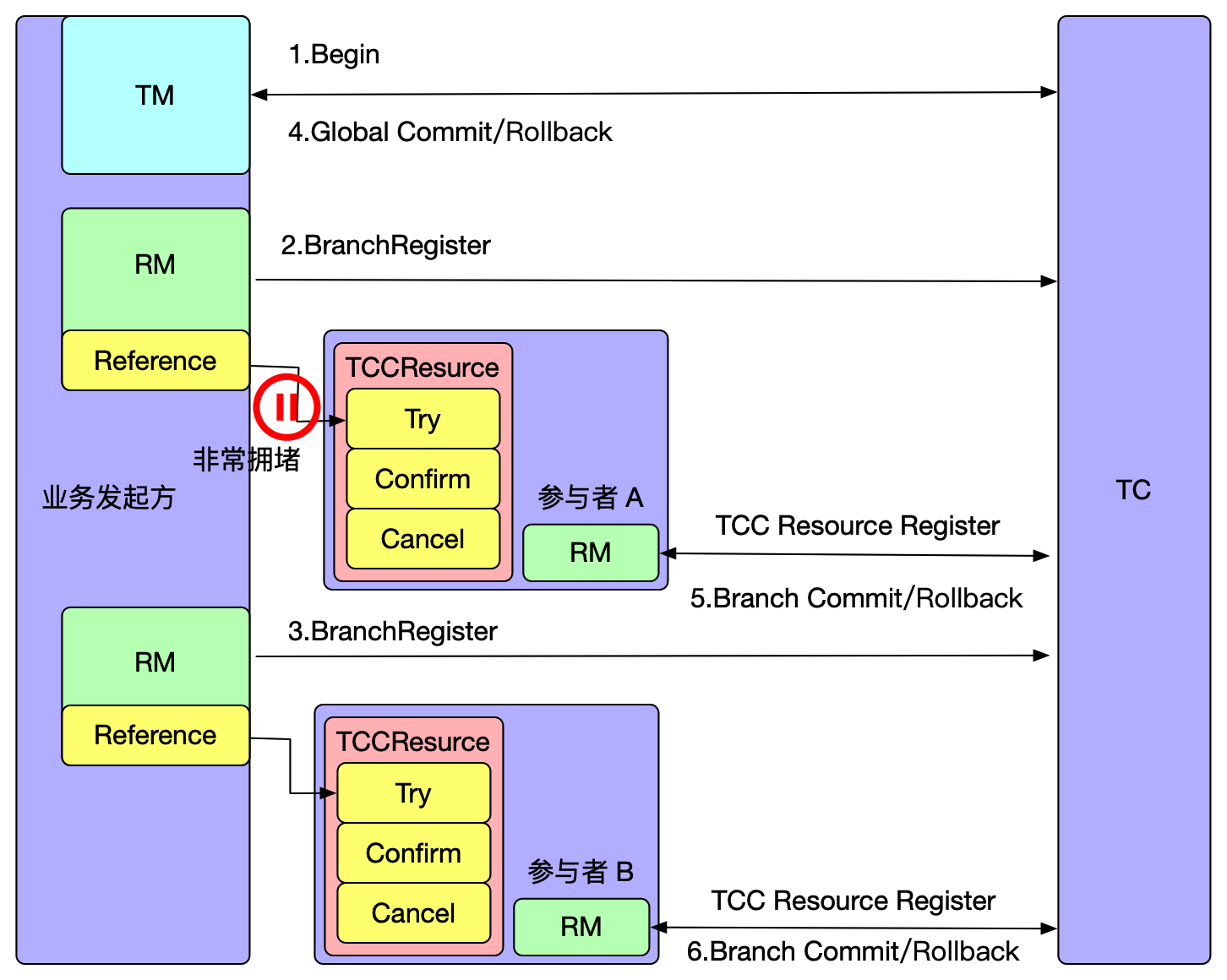
Seata 是一款开源的分布式事务解决方案,star高达24000+,社区活跃度极高,致力于在微服务架构下提供高性能和简单易用的分布式事务服务.
目前Seata的分布式事务数据存储模式有file,db,redis,而本篇文章将Seata-Server Raft模式的架构,部署使用,压测对比,及为什么Seata需要Raft,并领略从调研对比,设计,到具体实现,再到知识沉淀的过程.
分享人:陈健斌(funkye) github id: funky-eyes
2. 架构介绍
2.1 Raft 模式是什么?
首先需要明白什么是raft分布式一致性算法,这里直接摘抄sofa-jraft官网的相关介绍:
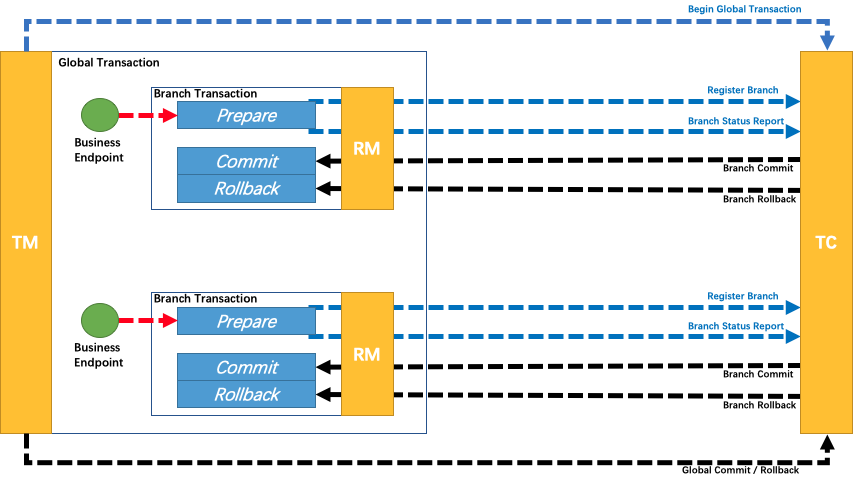
RAFT 是一种新型易于理解的分布式一致性复制协议,由斯坦福大学的 Diego Ongaro 和 John Ousterhout 提出,作为 RAMCloud 项目中的中心协调组件。Raft 是一种 Leader-Based 的 Multi-Paxos 变种,相比 Paxos、Zab、View Stamped Replication 等协议提供了更完整更清晰的协议描述,并提供了清晰的节点增删描述。 Raft 作为复制状态机,是分布式系统中最核心最基础的组件,提供命令在多个节点之间有序复制和执行,当多个节点初始状态一致的时候,保证节点之间状态一致。
简而言之Seata的Raft模式就是基于Sofa-Jraft组件实现可保证Seata-Server自身的数据一致性和服务高可用.
2.2 为什么需要raft模式
看完上述的Seata-Raft模式是什么的定义后,是否就有疑问,难道现在Seata-Server就无法保证一致性和高可用了吗?那么下面从一致性和高可用来看看目前Seata-Server是如何做的.
2.2.1 现有存储模式
在当前的 Seata 设计中,Server 端的作用是保证事务的二阶段被正确执行。然而,这取决于事务记录的正确存储。为确保事务记录不丢失,需要在保持状态正确的前提下,驱动所有的 Seata-RM 执行正确的二阶段行为。那么,Seata 目前是如何存储事务状态和记录的呢?
首先介绍一下 Seata 支持的三种事务存储模式:file、db 和 redis。根据一致性的排名,db 模式下的事务记录可以得到最好的保证,其次是 file 模式的异步刷盘,最后是 redis 模式下的 aof 和 rdb
顾名思义:
- file 模式是 Seata 自实现的事务存储方式,它以顺序写的形式将事务信息存储到本地磁盘上。为了兼顾性能,默认采用异步方式,并将事务信息存储在内存中,确保内存和磁盘上的数据一致性。当 Seata-Server(TC)意外宕机时,在重新启动时会从磁盘读取事务信息并恢复到内存中,以便继续运行事务上下文。
- db 是 Seata 的抽象事务存储管理器(AbstractTransactionStoreManager)的另一种实现方式。它依赖于数据库,如 PostgreSQL、MySQL、Oracle 等,在数据库中进行事务信息的增删改查操作。一致性由数据库的本地事务保证,数据也由数据库负责持久化到磁盘。
- redis 和 db 类似,也是一种事务存储方式。它利用 Jedis 和 Lua 脚本来进行事务的增删改查操作,部分操作(如竞争锁)在 Seata 2.x 版本中全部采用了 Lua 脚本。数据的存储与 db 类似,依赖于存储方(Redis)来保证数据的一致性。与 db 类似,redis 在 Seata 中采用了计算和存储分离的架构设计.
2.2.2 高可用
高可用简单理解就是集群能够在主节点宕机后继续正常运行,常见的方式是通过部署多个提供相同服务的节点,并通过注册中心实时感知主节点的上下线情况,以便及时切换到可用的节点。
看起来似乎只需要加几台机器进行部�署,但实际上背后存在一个问题,即如何确保多个节点像一个整体一样运作。如果其中一个节点宕机,另一个节点能够完美接替宕机节点的工作,包括处理宕机节点的数据。解决这个问题的答案其实很简单,在计算与存储分离的架构下,只需将数据存储在共享的存储中间件中,任何一个节点都可以通过访问该公共存储区域获取所有节点操作的事务信息,从而实现高可用的能力。
然而,前提条件是计算与存储必须分离。为什么计算与存储一体化设计不可行呢?这就要说到 File 模式的实现了。如之前描述的,File 模式将数据存储在本地磁盘和节点内存中,数据写操作没有任何同步,这意味着目前的 File 模式无法实现高可用,仅支持单机部署。作为初级的快速入门和简单使用而言,File 模式适用性较低,高性能的基于内存的 File 模式也基本上不再被生产环境使用。
2.3 Seata-Raft是如何设计的呢?
2.3.1 设计原理
Seata-Raft模式的设计思路是通过封装无法高可用的file模式,利用Raft算法实现多个TC之间数据的同步。该模式保证了使用file模式时多个TC的数据一致性,同时将异步刷盘操作改为使用Raft日志和快照进行数据恢复。
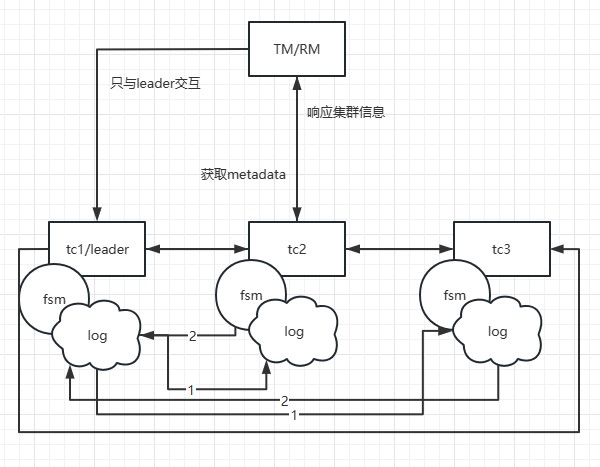
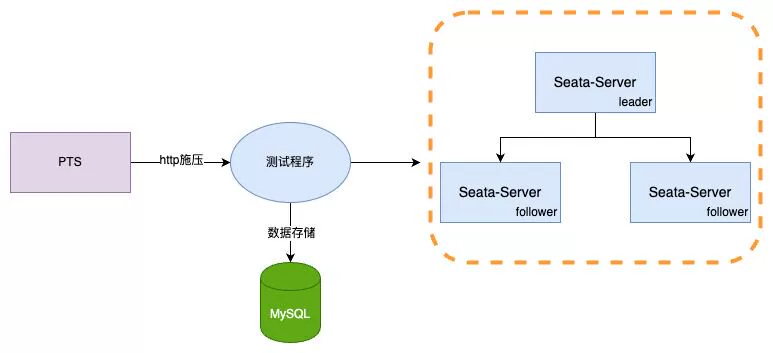
在Seata-Raft模式中,client端在启动时会从配置中心获取当前client的事务分组(例如default)以及相关Raft集群节点的IP地址。通过向Seata-Server的控制端口发送请求,client可以获取到default分组对应的Raft集群的元数据,包括leader、follower和learner成员节点。然后,client会监视(watch)非leader节点的任意成员节点。
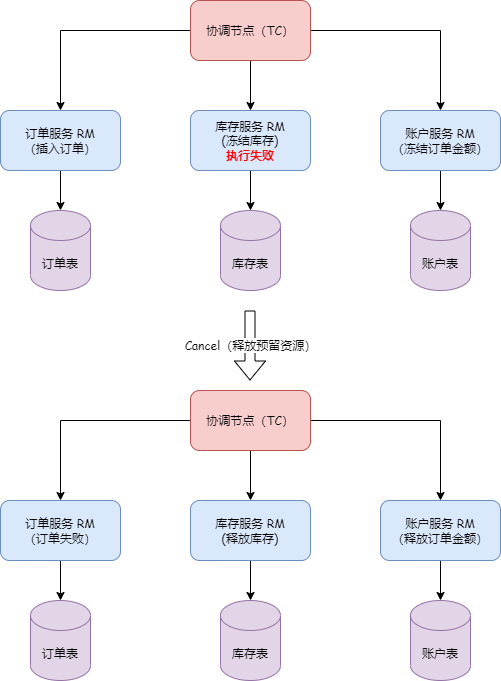
假设TM开始一个事务,并且本地的metadata中的leader节点指向了TC1的地址,那么TM只会与TC1进行交互。当TC1添加一个全局事务信息时,通过Raft协议,即图中标注为步骤1的日志发送,TC1会将日志发送给其他节点,步骤2是follower节点响应日志接收情况。当超过半数的节点(如TC2)接受并响应成功时,TC1上的状态机(FSM)将执行添加全局事务的动作。
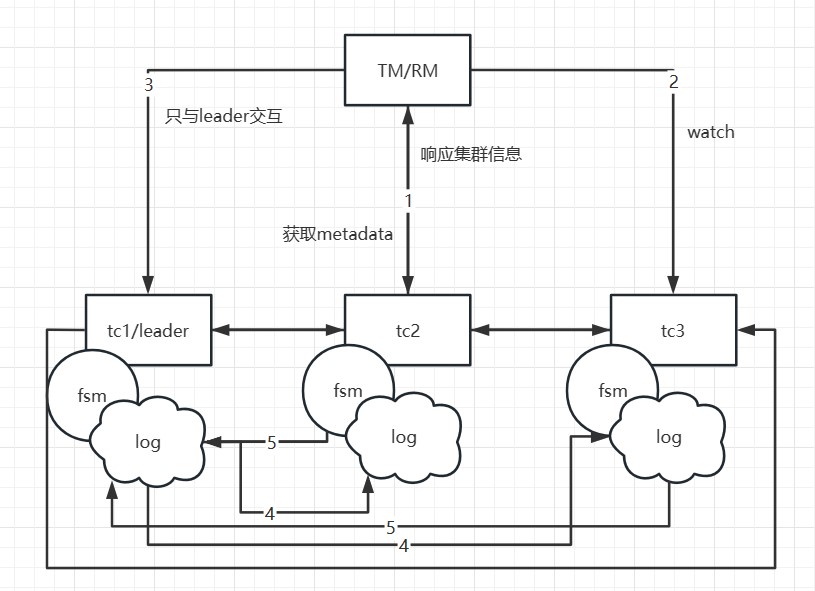
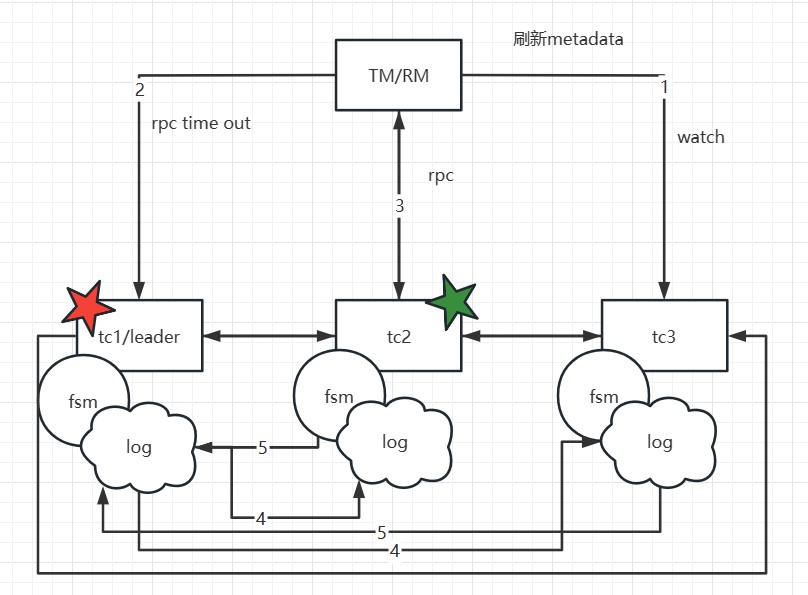
如果TC1宕机或发生重选举,会发生什么呢?由于首次启动时已经获取到了元数据,client会执行watch follower节点的接口来更新本地的metadata信息。因此,后续的事务请求将发送到新的leader(例如TC2)。同时,TC1的数据已经被同步到了TC2和TC3,因此数据一致性不会受到影响。只在选举发生的瞬间,如果某个事务正好发送给了旧的leader,该事务会被主动回滚,以确保数据的正确性。
需要注意的是,在该模式下,如果事务处于决议发送请求或一阶段流程还未走完的时刻,并且恰好在选举时发生,这些事务会被主动回滚。因为RPC节点已经宕机或发生了重选举,当前没有实现RPC重试。TM侧默认有5次重试机�制,但由于选举需要大约1s-2s的时间,这些处于begin状态的事务可能无法成功决议,因此会优先回滚,释放锁,以避免影响其他业务的正确性。
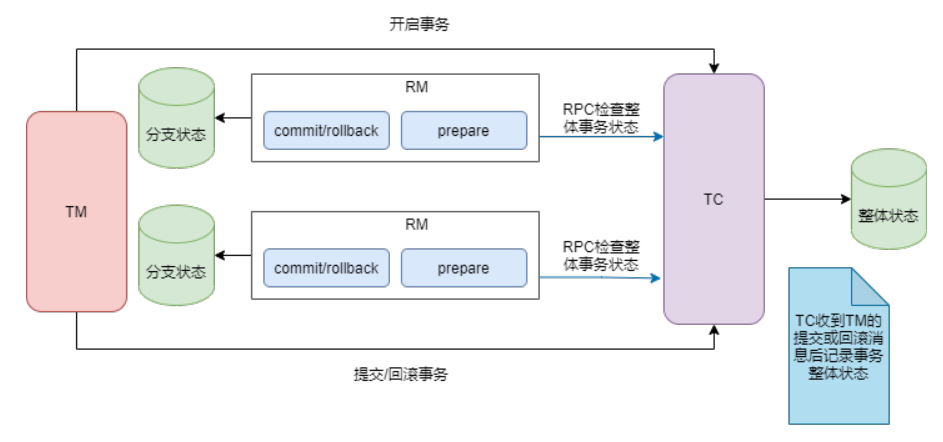
2.3.2 故障恢复
在Seata中,当TC发生故障时,数据恢复的过程如下:
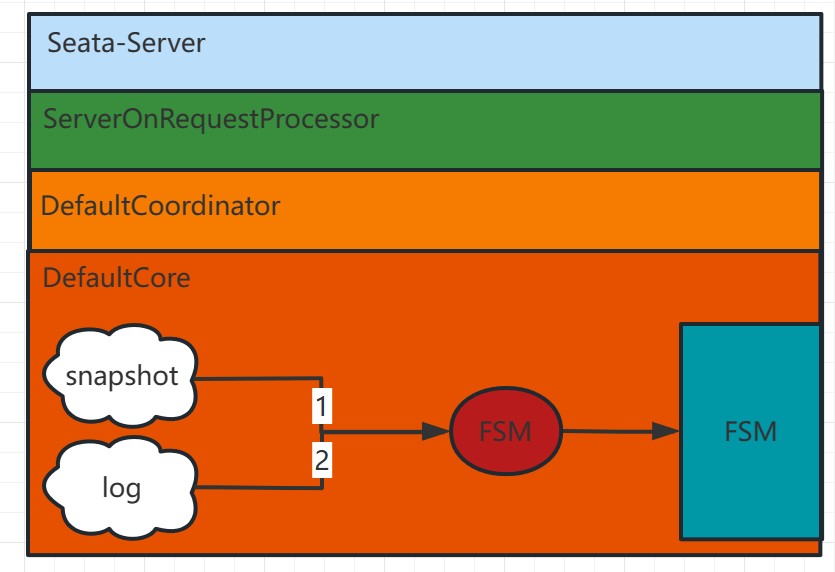
如上图所示
-
检查是否存在最新的数据快照:首先,系统会检查是否存在最新的数据快照文件。数据快照是基于内存的数据状态的一次全量拷贝,如果有最新的数据快照,则系统将直接加载该快照到内存中。
-
根据快照后的Raft日志进行回放:如果存在最新的快照或者没有快照文件,系统将根据之前记录的Raft日志进行数据回放。每个Seata-Server中的请求最终会经过ServerOnRequestProcessor进行处理,然后转移到具体的协调者类(DefaultCoordinator或RaftCoordinator)中,再转向具体的业务代码(DefaultCore)进行相应的事务处理(如begin、commit、rollback等)。
-
当日志回放完成后,便会由leader发起日志的同步,并继续执行相关事务的增删改动作。f
通过以上步骤,Seata能够实现在故障发生后的数据恢复。首先尝试加载最新的快照,如果有的话可以减少回放的时间;然后根据Raft日志进行回放,保证数据操作的一致性;最后通过日志同步机制,确保数据在多节点之间的一致性。
2.3.3 业务处理同步过程
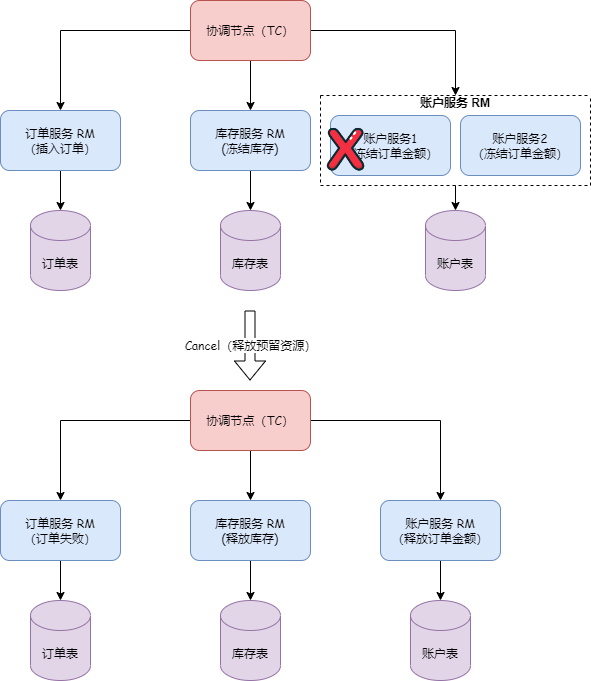
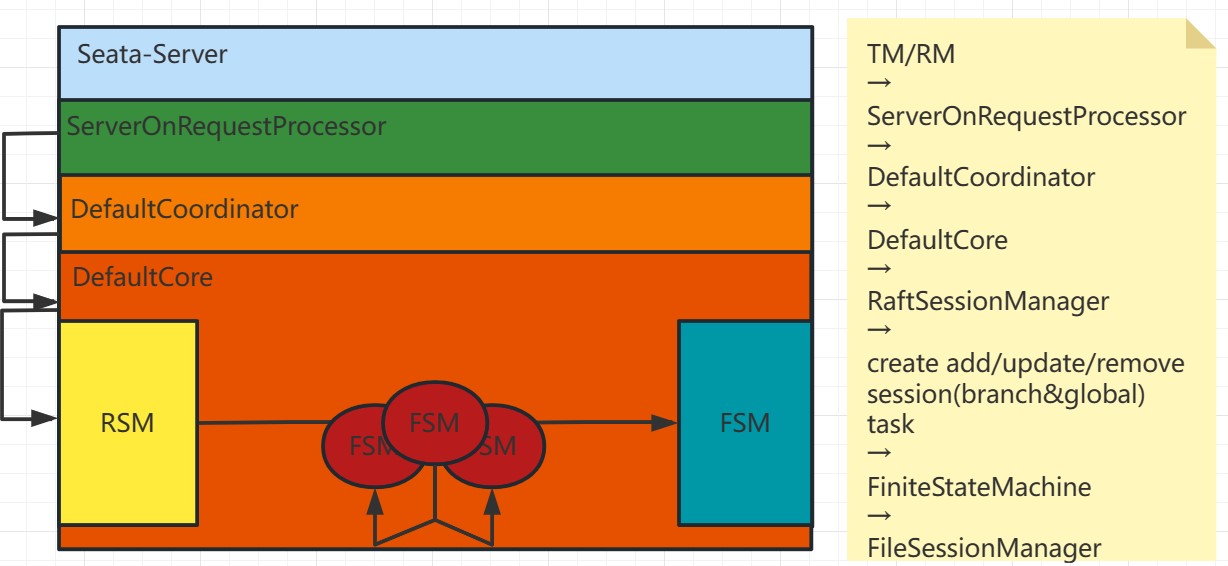 对于client侧获取最新metadata时恰好有业务线程在执行begin、commit或registry等操作的情况,Seata采取了以下处理方式:
对于client侧获取最新metadata时恰好有业务线程在执行begin、commit或registry等操作的情况,Seata采取了以下处理方式:
-
client侧:
- 如果客户端正在执行begin、commit或registry等操作,并且此时需要获取最新metadata,由于此时的leader可能已经不存在或不是当前leader,因此客户端的RPC请求可能会失败。
- 如果请求失败,客户端会收到异常响应,此时客户端需要根据请求的结果进行回滚操作。
-
TC侧对旧leader的检测:
- 在TC侧,如果此时客户端的请求到达旧的leader节点,TC会进行当前是否是leader的检测,如果不是leader,则会拒绝该请求。
- 如果是leader但在中途失败,比如在提交任务到状态机的过程中失败,由于当前已经不是leader,创建任务(createTask)的动作会失败。这样,客户端也会接收到响应异常。
- 旧leader的提交任务也会失败,确保了事务信息的一致性。 通过上述处理方式,当客户端获取最新metadata时恰好遇到业务操作的情况,Seata能够保证数据的一致性和事务的正确性。如果客户端的RPC请求失败,将触发回滚操作;而在TC侧,对旧leader的检测和任务提交的失败可以防止事务信息不一致的问题。这样,客户端的数据也能保持一致性。
3.使用部署
在使用和部署�上,社区秉持着最小侵入,最小改动的原则,所以整体的部署上手应该是非常简单的,接下来分开client与server两端的部署改动点进行介绍
3.1 client
首先,使用注册配置中心较多的同学应该知道Seata的配置项中有一个seata.registry.type的配置项,支持了nacos,zk,etcd,redis等等,而在2.0以后增加了一个raft的配置项
registry:
type: raft
raft:
server-addr: 192.168.0.111:7091, 192.168.0.112:7091, 192.168.0.113:7091
将registry.type 改为raft,并配置raft相关元数据的获取地址,该地址统一为seata-server的ip+http端口
然后必不可少的就是传统的事务分组的配置
seata:
tx-service-group: default_tx_group
service:
vgroup-mapping:
default_tx_group: default
如现在使用的事务分组为default_tx_group,那么对应的seata集群/分组就是default,这个是有对应关系的,后续再server部署环节上会介绍
至此client的改动已经完成了
3.2 server
对于server的改动可能会多一些,要熟悉一些调优参数和配置,当然也可以选择默认值不做任何修改
seata:
server:
raft:
group: default #此值代表该raft集群的group,client的事务分组对应的值要与之对应
server-addr: 192.168.0.111:9091,192.168.0.112:9091,192.168.0.113:9091 # 3台节点的ip和端口,端口为该节点的netty端口+1000,默认netty端口为8091
snapshot-interval: 600 # 600秒做一次数据的快照,以便raftlog的快速滚动,但是每次做快照如果内存中事务数据过多会导致每600秒产生一次业务rt的抖动,但是对于故障恢复比较友好,重启节点较快,可以调整为30分钟,1小时都行,具体按业务来,可以自行压测看看是否有抖动,在rt抖动和故障恢复中自行找个平衡点
apply-batch: 32 # 最多批量32次动作做一次提交raftlog
max-append-bufferSize: 262144 #日志存储缓冲区最��大大小,默认256K
max-replicator-inflight-msgs: 256 #在启用 pipeline 请求情况下,最大 in-flight 请求数,默认256
disruptor-buffer-size: 16384 #内部 disruptor buffer 大小,如果是写入吞吐量较高场景,需要适当调高该值,默认 16384
election-timeout-ms: 1000 #超过多久没有leader的心跳开始重选举
reporter-enabled: false # raft自身的监控是否开启
reporter-initial-delay: 60 # 监控的区间间隔
serialization: jackson # 序列化方式,不要改动
compressor: none # raftlog的压缩方式,如gzip,zstd等
sync: true # raft日志的刷盘方式,默认是同步刷盘
config:
# support: nacos, consul, apollo, zk, etcd3
type: file # 该配置可以选择不同的配置中心
registry:
# support: nacos, eureka, redis, zk, consul, etcd3, sofa
type: file # raft模式下不允许使用非file的其他注册中心
store:
# support: file 、 db 、 redis 、 raft
mode: raft # 使用raft存储模式
file:
dir: sessionStore # 该路径为raftlog及事务相关日志的存储位置,默认是相对路径,最好设置一个固定的位置
在3个或者大于3个节点的seata-server中配置完以上参数后,直接启动便可以看到类似以下的日志输出,就代表集群已经正常启动了
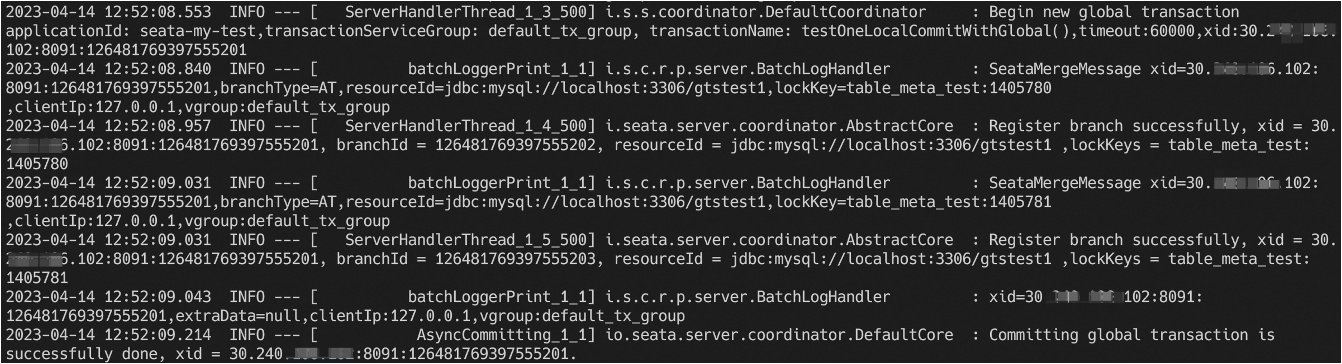
2023-10-13 17:20:06.392 WARN --- [Rpc-netty-server-worker-10-thread-1] [com.alipay.sofa.jraft.rpc.impl.BoltRaftRpcFactory] [ensurePipeline] []: JRaft SET bolt.rpc.dispatch-msg-list-in-default-executor to be false for replicator pipeline optimistic.
2023-10-13 17:20:06.439 INFO --- [default/PeerPair[10.58.16.231:9091 -> 10.58.12.217:9091]-AppendEntriesThread0] [com.alipay.sofa.jraft.storage.impl.LocalRaftMetaStorage] [save] []: Save raft meta, path=sessionStore/raft/9091/default/raft_meta, term=4, votedFor=0.0.0.0:0, cost time=25 ms
2023-10-13 17:20:06.441 WARN --- [default/PeerPair[10.58.16.231:9091 -> 10.58.12.217:9091]-AppendEntriesThread0] [com.alipay.sofa.jraft.core.NodeImpl] [handleAppendEntriesRequest] []: Node <default/10.58.16.231:9091> reject term_unmatched AppendEntriesRequest from 10.58.12.217:9091, term=4, prevLogIndex=4, prevLogTerm=4, localPrevLogTerm=0, lastLogIndex=0, entriesSize=0.
2023-10-13 17:20:06.442 INFO --- [JRaft-FSMCaller-Disruptor-0] [io.seata.server.cluster.raft.RaftStateMachine] [onStartFollowing] []: groupId: default, onStartFollowing: LeaderChangeContext [leaderId=10.58.12.217:9091, term=4, status=Status[ENEWLEADER<10011>: Raft node receives message from new leader with higher term.]].
2023-10-13 17:20:06.449 WARN --- [default/PeerPair[10.58.16.231:9091 -> 10.58.12.217:9091]-AppendEntriesThread0] [com.alipay.sofa.jraft.core.NodeImpl] [handleAppendEntriesRequest] []: Node <default/10.58.16.231:9091> reject term_unmatched AppendEntriesRequest from 10.58.12.217:9091, term=4, prevLogIndex=4, prevLogTerm=4, localPrevLogTerm=0, lastLogIndex=0, entriesSize=0.
2023-10-13 17:20:06.459 INFO --- [Bolt-default-executor-4-thread-1] [com.alipay.sofa.jraft.core.NodeImpl] [handleInstallSnapshot] []: Node <default/10.58.16.231:9091> received InstallSnapshotRequest from 10.58.12.217:9091, lastIncludedLogIndex=4, lastIncludedLogTerm=4, lastLogId=LogId [index=0, term=0].
2023-10-13 17:20:06.489 INFO --- [Bolt-conn-event-executor-13-thread-1] [com.alipay.sofa.jraft.rpc.impl.core.ClientServiceConnectionEventProcessor] [onEvent] []: Peer 10.58.12.217:9091 is connected
2023-10-13 17:20:06.519 INFO --- [JRaft-Group-Default-Executor-0] [com.alipay.sofa.jraft.util.Recyclers] [<clinit>] []: -Djraft.recyclers.maxCapacityPerThread: 4096.
2023-10-13 17:20:06.574 INFO --- [JRaft-Group-Default-Executor-0] [com.alipay.sofa.jraft.storage.snapshot.local.LocalSnapshotStorage] [destroySnapshot] []: Deleting snapshot sessionStore/raft/9091/default/snapshot/snapshot_4.
2023-10-13 17:20:06.574 INFO --- [JRaft-Group-Default-Executor-0] [com.alipay.sofa.jraft.storage.snapshot.local.LocalSnapshotStorage] [close] []: Renaming sessionStore/raft/9091/default/snapshot/temp to sessionStore/raft/9091/default/snapshot/snapshot_4.
2023-10-13 17:20:06.689 INFO --- [JRaft-FSMCaller-Disruptor-0] [io.seata.server.cluster.raft.snapshot.session.SessionSnapshotFile] [load] []: on snapshot load start index: 4
2023-10-13 17:20:06.694 INFO --- [JRaft-FSMCaller-Disruptor-0] [io.seata.server.cluster.raft.snapshot.session.SessionSnapshotFile] [load] []: on snapshot load end index: 4
2023-10-13 17:20:06.694 INFO --- [JRaft-FSMCaller-Disruptor-0] [io.seata.server.cluster.raft.RaftStateMachine] [onSnapshotLoad] []: groupId: default, onSnapshotLoad cost: 110 ms.
2023-10-13 17:20:06.694 INFO --- [JRaft-FSMCaller-Disruptor-0] [io.seata.server.cluster.raft.RaftStateMachine] [onConfigurationCommitted] []: groupId: default, onConfigurationCommitted: 10.58.12.165:9091,10.58.12.217:9091,10.58.16.231:9091.
2023-10-13 17:20:06.705 INFO --- [JRaft-FSMCaller-Disruptor-0] [com.alipay.sofa.jraft.storage.snapshot.SnapshotExecutorImpl] [onSnapshotLoadDone] []: Node <default/10.58.16.231:9091> onSnapshotLoadDone, last_included_index: 4
last_included_term: 4
peers: "10.58.12.165:9091"
peers: "10.58.12.217:9091"
peers: "10.58.16.231:9091"
2023-10-13 17:20:06.722 INFO --- [JRaft-Group-Default-Executor-1] [com.alipay.sofa.jraft.storage.impl.RocksDBLogStorage] [lambda$truncatePrefixInBackground$2] []: Truncated prefix logs in data path: sessionStore/raft/9091/default/log from log index 1 to 5, cost 0 ms.
3.3 faq
- 当
seata.raft.server-addr配置好后,必须通过server的openapi进行集群的扩缩容,直接改动该配置进行重启是不会生效的 接口为/metadata/v1/changeCluster?raftClusterStr=新的集群列表 - 如果
server-addr:中的地址都为本机,那么需要根据本机上不同的server的netty端口增加1000的偏移量,如server.port: 7092那么netty端口为8092,raft选举和通信端口便为9092,需要增加启动参数-Dserver.raftPort=9092. Linux下可以通过export JAVA_OPT="-Dserver.raftPort=9092"等方式指定。
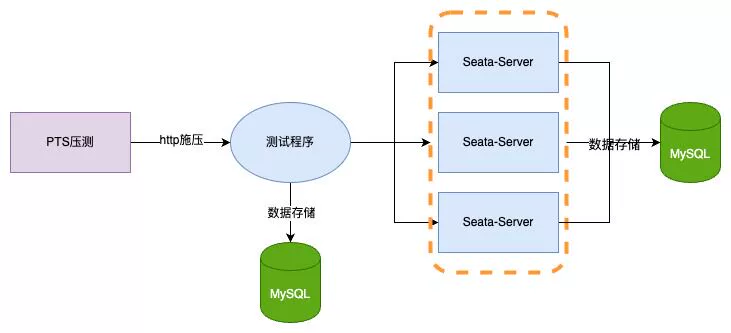
4.压测对比
压测对比分为两种场景,并且为了避免数据热点冲突与线程调优等情况,将Client侧的数据初始化300W条商品,并直接使用jdk21虚拟线程+spring boot3+seata AT来测试,在gc方面全部采用分代ZGC进行,压测工具为阿里云PTS,Server侧统一使用jdk21(目前还未适配虚拟线程) 服务器配置如下 TC: 4c8g3 Client: 4c8G*1 数据库为阿里云rds 4c16g
- 64并发压测只增加
@Globaltransactional注解接口空提交的性能 - 随机300W数据进行32并发10分钟的扣库存
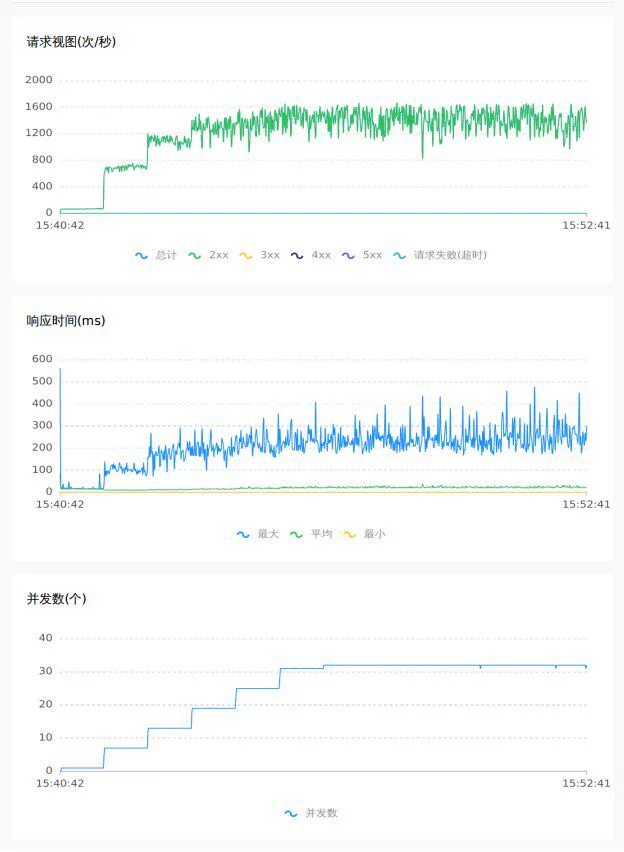
4.1 1.7.1 db模式
空提交 64C
随机扣库存 32C
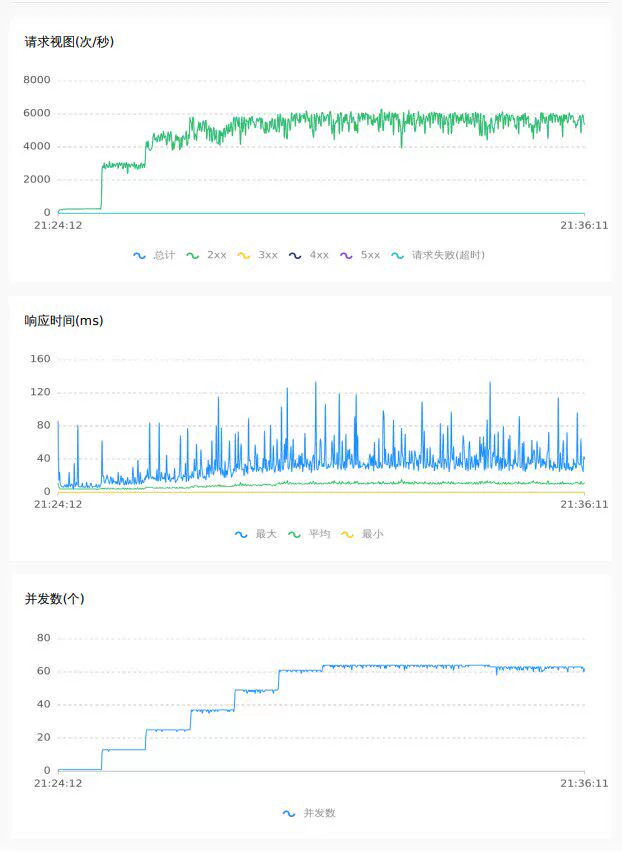
4.2 2.0 raft模式
空提交 64C
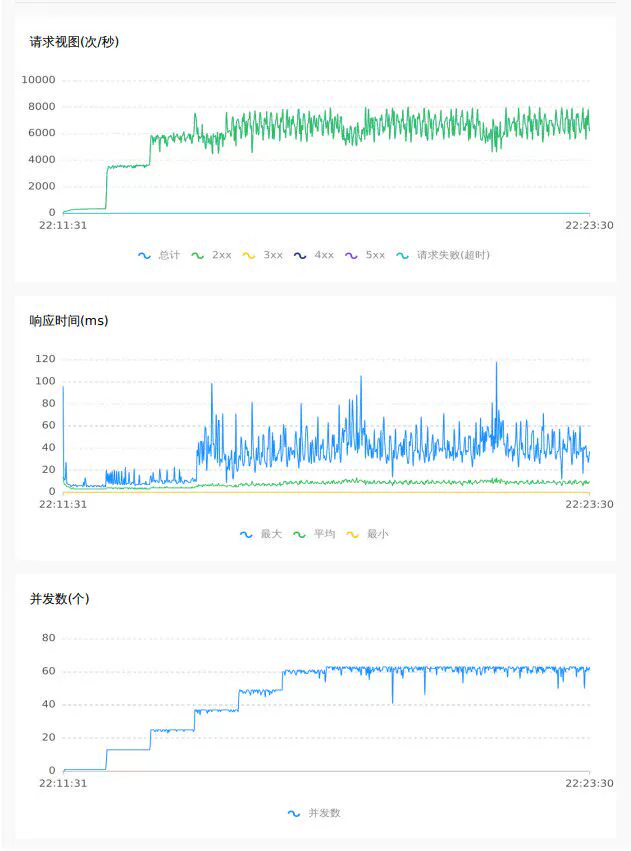
随机扣库存 32C
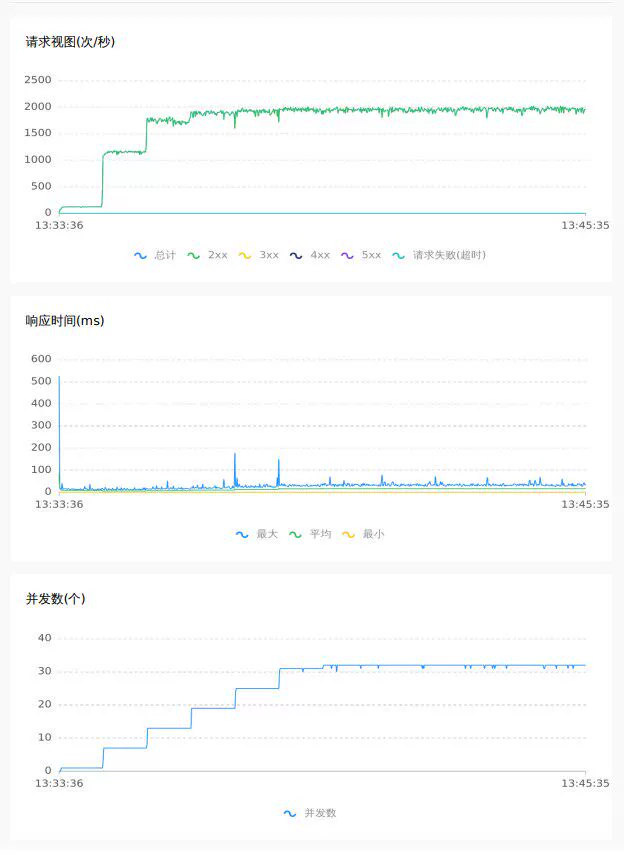
4.3 压测结果对比
32并发对300W商品随机扣库存场景
| tps avg | tps max | count | rt | error | 存储类型 |
|---|---|---|---|---|---|
| 1709(42%↑) | 2019(21%↑) | 1228803(42%↑) | 13.86ms(30%↓) | 0 | Raft |
| 1201 | 1668 | 864105 | 19.86ms | 0 | DB |
64并发空压@Globaltransactional接口(压测峰值上限为8000)
| tps avg | tps max | count | rt | error | 存储类型 |
|---|---|---|---|---|---|
| 5704(20%↑) | 8062(30%↑) | 4101236(20%↑) | 7.79ms(19%↓) | 0 | Raft |
| 4743 | 6172 | 3410240 | 9.65ms | 0 | DB |
除了以上数据上的直观对比,通过对压测的曲线图来观察,raft模式下tps与rt更加平稳,抖动更少,性能与吞吐量上更佳.
5.总结
在Seata未来的发展中,性能、入门门槛、部署运维成本,都是我们需要关注和不断优化的方向,在raft模式推出后有以下几个特点:
- 如存储方面,存算分离后Seata对其优化的上限被拔高,自主可控
- 部署成本更低,无需额外的注册中心,存储中间件
- 入门的门槛更低,无需学习其他的一些如注册中心的知识,一站式直接使用Seata Raft 即可上手
针对业界发展趋势,一些开源项目如ClickHouse和Kafka已经开始放弃使用ZooKeeper,并转而采用自研的解决方案,比如ClickKeeper和KRaft。这些方案将元数据等信息交由自身保证存储,以减少对第三方依赖的需求,从而降低运维成本和学习成本。这些特性是非常成熟和可借鉴的。
当然,目前来看,基于Raft模式的解决方案可能还不够成熟,可能无法完全达到上述描述的那样美好。然而,正是因为存在这样的理论基础,社区更应该朝着这个方向努力,让实践逐步接近理论的要求。在这里,欢迎所有对Seata感兴趣的同学加入社区,共同为Seata添砖加瓦!
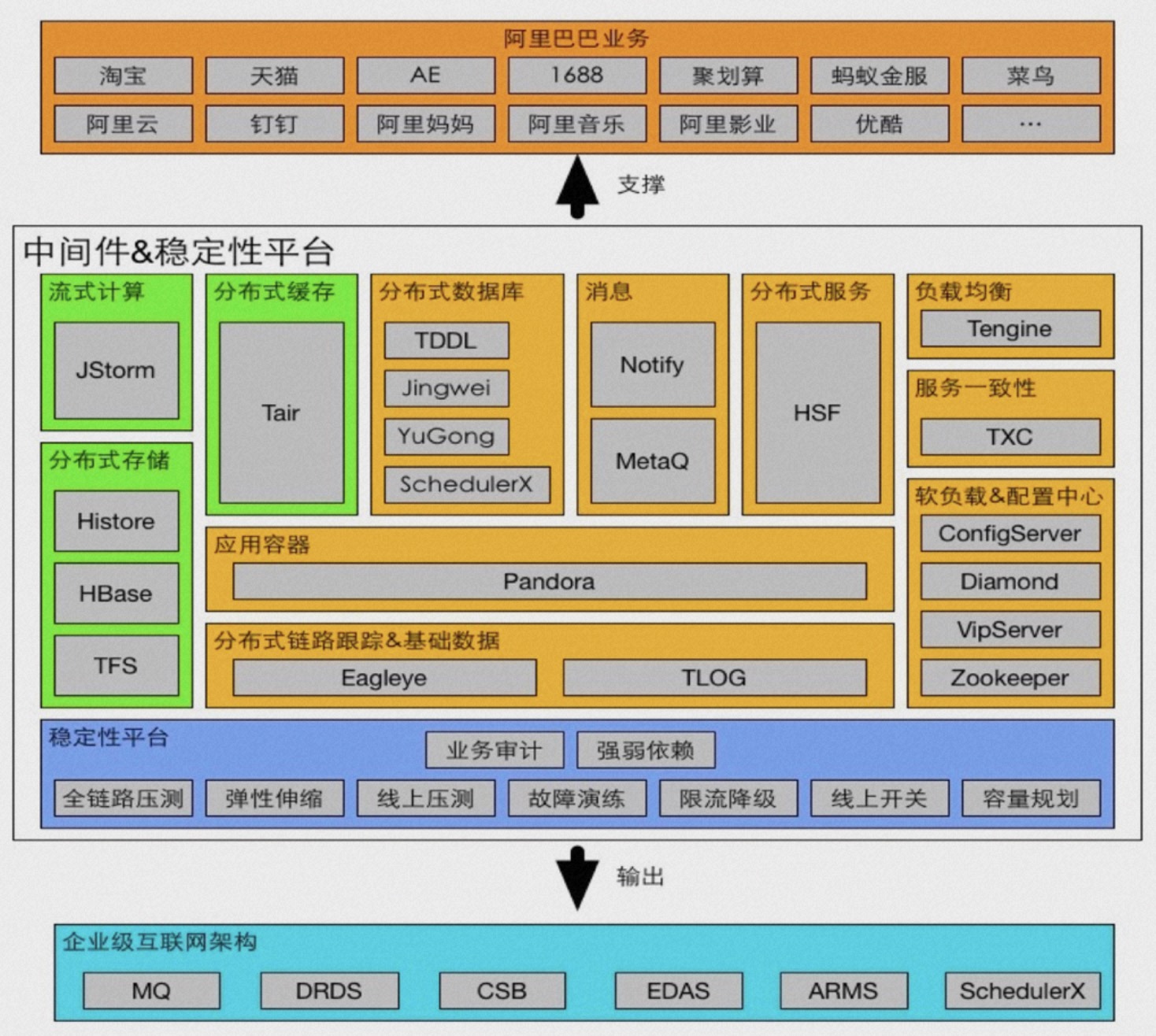 Seata 在阿里内部的产品代号叫TXC(taobao transaction constructor),这个名字有非常浓厚的组织架构色彩。TXC 起源于阿里五彩石项目,五彩石是上古神话中女娲补天所用的石子,项目名喻意为打破关键技术壁垒,象征着阿里在从单体架构向分布式架构的演进过程中的重要里程碑。在这个项目的过程中演进出一批划时代的互联网中间件,包括我们常说的三大件:
Seata 在阿里内部的产品代号叫TXC(taobao transaction constructor),这个名字有非常浓厚的组织架构色彩。TXC 起源于阿里五彩石项目,五彩石是上古神话中女娲补天所用的石子,项目名喻意为打破关键技术壁垒,象征着阿里在从单体架构向分布式架构的演进过程中的重要里程碑。在这个项目的过程中演进出一批划时代的互联网中间件,包括我们常说的三大件: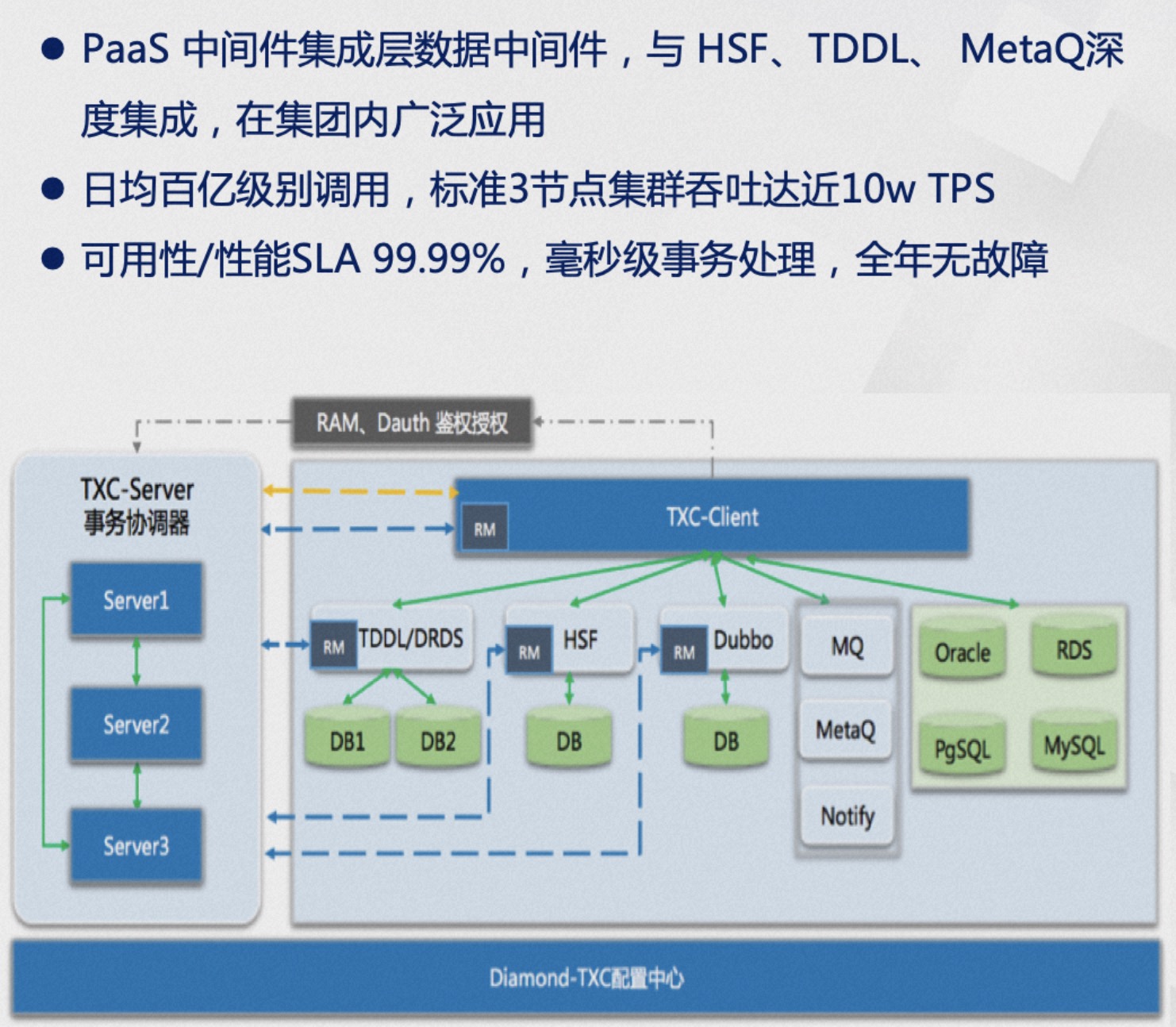
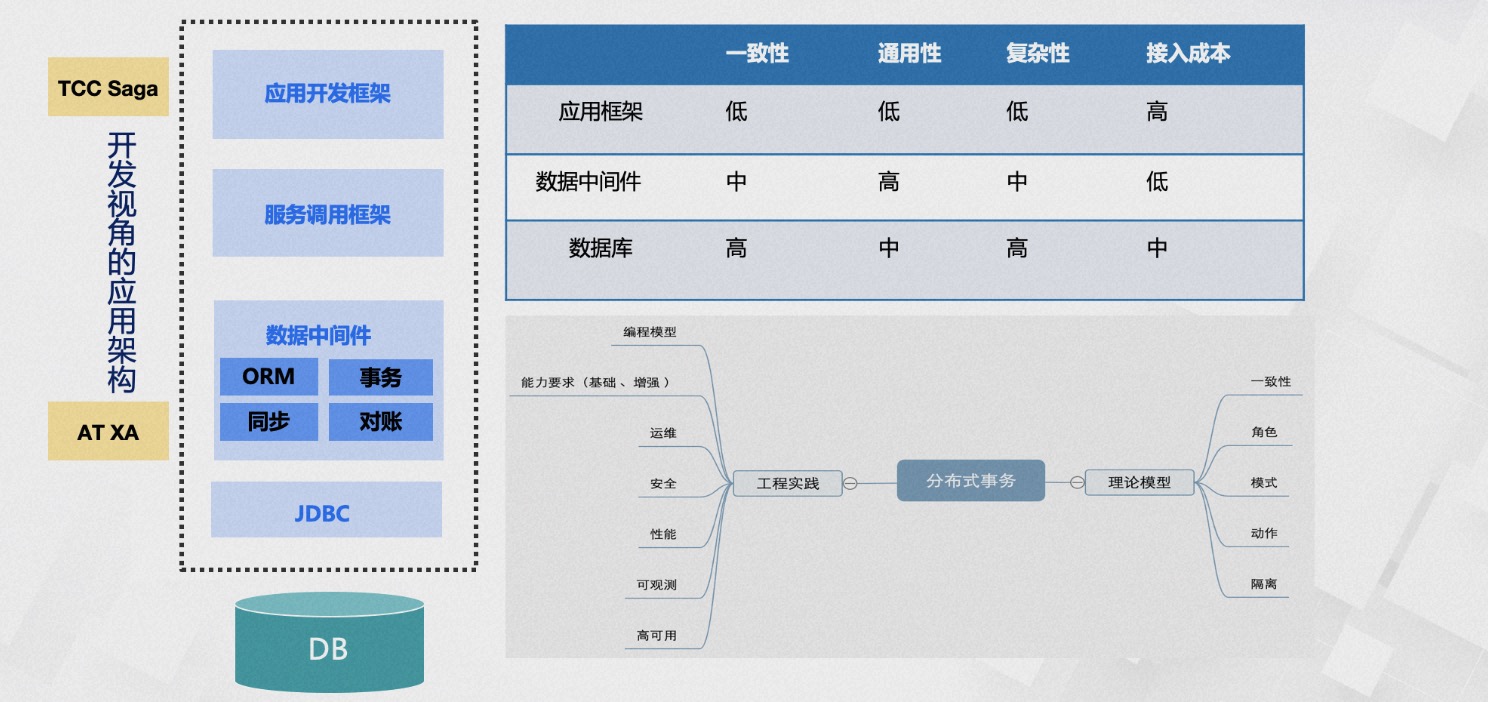
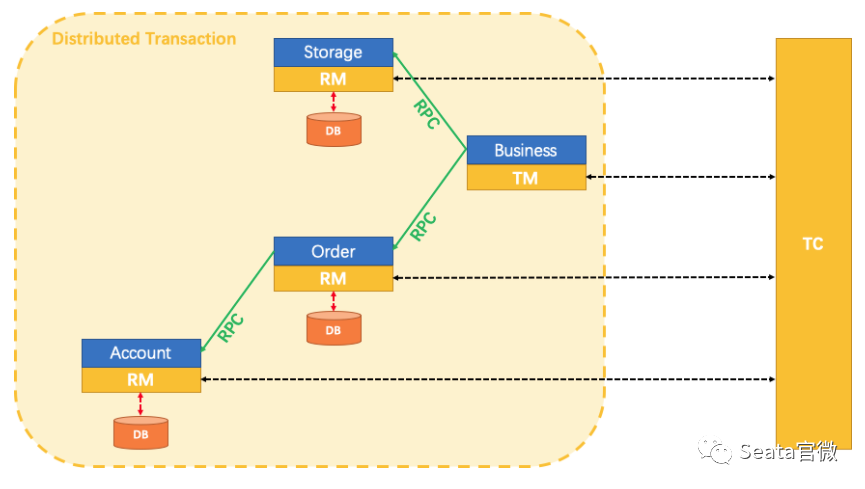
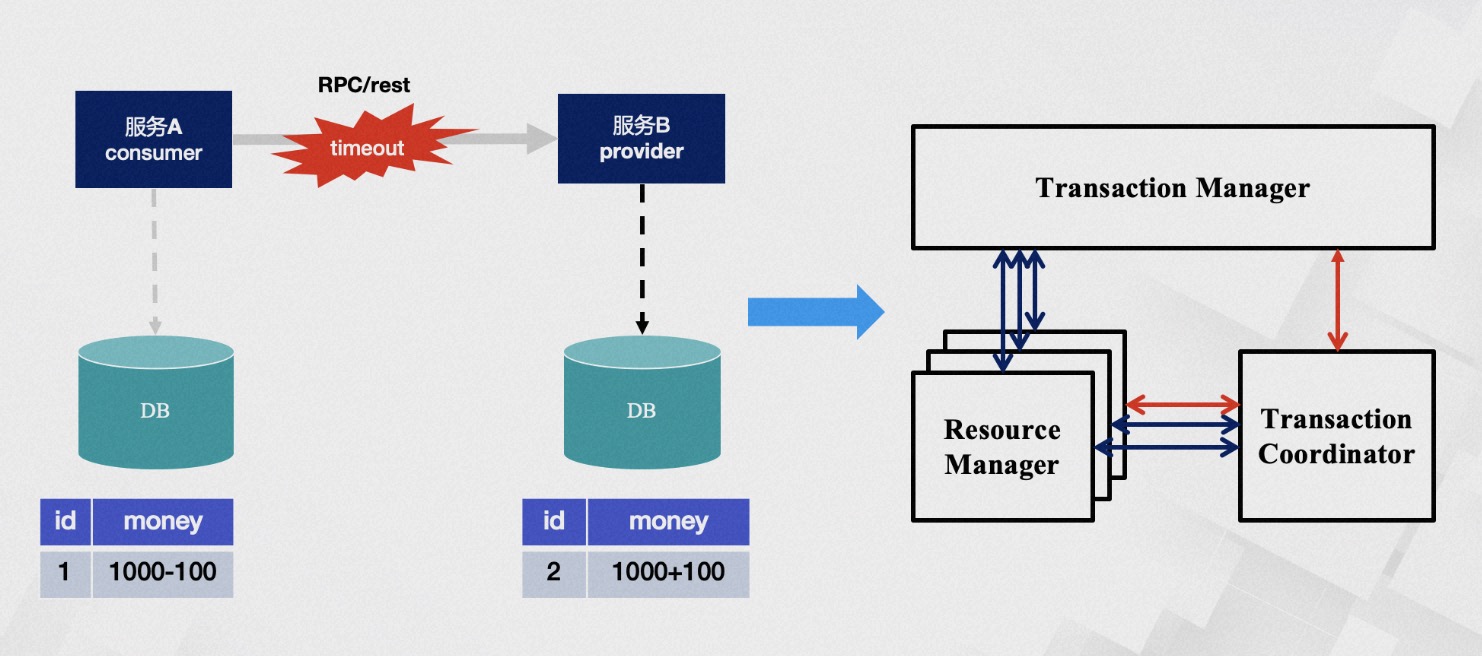 分布式事务解决了哪些问题呢?一个经典且具有体感的例子就是转账场景。转账过程包括减去余额和增加余额两个步骤,我们如何保证操作的原子性?在没有任何干预的情况下,这两个步骤可能会遇到各种问题,例如B账户已销户或��出现服务调用超时等情况。
分布式事务解决了哪些问题呢?一个经典且具有体感的例子就是转账场景。转账过程包括减去余额和增加余额两个步骤,我们如何保证操作的原子性?在没有任何干预的情况下,这两个步骤可能会遇到各种问题,例如B账户已销户或��出现服务调用超时等情况。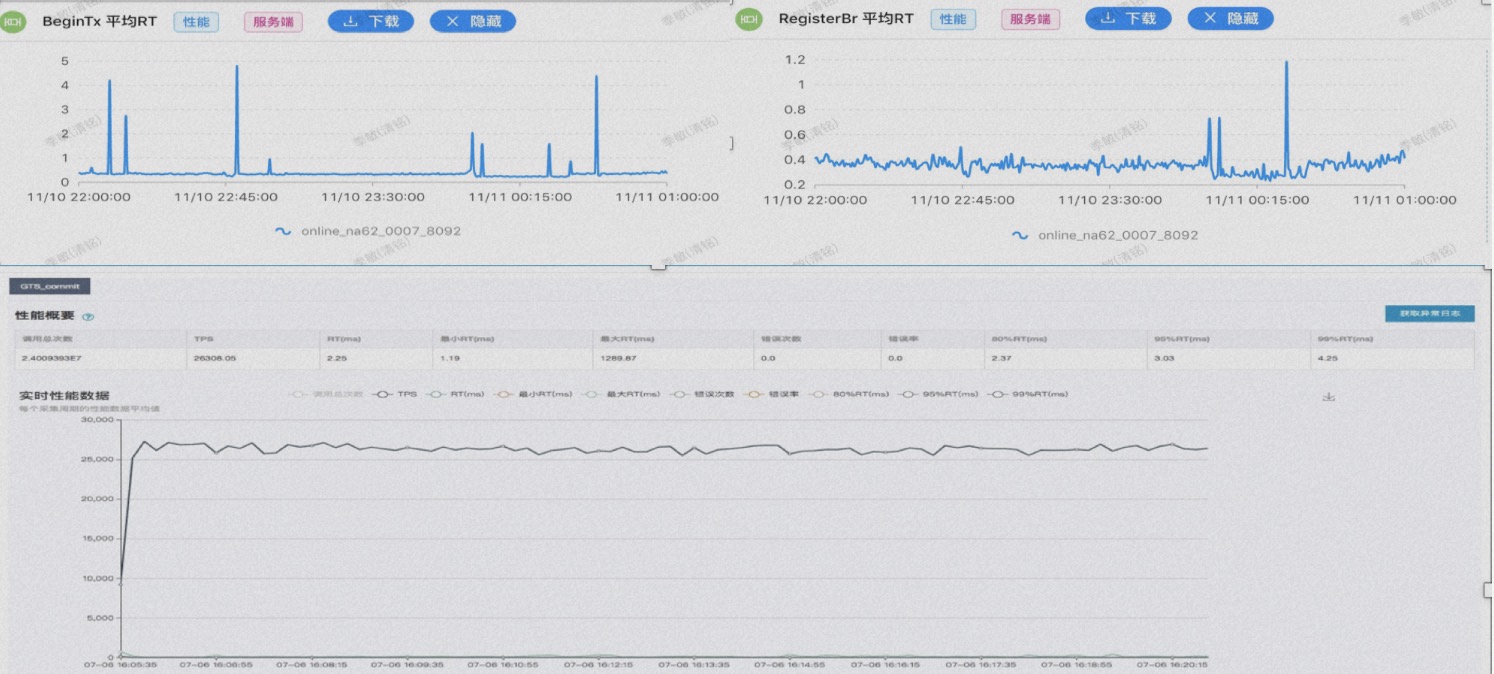 经过多年的架构演进,从事务的单链路耗时角度来看,TXC在事务开始时的处理平均时间约为0.2毫秒,分支注册的平均时间约为0.4毫秒,整个事务额外的耗时在毫秒级别之内。这也是我们推算出的极限理论值。在吞吐量方面,单节点的TPS达到3万次/秒,标准集群的TPS接近10万次/秒。
经过多年的架构演进,从事务的单链路耗时角度来看,TXC在事务开始时的处理平均时间约为0.2毫秒,分支注册的平均时间约为0.4毫秒,整个事务额外的耗时在毫秒级别之内。这也是我们推算出的极限理论值。在吞吐量方面,单节点的TPS达到3万次/秒,标准集群的TPS接近10万次/秒。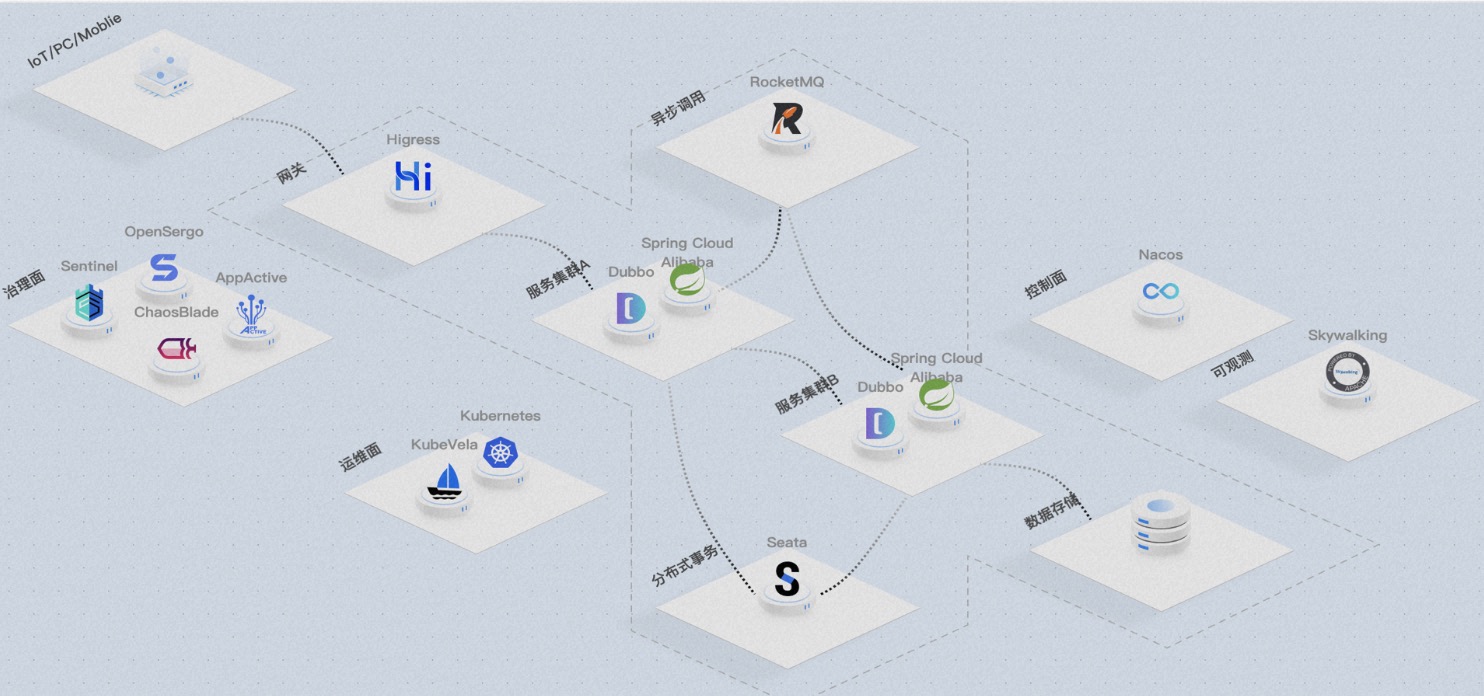 阿里的开源经历了三个主要阶段。第一个阶段是Dubbo所处的阶段,开发者用爱发电, Dubbo开源了有10几年的时间,时间充分证明了Dubbo是非常优秀的开源软件,它的微内核插件化的扩展性设计也是我最初开源Seata 的重要参考。做软件设计的时候我们要思考扩展性和性能权衡起来哪个会更重要一些,我们到底是要做一个三年的设计,五年的设计亦或是满足业务发展的十年设计。我们在做0-1服务调用问题的解决方案的同时,能否预�测到1-100规模化后的治理问题。
阿里的开源经历了三个主要阶段。第一个阶段是Dubbo所处的阶段,开发者用爱发电, Dubbo开源了有10几年的时间,时间充分证明了Dubbo是非常优秀的开源软件,它的微内核插件化的扩展性设计也是我最初开源Seata 的重要参考。做软件设计的时候我们要思考扩展性和性能权衡起来哪个会更重要一些,我们到底是要做一个三年的设计,五年的设计亦或是满足业务发展的十年设计。我们在做0-1服务调用问题的解决方案的同时,能否预�测到1-100规模化后的治理问题。 目前,Seata已经开源了4种事务模式,包括AT、TCC、Saga和XA,并在积极探索其他可行的事务解决方案。 Seata已经与10多个主流的RPC框架和关系数据库进行了集成,同时与20 多个社区存在集成和被集成的关系。此外,我们还在多语言体系上探索除Java之外的语言,如Golang、PHP、Python和JS。
目前,Seata已经开源了4种事务模式,包括AT、TCC、Saga和XA,并在积极探索其他可行的事务解决方案。 Seata已经与10多个主流的RPC框架和关系数据库进行了集成,同时与20 多个社区存在集成和被集成的关系。此外,我们还在多语言体系上探索除Java之外的语言,如Golang、PHP、Python和JS。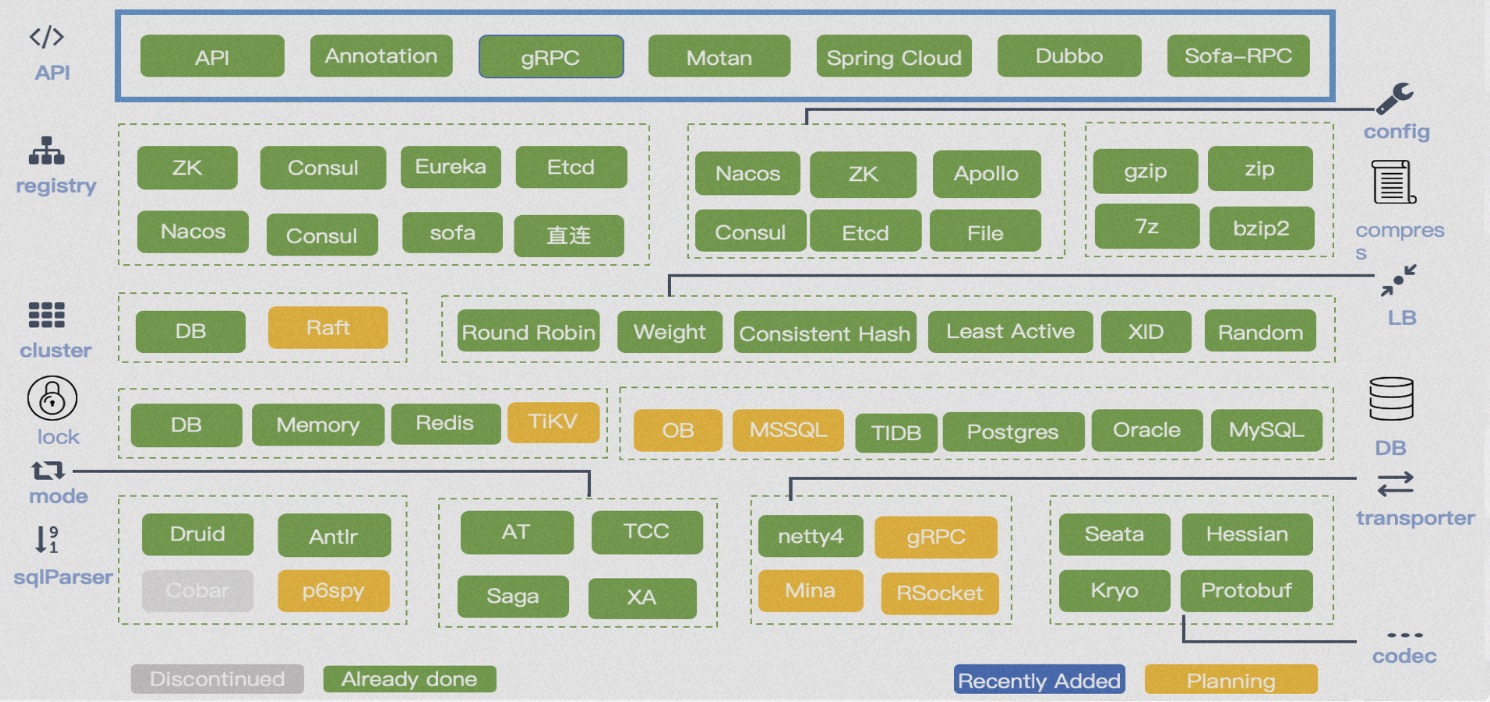 Seata采用了微内核和插件化的设计,它在API、注册配置中心、存储模式、锁控制、SQL解析器、负载均衡、传输、协议编解码、可观察性等方面暴露了丰富的扩展点。 这使得业务可以方便地进行灵活的扩展和技术组件的选择。
Seata采用了微内核和插件化的设计,它在API、注册配置中心、存储模式、锁控制、SQL解析器、负载均衡、传输、协议编解码、可观察性等方面暴露了丰富的扩展点。 这使得业务可以方便地进行灵活的扩展和技术组件的选择。 案例1:中航信航旅纵横项目
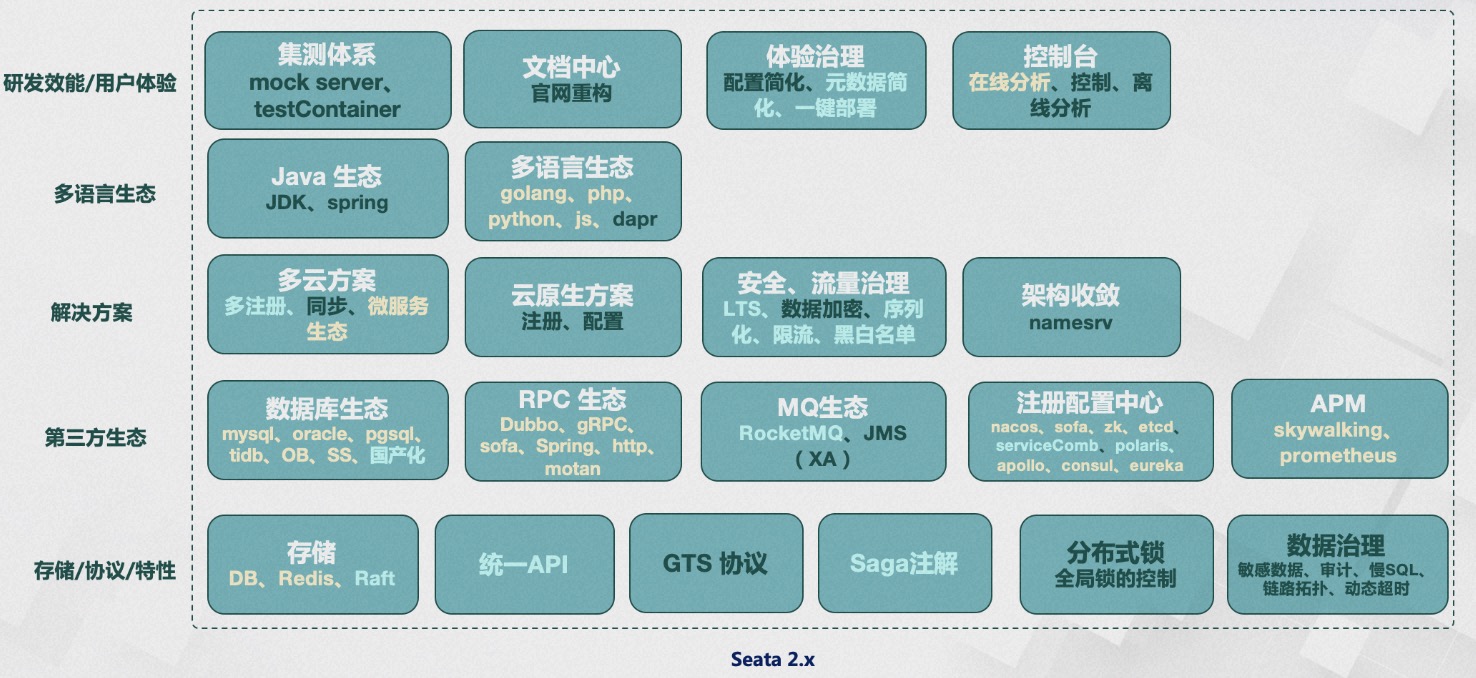
案例1:中航信航旅纵横项目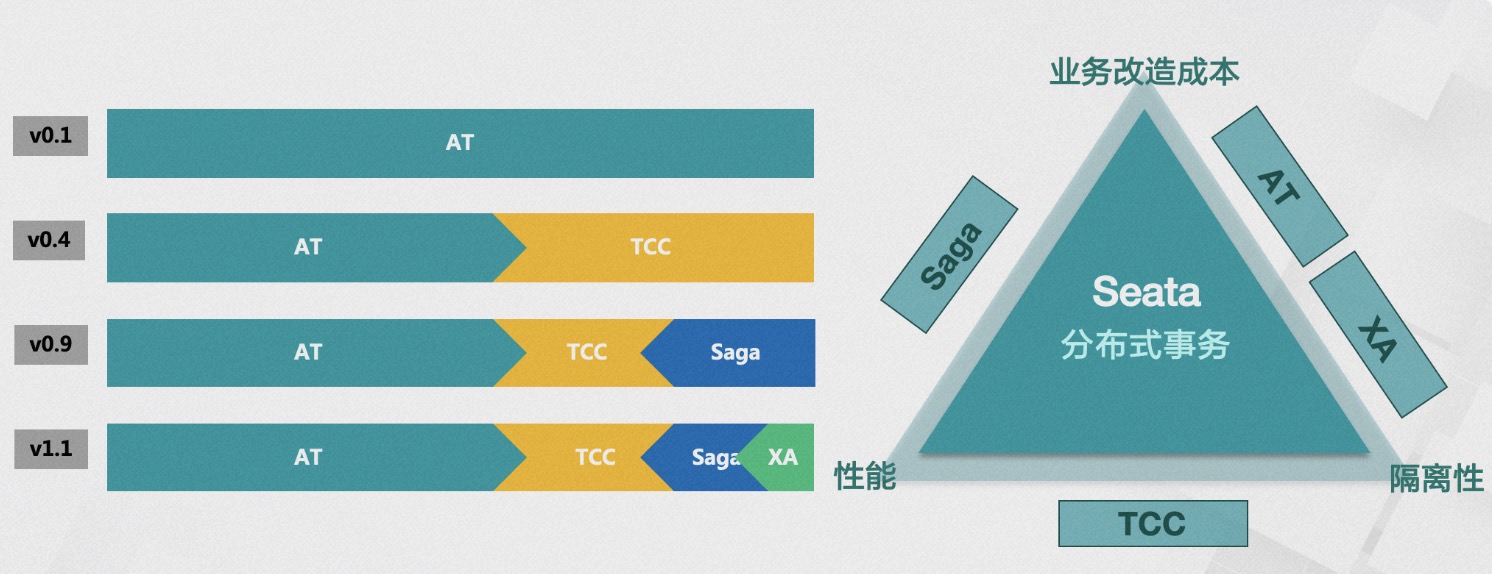

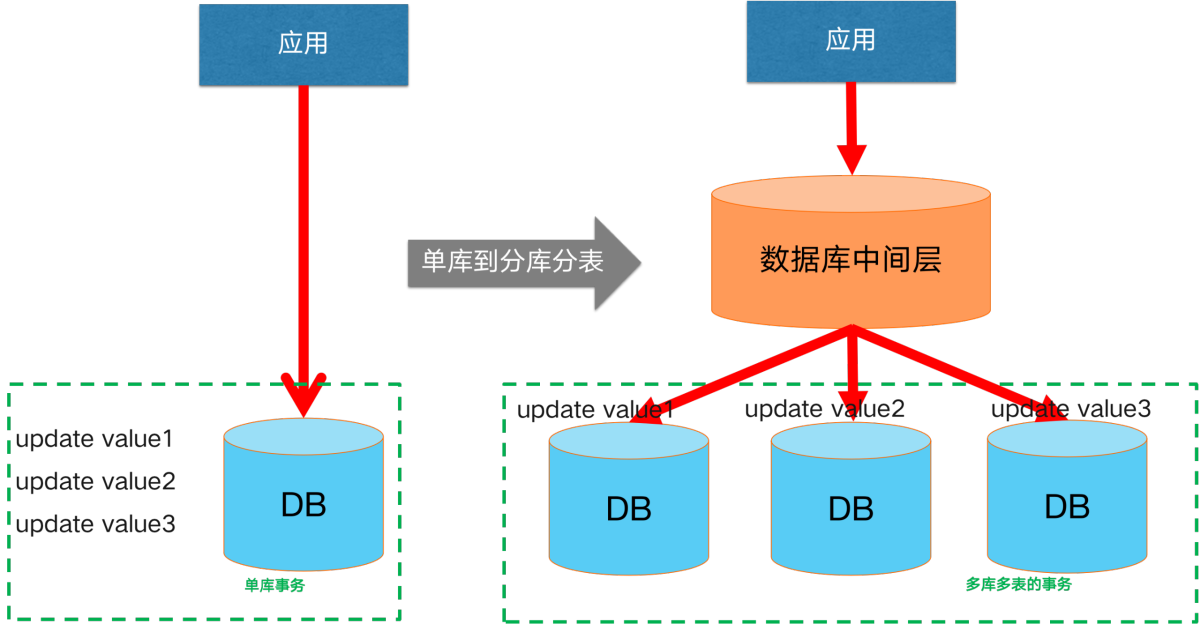 起初我们的业务规模小、轻量化,单一数据库就能保障我们的数据链路。但随着业务规模不断扩大、业务不断复杂化,通常单一数据库在容量、性能上会遭遇瓶颈。通常的解决方案是向分库、分表的架构演进。此时,即引入了分库分表场景下的分布式事务场景。
起初我们的业务规模小、轻量化,单一数据库就能保障我们的数据链路。但随着业务规模不断扩大、业务不断复杂化,通常单一数据库在容量、性能上会遭遇瓶颈。通常的解决方案是向分库、分表的架构演进。此时,即引入了分库分表场景下的分布式事务场景。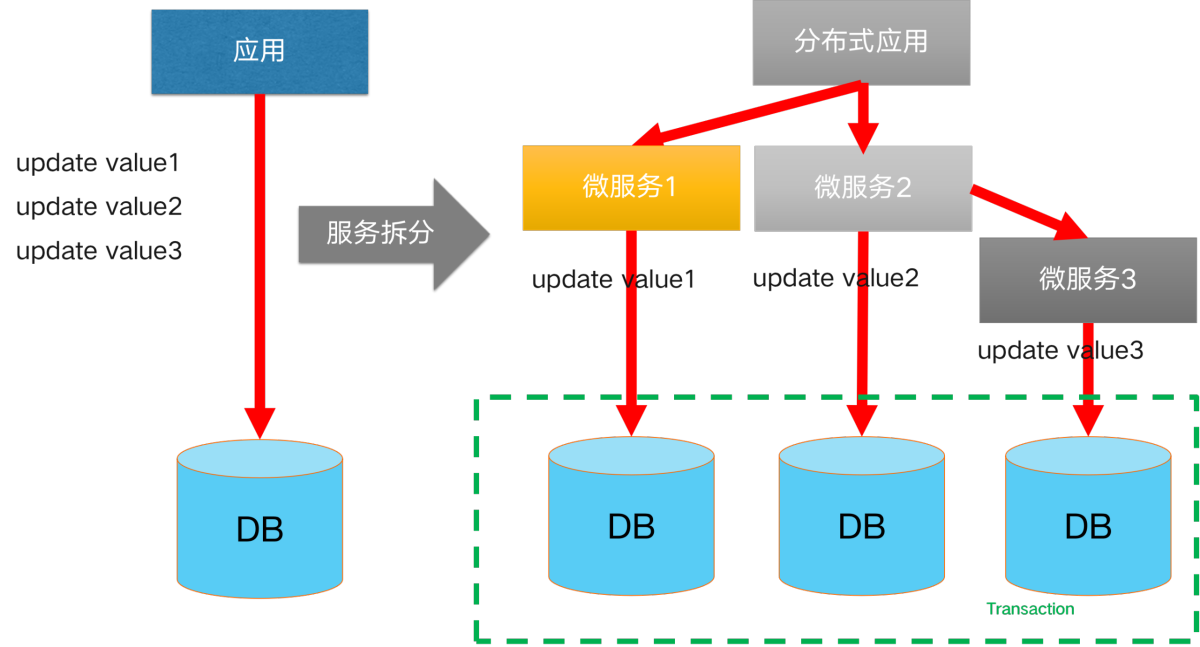 降低单体应用复杂度的方案:应用微服务化拆分。拆分后,我们的产品由多个功能各异的微服务组件构成,每个微服务都使用独立的数据库资源。在涉及到跨服务调用的数据一致性场景时,就引入了跨服务场景下的分布式事务。
降低单体应用复杂度的方案:应用微服务化拆分。拆分后,我们的产品由多个功能各异的微服务组件构成,每个微服务都使用独立的数据库资源。在涉及到跨服务调用的数据一致性场景时,就引入了跨服务场景下的分布式事务。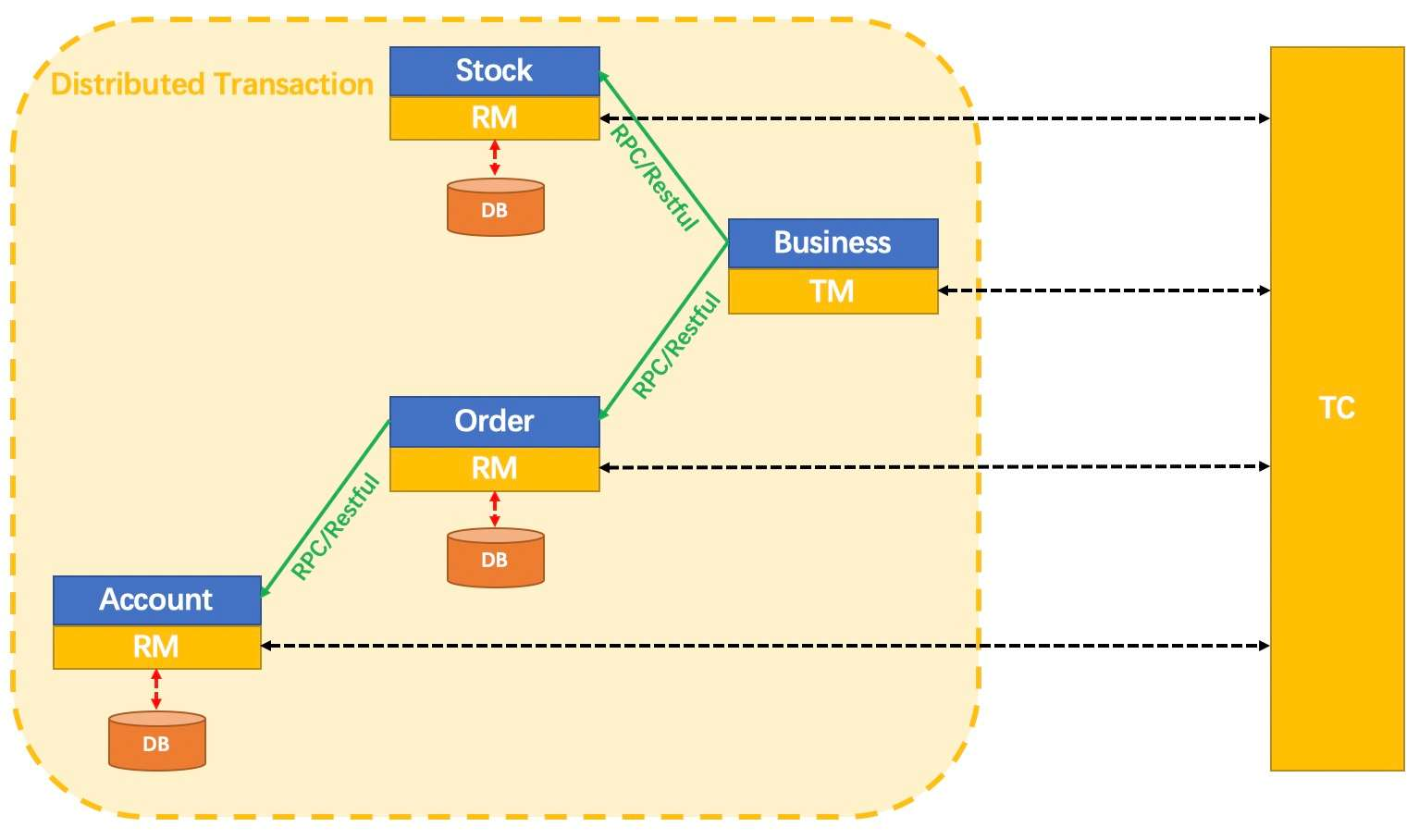 其核心组件主要如下:
其核心组件主要如下: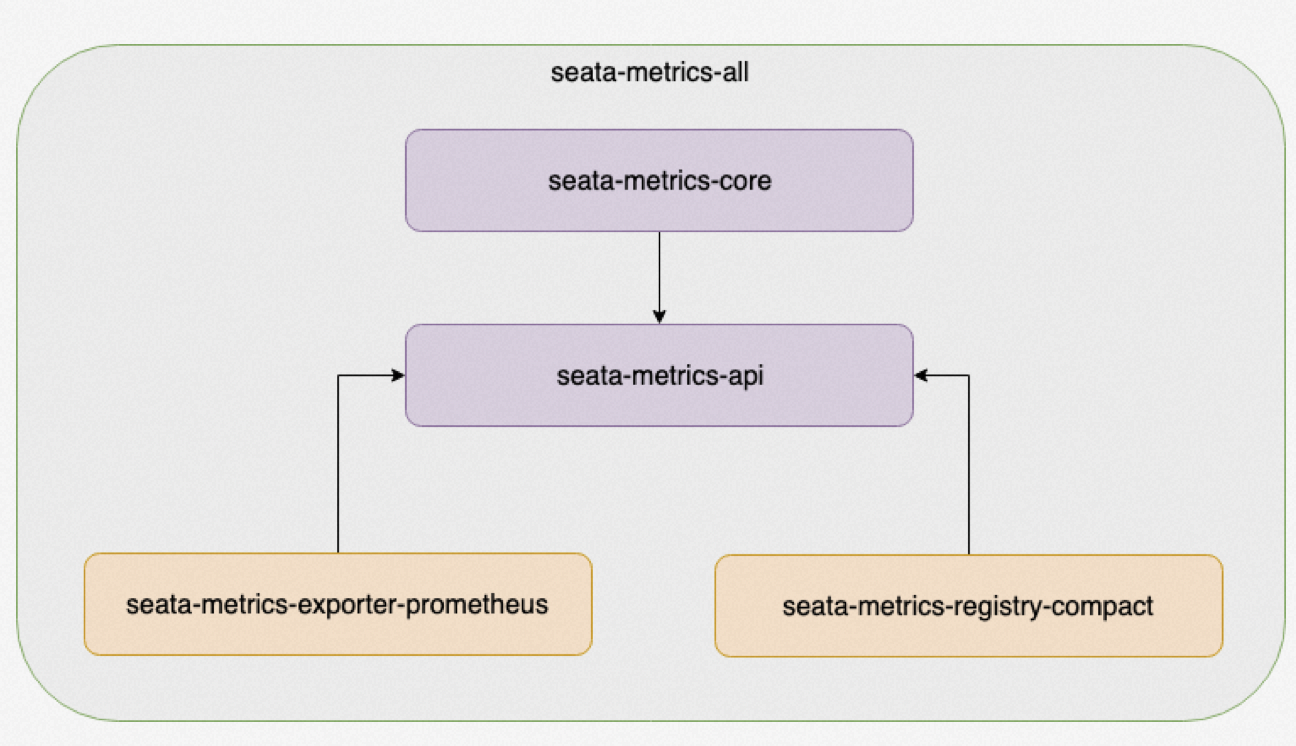
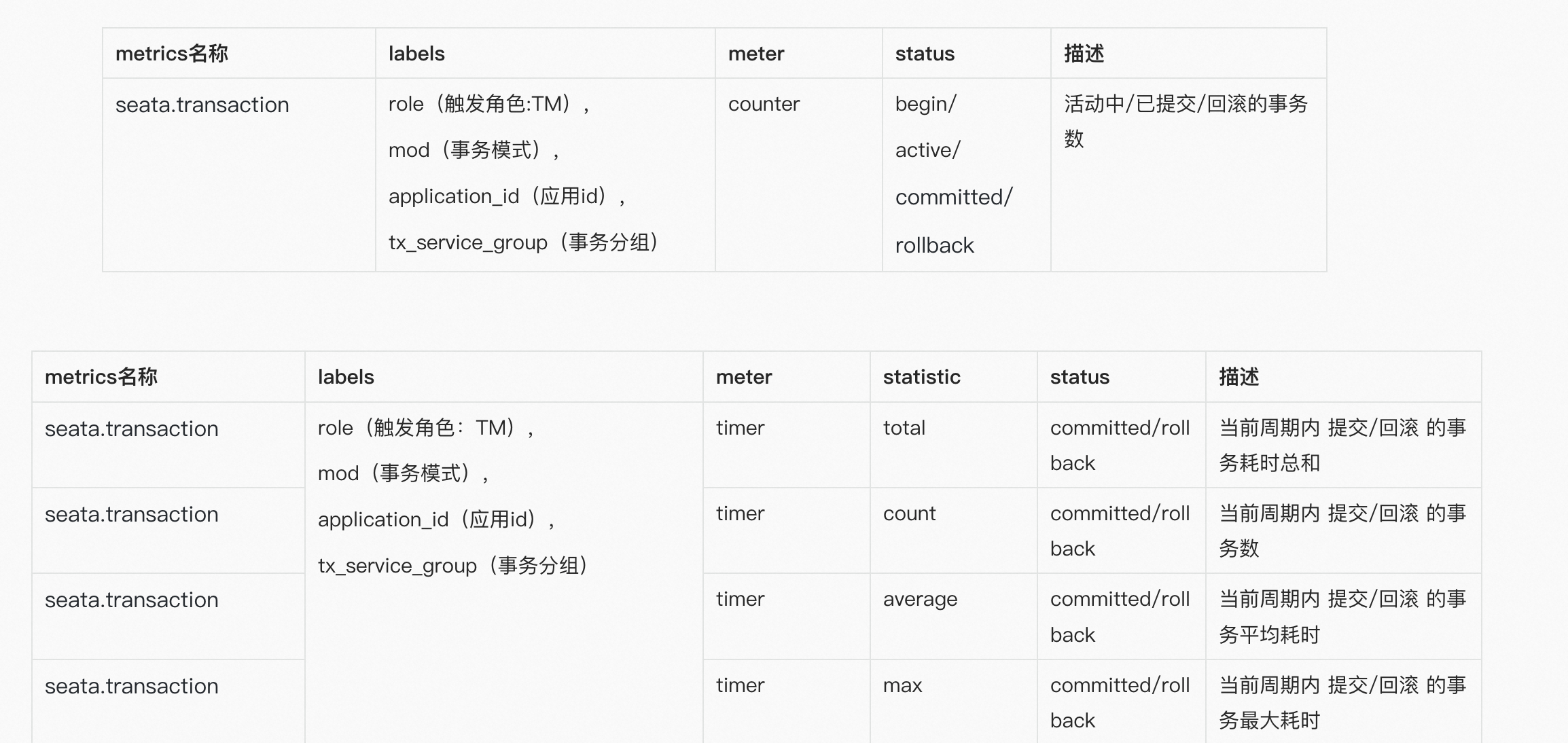
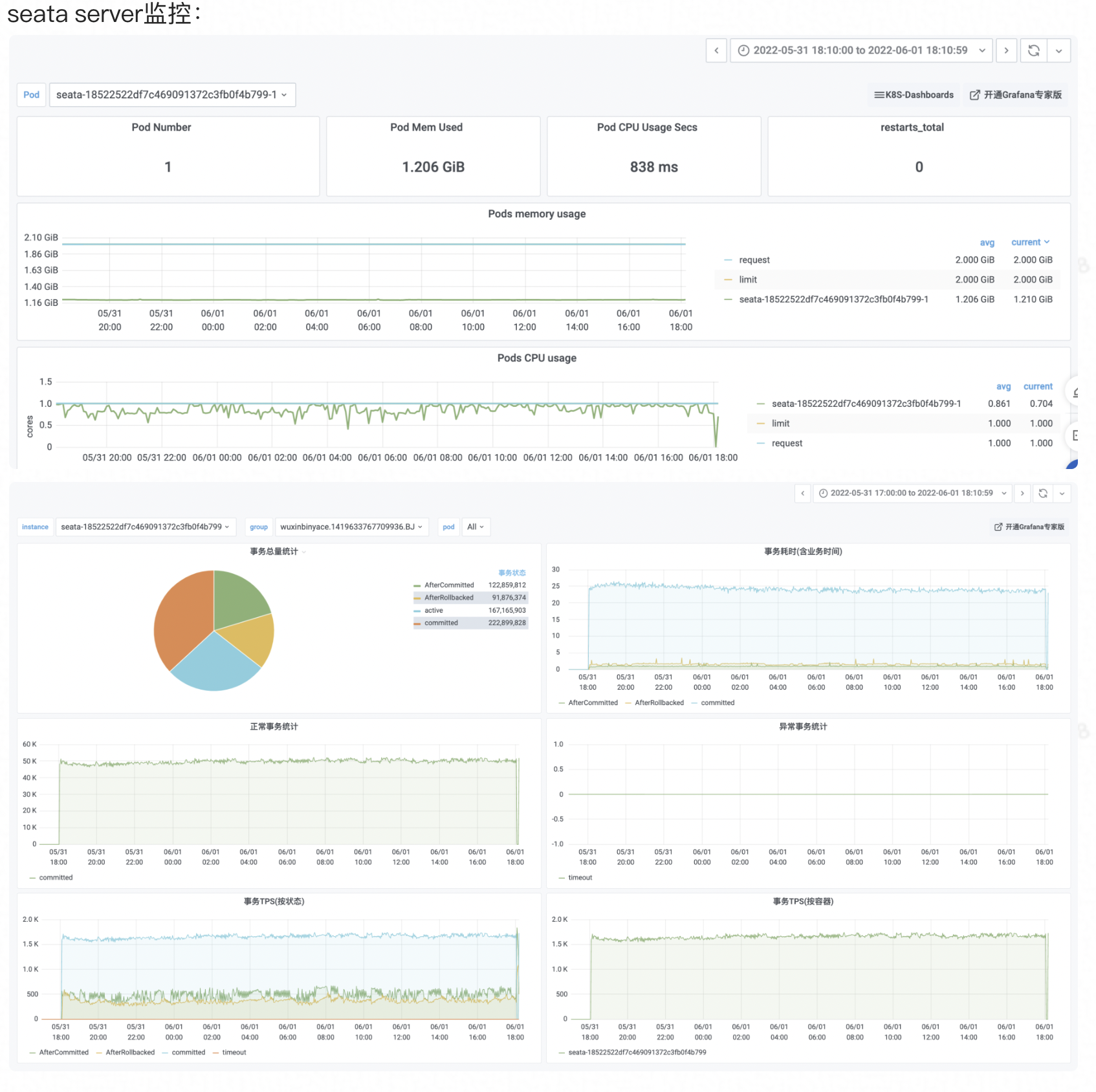
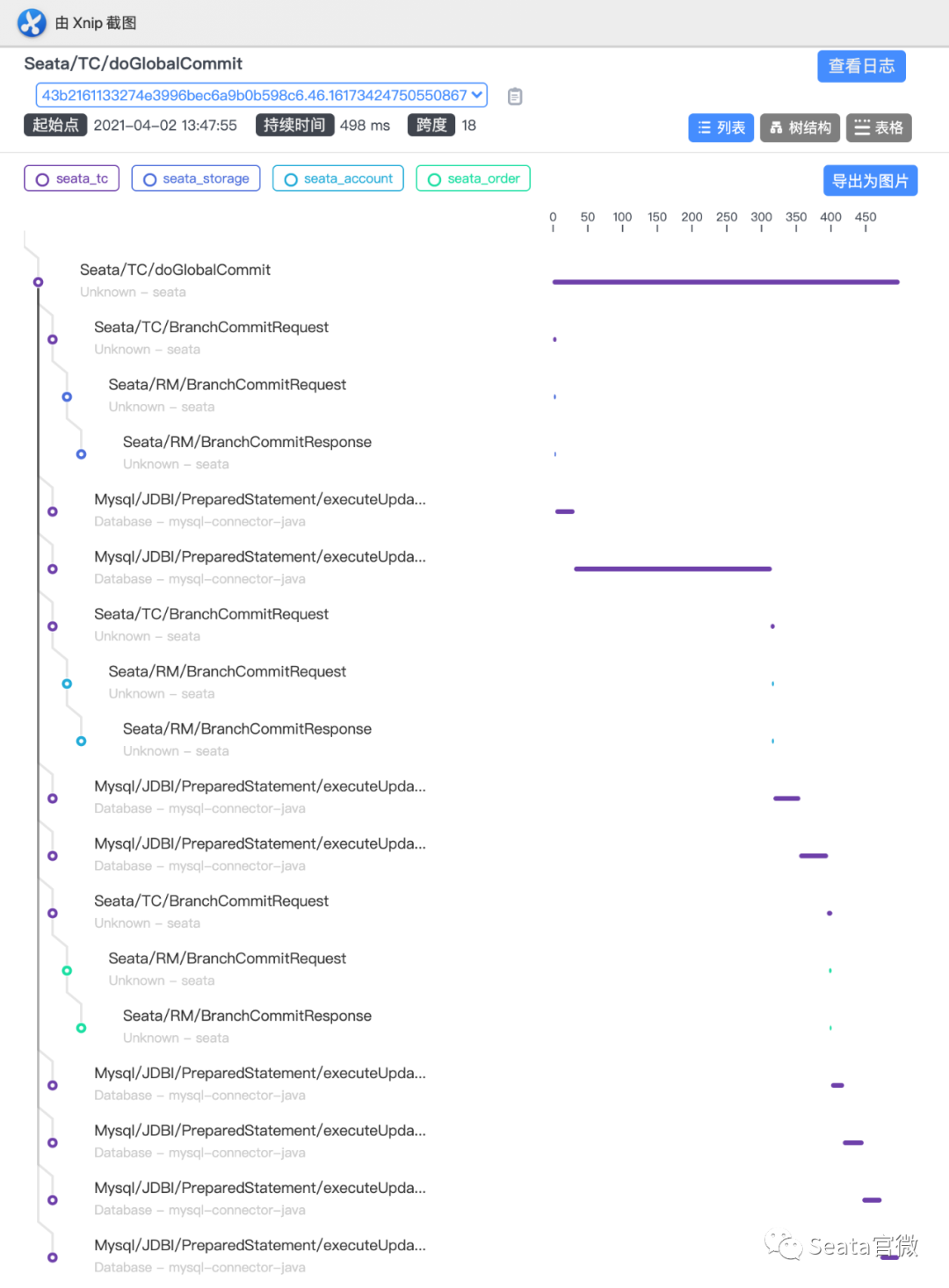
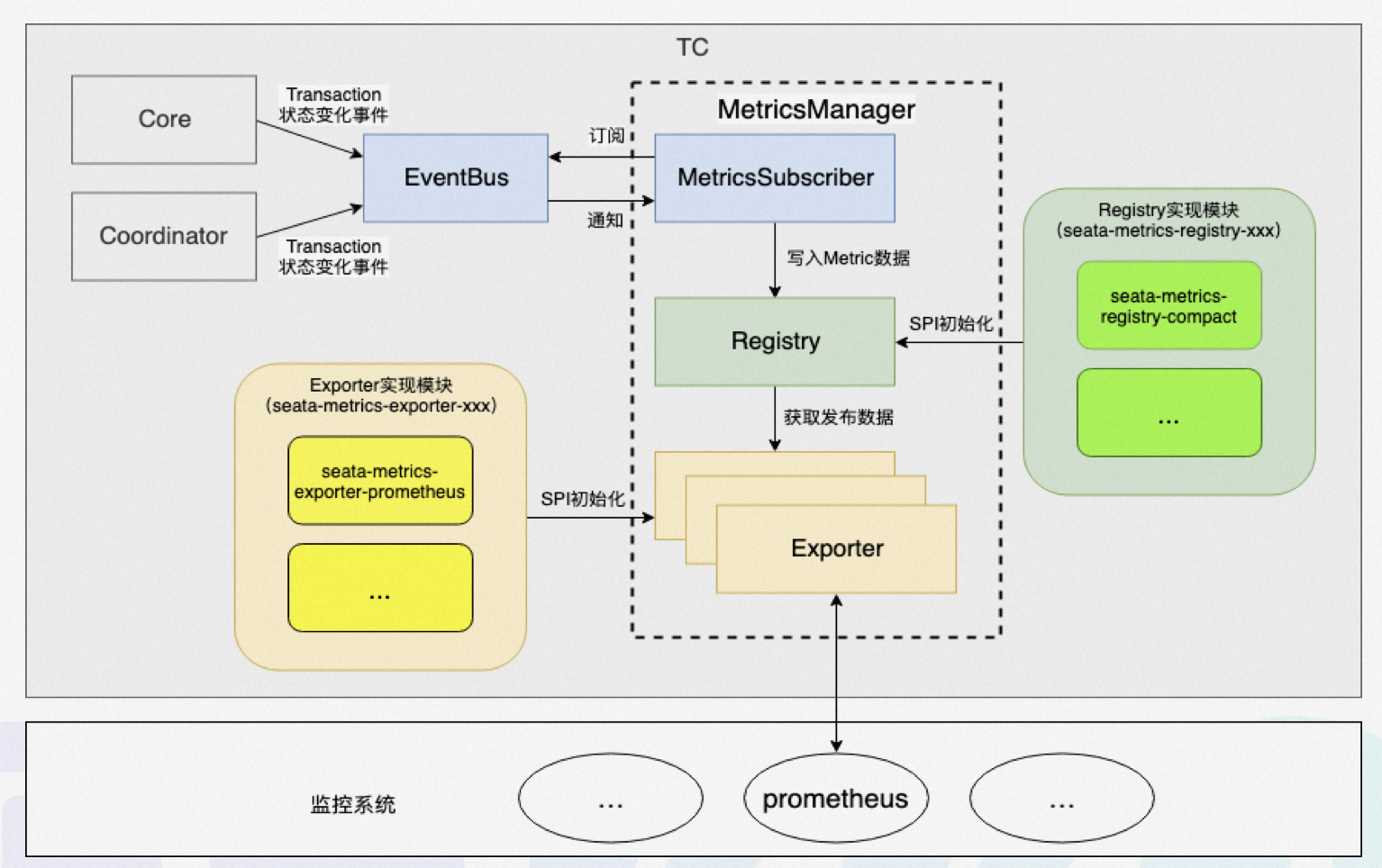 上图是metrics模块的工作流,其工作流程如下:
上图是metrics模块的工作流,其工作流程如下:


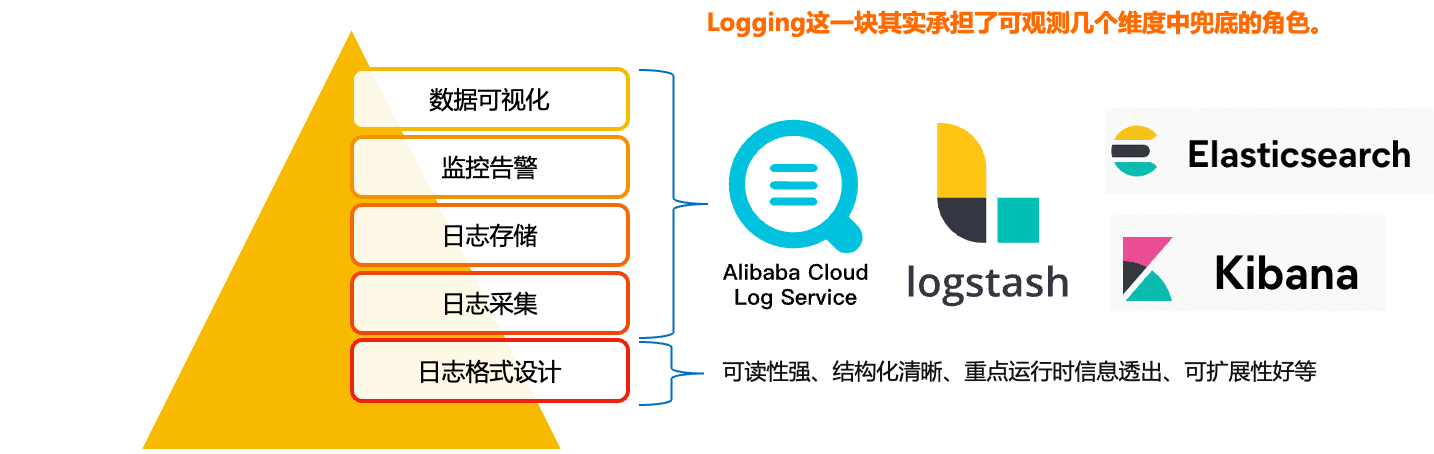 Logging这一块其实承担的是可观测这几个维度当中的兜底角色。放在最底层的,其实就是我们日志格式的设计,只有好日志格式,我们才能对它进行更好的采集、模块化的存储和展示。在其之上,是日志的采集、存储、监控、告警、数据可视化,这些模块更多的是有现成的工具,比如阿里的SLS日志服务、还有ELK的一套技术栈,我们更多是将开销成本、接入复杂度、生态繁荣度等作为考量。
Logging这一块其实承担的是可观测这几个维度当中的兜底角色。放在最底层的,其实就是我们日志格式的设计,只有好日志格式,我们才能对它进行更好的采集、模块化的存储和展示。在其之上,是日志的采集、存储、监控、告警、数据可视化,这些模块更多的是有现成的工具,比如阿里的SLS日志服务、还有ELK的一套技术栈,我们更多是将开销成本、接入复杂度、生态繁荣度等作为考量。